Advanced Detection of Source Code Clones via an Ensemble of Unsupervised Similarity Measures

0
🔎
Sign in to get full access
Overview
- This paper presents an advanced method for detecting source code clones using an ensemble of unsupervised similarity measures.
- The researchers developed a novel approach that combines multiple similarity metrics to effectively identify duplicate code segments within large software systems.
- The proposed technique leverages the complementary strengths of various unsupervised similarity measures to improve the accuracy and robustness of code clone detection.
Plain English Explanation
When developers write software, they often reuse portions of code from previous projects or even within the same codebase. These reused code segments, known as "clones," can be difficult to identify, especially in large and complex software systems. The researchers behind this paper recognized the importance of accurately detecting code clones, as they can impact software quality, maintainability, and security.
To address this challenge, the researchers developed an ensemble-based approach that combines multiple unsupervised similarity measures. Instead of relying on a single metric, the method leverages the strengths of various techniques, such as comparing the abstract syntax trees of code snippets and analyzing the semantic similarities between code fragments. By considering multiple perspectives, the ensemble method can more accurately identify code clones, even in cases where a single similarity measure might not be effective.
The researchers tested their approach on a range of software projects and found that it outperformed existing state-of-the-art code clone detection techniques. This suggests that the ensemble of unsupervised similarity measures can be a valuable tool for developers and researchers working on improving the security and maintainability of software systems.
Technical Explanation
The researchers developed an ensemble-based approach to code clone detection that combines multiple unsupervised similarity measures. The core idea is to leverage the complementary strengths of various similarity metrics to achieve more robust and accurate identification of duplicate code segments.
The ensemble method involves the following key steps:
- Feature Extraction: The researchers extracted a set of features from the source code, including abstract syntax tree (AST) representations, token-level information, and semantic similarities.
- Similarity Calculation: Multiple unsupervised similarity measures were applied to the extracted features, such as tree-based comparison, token-based comparison, and semantic similarity analysis.
- Ensemble Integration: The individual similarity scores were combined using an ensemble approach, such as majority voting or weighted averaging, to produce a final similarity score for each code pair.
- Clone Detection: The final similarity scores were used to identify code clones, with pairs exceeding a certain similarity threshold considered as clones.
The researchers evaluated their ensemble-based approach on several benchmark datasets and compared its performance to state-of-the-art code clone detection techniques. The results showed that the ensemble method outperformed the individual similarity measures and other existing approaches in terms of precision, recall, and F-measure.
Critical Analysis
The researchers have presented a promising approach to code clone detection that leverages the strengths of multiple unsupervised similarity measures. By combining various techniques, the ensemble method can capture different aspects of code similarity, leading to more robust and accurate clone identification.
However, the paper does not provide a comprehensive analysis of the limitations and potential drawbacks of the proposed method. For example, the computational complexity of the ensemble approach and its scalability to large-scale software projects could be further discussed. Additionally, the researchers could explore the sensitivity of the method to parameter tuning and the impact of feature selection on the overall performance.
It would also be valuable to investigate the generalizability of the ensemble approach to different programming languages and code styles, as the effectiveness of the individual similarity measures may vary across different contexts. Further research could explore the integration of supervised learning techniques or the incorporation of additional code features to enhance the performance of the clone detection system.
Conclusion
This paper presents an advanced technique for detecting source code clones by leveraging an ensemble of unsupervised similarity measures. The proposed approach combines the strengths of various similarity metrics, including tree-based, token-based, and semantic-based comparisons, to provide more accurate and robust identification of duplicate code segments.
The researchers have demonstrated the effectiveness of their ensemble method through extensive evaluations on benchmark datasets, where it outperformed state-of-the-art code clone detection techniques. This suggests that the ensemble-based approach can be a valuable tool for developers and researchers working on improving the quality, maintainability, and security of software systems.
The research in this paper contributes to the ongoing efforts to develop advanced code clone detection techniques and highlights the potential benefits of combining multiple complementary similarity measures for this task. As software systems continue to grow in complexity, tools like the one proposed in this paper will become increasingly important for managing and ensuring the integrity of large-scale codebases.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
0
Advanced Detection of Source Code Clones via an Ensemble of Unsupervised Similarity Measures
Jorge Martinez-Gil
The capability of accurately determining code similarity is crucial in many tasks related to software development. For example, it might be essential to identify code duplicates for performing software maintenance. This research introduces a novel ensemble learning approach for code similarity assessment, combining the strengths of multiple unsupervised similarity measures. The key idea is that the strengths of a diverse set of similarity measures can complement each other and mitigate individual weaknesses, leading to improved performance. Preliminary results show that while Transformers-based CodeBERT and its variant GraphCodeBERT are undoubtedly the best option in the presence of abundant training data, in the case of specific small datasets (up to 500 samples), our ensemble achieves similar results, without prejudice to the interpretability of the resulting solution, and with a much lower associated carbon footprint due to training. The source code of this novel approach can be downloaded from https://github.com/jorge-martinez-gil/ensemble-codesim.
Read more5/6/2024
🖼️
0
Image Similarity using An Ensemble of Context-Sensitive Models
Zukang Liao, Min Chen
Image similarity has been extensively studied in computer vision. In recent years, machine-learned models have shown their ability to encode more semantics than traditional multivariate metrics. However, in labelling semantic similarity, assigning a numerical score to a pair of images is impractical, making the improvement and comparisons on the task difficult. In this work, we present a more intuitive approach to build and compare image similarity models based on labelled data in the form of A:R vs B:R, i.e., determining if an image A is closer to a reference image R than another image B. We address the challenges of sparse sampling in the image space (R, A, B) and biases in the models trained with context-based data by using an ensemble model. Our testing results show that the ensemble model constructed performs ~5% better than the best individual context-sensitive models. They also performed better than the models that were directly fine-tuned using mixed imagery data as well as existing deep embeddings, e.g., CLIP and DINO. This work demonstrates that context-based labelling and model training can be effective when an appropriate ensemble approach is used to alleviate the limitation due to sparse sampling.
Read more9/11/2024

0
AuthAttLyzer-V2: Unveiling Code Authorship Attribution using Enhanced Ensemble Learning Models & Generating Benchmark Dataset
Bhaskar Joshi, Sepideh HajiHossein Khani, Arash HabibiLashkari
Source Code Authorship Attribution (SCAA) is crucial for software classification because it provides insights into the origin and behavior of software. By accurately identifying the author or group behind a piece of code, experts can better understand the motivations and techniques of developers. In the cybersecurity era, this attribution helps trace the source of malicious software, identify patterns in the code that may indicate specific threat actors or groups, and ultimately enhance threat intelligence and mitigation strategies. This paper presents AuthAttLyzer-V2, a new source code feature extractor for SCAA, focusing on lexical, semantic, syntactic, and N-gram features. Our research explores author identification in C++ by examining 24,000 source code samples from 3,000 authors. Our methodology integrates Random Forest, Gradient Boosting, and XGBoost models, enhanced with SHAP for interpretability. The study demonstrates how ensemble models can effectively discern individual coding styles, offering insights into the unique attributes of code authorship. This approach is pivotal in understanding and interpreting complex patterns in authorship attribution, especially for malware classification.
Read more7/1/2024
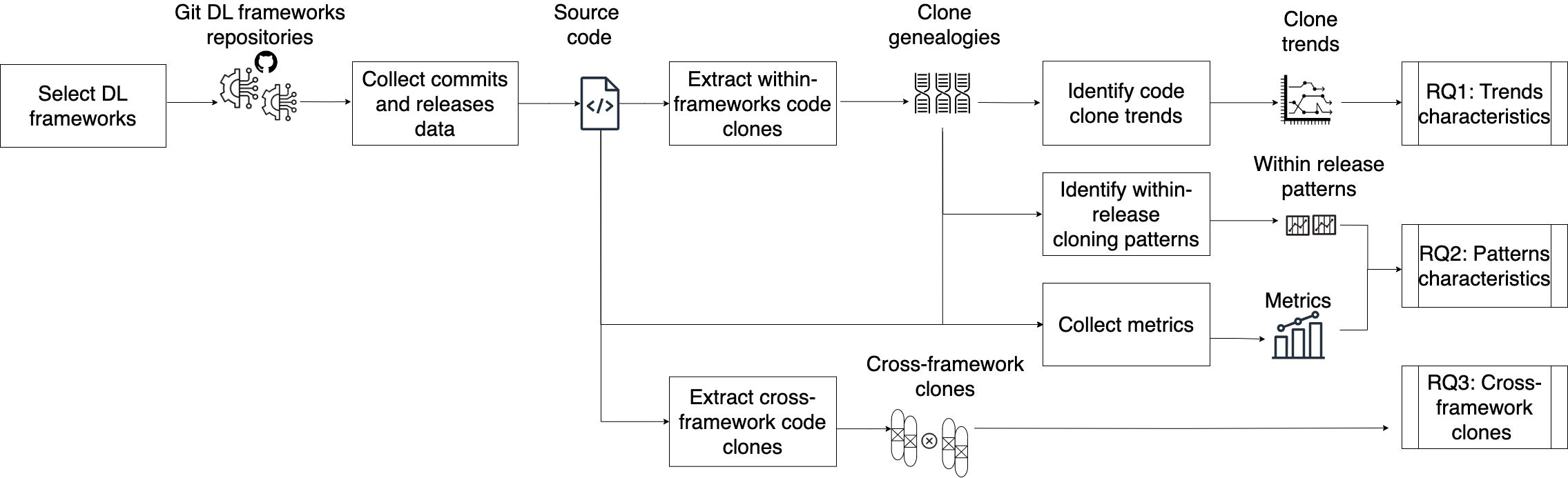
0
Unraveling Code Clone Dynamics in Deep Learning Frameworks
Maram Assi, Safwat Hassan, Ying Zou
Deep Learning (DL) frameworks play a critical role in advancing artificial intelligence, and their rapid growth underscores the need for a comprehensive understanding of software quality and maintainability. DL frameworks, like other systems, are prone to code clones. Code clones refer to identical or highly similar source code fragments within the same project or even across different projects. Code cloning can have positive and negative implications for software development, influencing maintenance, readability, and bug propagation. In this paper, we aim to address the knowledge gap concerning the evolutionary dimension of code clones in DL frameworks and the extent of code reuse across these frameworks. We empirically analyze code clones in nine popular DL frameworks, i.e., TensorFlow, Paddle, PyTorch, Aesara, Ray, MXNet, Keras, Jax and BentoML, to investigate (1) the characteristics of the long-term code cloning evolution over releases in each framework, (2) the short-term, i.e., within-release, code cloning patterns and their influence on the long-term trends, and (3) the file-level code clones within the DL frameworks. Our findings reveal that DL frameworks adopt four distinct cloning trends and that these trends present some common and distinct characteristics. For instance, bug-fixing activities persistently happen in clones irrespective of the clone evolutionary trend but occur more in the Serpentine trend. Moreover, the within release level investigation demonstrates that short-term code cloning practices impact long-term cloning trends. The cross-framework code clone investigation reveals the presence of functional and architectural adaptation file-level cross-framework code clones across the nine studied frameworks. We provide insights that foster robust clone practices and collaborative maintenance in the development of DL frameworks.
Read more4/29/2024