3DGS-Avatar: Animatable Avatars via Deformable 3D Gaussian Splatting

0
Sign in to get full access
Overview
- This paper introduces 3DGS-Avatar, a system for creating animatable avatars by deforming 3D Gaussian splatats.
- The system uses a neural network to generate a 3D representation of the human body and clothing that can be realistically animated.
- Key innovations include a neural network architecture that can model both rigid and deformable body parts, and a rendering approach based on 3D Gaussian splatats.
Plain English Explanation
The research paper describes a new way to create animated digital avatars, which are 3D virtual representations of people. Current avatar systems often struggle to realistically portray the movement and appearance of clothing and other deformable elements.
The 3DGS-Avatar approach solves this by using a special type of 3D data representation called Gaussian splatats. These splatats allow the avatar to accurately model both rigid body parts like the limbs, and softer, more deformable elements like clothing. A neural network is trained to generate these 3D splatats in a way that enables smooth, natural animation of the avatar.
The key advantage of this system is that it can create avatars that move and deform realistically, even for complex clothing and accessories. This could enable more lifelike virtual characters in games, movies, and other applications. The research demonstrates the effectiveness of the 3DGS-Avatar approach through experiments and comparisons to other avatar generation methods.
Technical Explanation
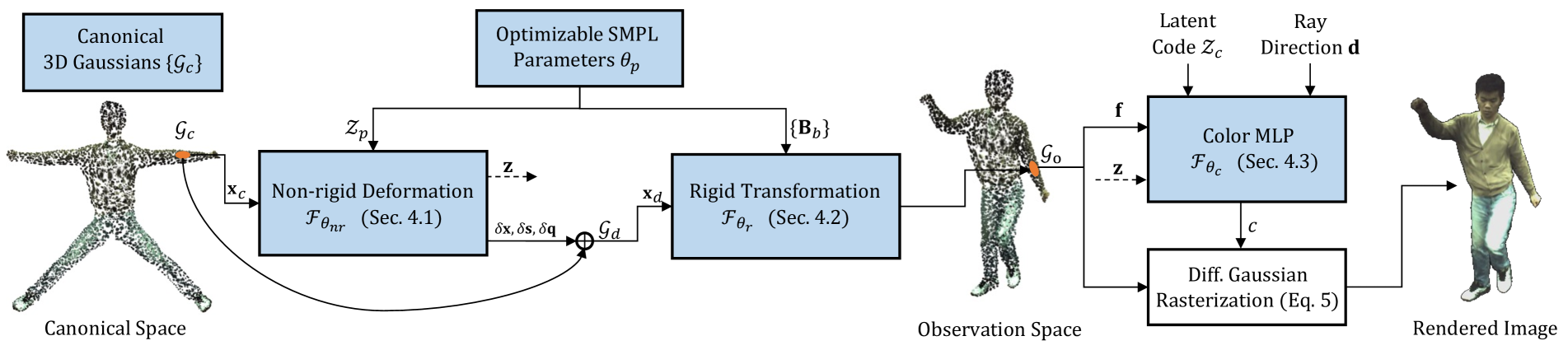
The 3DGS-Avatar system takes as input a set of posed 3D body scans and uses a neural network to generate a 3D representation of the human body and clothing in the form of deformable Gaussian splatats. The network is trained on a large dataset of 3D scans to learn how to model both the rigid body structure and the deformable clothing.
The key innovations include:
- A neural network architecture that can jointly predict the positions, sizes, and deformations of the 3D Gaussian splatats to capture both rigid and deformable body parts.
- A rendering approach based on the 3D splatats that allows for efficient and high-quality animation of the avatar.
- Techniques for training the network to generate plausible, high-fidelity 3D avatars from sparse input data.
Through extensive experiments, the authors demonstrate that 3DGS-Avatar outperforms prior state-of-the-art methods in terms of realism and animation quality of the generated avatars. The system is shown to be robust to variations in body shape, clothing, and motion.
Critical Analysis
The 3DGS-Avatar paper presents a compelling approach for creating highly realistic and animatable digital avatars. The use of 3D Gaussian splatats is a clever solution to the challenge of modeling both rigid and deformable elements of the human form.
One potential limitation is that the system currently relies on a dataset of 3D body scans, which may not be readily available in all use cases. It would be interesting to see if the approach could be extended to work with more readily available 2D image or video data.
Additionally, while the paper demonstrates the effectiveness of the 3DGS-Avatar system, it does not provide extensive discussion of potential applications or societal implications of this technology. As avatar systems become more advanced, there may be concerns around privacy, identity, and the potential for misuse that warrant further exploration.
Overall, the 3DGS-Avatar research represents an important advance in avatar generation and opens up interesting avenues for future work in this domain.
Conclusion
The 3DGS-Avatar paper presents a novel approach for creating highly realistic and animatable digital avatars. By using a neural network to generate deformable 3D Gaussian splatats, the system is able to accurately model both the rigid structure of the human body and the dynamic behavior of clothing and other soft elements.
This innovation in avatar generation could have significant implications for a variety of applications, such as virtual reality, gaming, and digital entertainment. As avatar systems continue to improve, they may also raise important societal questions around privacy, identity, and the ethical use of this technology.
Overall, the 3DGS-Avatar research represents an important step forward in the field of avatar generation and suggests promising directions for future work in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
3DGS-Avatar: Animatable Avatars via Deformable 3D Gaussian Splatting
Zhiyin Qian, Shaofei Wang, Marko Mihajlovic, Andreas Geiger, Siyu Tang
We introduce an approach that creates animatable human avatars from monocular videos using 3D Gaussian Splatting (3DGS). Existing methods based on neural radiance fields (NeRFs) achieve high-quality novel-view/novel-pose image synthesis but often require days of training, and are extremely slow at inference time. Recently, the community has explored fast grid structures for efficient training of clothed avatars. Albeit being extremely fast at training, these methods can barely achieve an interactive rendering frame rate with around 15 FPS. In this paper, we use 3D Gaussian Splatting and learn a non-rigid deformation network to reconstruct animatable clothed human avatars that can be trained within 30 minutes and rendered at real-time frame rates (50+ FPS). Given the explicit nature of our representation, we further introduce as-isometric-as-possible regularizations on both the Gaussian mean vectors and the covariance matrices, enhancing the generalization of our model on highly articulated unseen poses. Experimental results show that our method achieves comparable and even better performance compared to state-of-the-art approaches on animatable avatar creation from a monocular input, while being 400x and 250x faster in training and inference, respectively.
Read more4/5/2024
✨
0
GAvatar: Animatable 3D Gaussian Avatars with Implicit Mesh Learning
Ye Yuan, Xueting Li, Yangyi Huang, Shalini De Mello, Koki Nagano, Jan Kautz, Umar Iqbal
Gaussian splatting has emerged as a powerful 3D representation that harnesses the advantages of both explicit (mesh) and implicit (NeRF) 3D representations. In this paper, we seek to leverage Gaussian splatting to generate realistic animatable avatars from textual descriptions, addressing the limitations (e.g., flexibility and efficiency) imposed by mesh or NeRF-based representations. However, a naive application of Gaussian splatting cannot generate high-quality animatable avatars and suffers from learning instability; it also cannot capture fine avatar geometries and often leads to degenerate body parts. To tackle these problems, we first propose a primitive-based 3D Gaussian representation where Gaussians are defined inside pose-driven primitives to facilitate animation. Second, to stabilize and amortize the learning of millions of Gaussians, we propose to use neural implicit fields to predict the Gaussian attributes (e.g., colors). Finally, to capture fine avatar geometries and extract detailed meshes, we propose a novel SDF-based implicit mesh learning approach for 3D Gaussians that regularizes the underlying geometries and extracts highly detailed textured meshes. Our proposed method, GAvatar, enables the large-scale generation of diverse animatable avatars using only text prompts. GAvatar significantly surpasses existing methods in terms of both appearance and geometry quality, and achieves extremely fast rendering (100 fps) at 1K resolution.
Read more4/1/2024

0
SG-GS: Photo-realistic Animatable Human Avatars with Semantically-Guided Gaussian Splatting
Haoyu Zhao, Chen Yang, Hao Wang, Xingyue Zhao, Wei Shen
Reconstructing photo-realistic animatable human avatars from monocular videos remains challenging in computer vision and graphics. Recently, methods using 3D Gaussians to represent the human body have emerged, offering faster optimization and real-time rendering. However, due to ignoring the crucial role of human body semantic information which represents the intrinsic structure and connections within the human body, they fail to achieve fine-detail reconstruction of dynamic human avatars. To address this issue, we propose SG-GS, which uses semantics-embedded 3D Gaussians, skeleton-driven rigid deformation, and non-rigid cloth dynamics deformation to create photo-realistic animatable human avatars from monocular videos. We then design a Semantic Human-Body Annotator (SHA) which utilizes SMPL's semantic prior for efficient body part semantic labeling. The generated labels are used to guide the optimization of Gaussian semantic attributes. To address the limited receptive field of point-level MLPs for local features, we also propose a 3D network that integrates geometric and semantic associations for human avatar deformation. We further implement three key strategies to enhance the semantic accuracy of 3D Gaussians and rendering quality: semantic projection with 2D regularization, semantic-guided density regularization and semantic-aware regularization with neighborhood consistency. Extensive experiments demonstrate that SG-GS achieves state-of-the-art geometry and appearance reconstruction performance.
Read more8/20/2024

0
HeadGaS: Real-Time Animatable Head Avatars via 3D Gaussian Splatting
Helisa Dhamo, Yinyu Nie, Arthur Moreau, Jifei Song, Richard Shaw, Yiren Zhou, Eduardo P'erez-Pellitero
3D head animation has seen major quality and runtime improvements over the last few years, particularly empowered by the advances in differentiable rendering and neural radiance fields. Real-time rendering is a highly desirable goal for real-world applications. We propose HeadGaS, a model that uses 3D Gaussian Splats (3DGS) for 3D head reconstruction and animation. In this paper we introduce a hybrid model that extends the explicit 3DGS representation with a base of learnable latent features, which can be linearly blended with low-dimensional parameters from parametric head models to obtain expression-dependent color and opacity values. We demonstrate that HeadGaS delivers state-of-the-art results in real-time inference frame rates, surpassing baselines by up to 2dB, while accelerating rendering speed by over x10.
Read more8/14/2024