Beyond the Black Box: A Statistical Model for LLM Reasoning and Inference

97
📈
Sign in to get full access
Overview
- This paper introduces a novel Bayesian learning model to explain the behavior of Large Language Models (LLMs).
- The focus is on LLMs' core optimization metric of next token prediction.
- The paper develops a theoretical framework based on an ideal generative text model represented by a multinomial transition probability matrix with a prior.
- It examines how LLMs approximate this matrix.
Plain English Explanation
The paper proposes a new way of understanding how Large Language Models (LLMs) work, particularly their ability to predict the next word in a sequence of text.
The researchers created a mathematical model that represents an "ideal" text generator, with a set of probabilities for transitioning between different words. They then looked at how LLMs try to approximate this ideal model.
Key findings include:
- A mathematical proof showing the connection between word embeddings and these probability distributions
- Demonstration that the way LLMs generate text aligns with principles of Bayesian learning
- An explanation for how larger LLMs are able to learn new information on the fly, a phenomenon known as in-context learning
- Visualizations of how an LLM (specifically Llama) calculates the probabilities of different words occurring next
Overall, this framework provides new insights into how LLMs work and their capabilities and limitations. The researchers suggest it could help guide the design, training, and application of future LLMs.
Technical Explanation
The paper develops a Bayesian learning model to explain the behavior of Large Language Models (LLMs), focusing on their core optimization metric of next token prediction.
The researchers create a theoretical framework based on an "ideal" generative text model represented by a multinomial transition probability matrix with a prior. They then examine how LLMs approximate this matrix.
Key contributions include:
-
A continuity theorem relating word embeddings to multinomial distributions, demonstrating a mathematical connection between these two representations.
-
A demonstration that the way LLMs generate text aligns with principles of Bayesian learning, where the models are updating their beliefs about word probabilities based on the text they observe.
-
An explanation for the emergence of in-context learning in larger LLMs, where the models can quickly adapt to new information.
-
Empirical validation using visualizations of next token probabilities from an instrumented Llama model.
Critical Analysis
The paper provides a novel theoretical framework for understanding LLM behavior, with several interesting insights. However, there are a few potential limitations and areas for further research:
-
The model assumes an "ideal" generative text model, which may not fully capture the complexity of real-world text generation. Validating the model's assumptions against large-scale text corpora could be an area for future work.
-
The empirical analysis is limited to a single LLM (Llama). Expanding the evaluation to a wider range of models, including different architecture types, could help strengthen the generalizability of the findings.
-
The paper does not address potential biases or safety concerns associated with LLMs. Exploring how this Bayesian framework could inform efforts to make LLMs more robust and aligned with human values could be an important direction for future research.
Overall, the paper offers a promising statistical foundation for understanding LLM capabilities and limitations, which could guide future developments in large language model design and application.
Conclusion
This paper introduces a novel Bayesian learning model to explain the behavior of Large Language Models (LLMs), with a focus on their core optimization metric of next token prediction. The researchers develop a theoretical framework based on an ideal generative text model and examine how LLMs approximate this model.
The key contributions include a mathematical connection between word embeddings and multinomial distributions, a demonstration of Bayesian learning principles in LLM text generation, an explanation for in-context learning, and empirical validation using an instrumented Llama model.
This framework provides new insights into LLM functioning, offering a statistical foundation for understanding their capabilities and limitations. The researchers suggest this work could help guide future developments in LLM design, training, and application, potentially leading to more robust and capable language models that are better aligned with human values.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
97
New!Beyond the Black Box: A Statistical Model for LLM Reasoning and Inference
Siddhartha Dalal, Vishal Misra
This paper introduces a novel Bayesian learning model to explain the behavior of Large Language Models (LLMs), focusing on their core optimization metric of next token prediction. We develop a theoretical framework based on an ideal generative text model represented by a multinomial transition probability matrix with a prior, and examine how LLMs approximate this matrix. Key contributions include: (i) a continuity theorem relating embeddings to multinomial distributions, (ii) a demonstration that LLM text generation aligns with Bayesian learning principles, (iii) an explanation for the emergence of in-context learning in larger models, (iv) empirical validation using visualizations of next token probabilities from an instrumented Llama model Our findings provide new insights into LLM functioning, offering a statistical foundation for understanding their capabilities and limitations. This framework has implications for LLM design, training, and application, potentially guiding future developments in the field.
Read more9/25/2024
0
Probabilistic Reasoning in Generative Large Language Models
Aliakbar Nafar, Kristen Brent Venable, Parisa Kordjamshidi
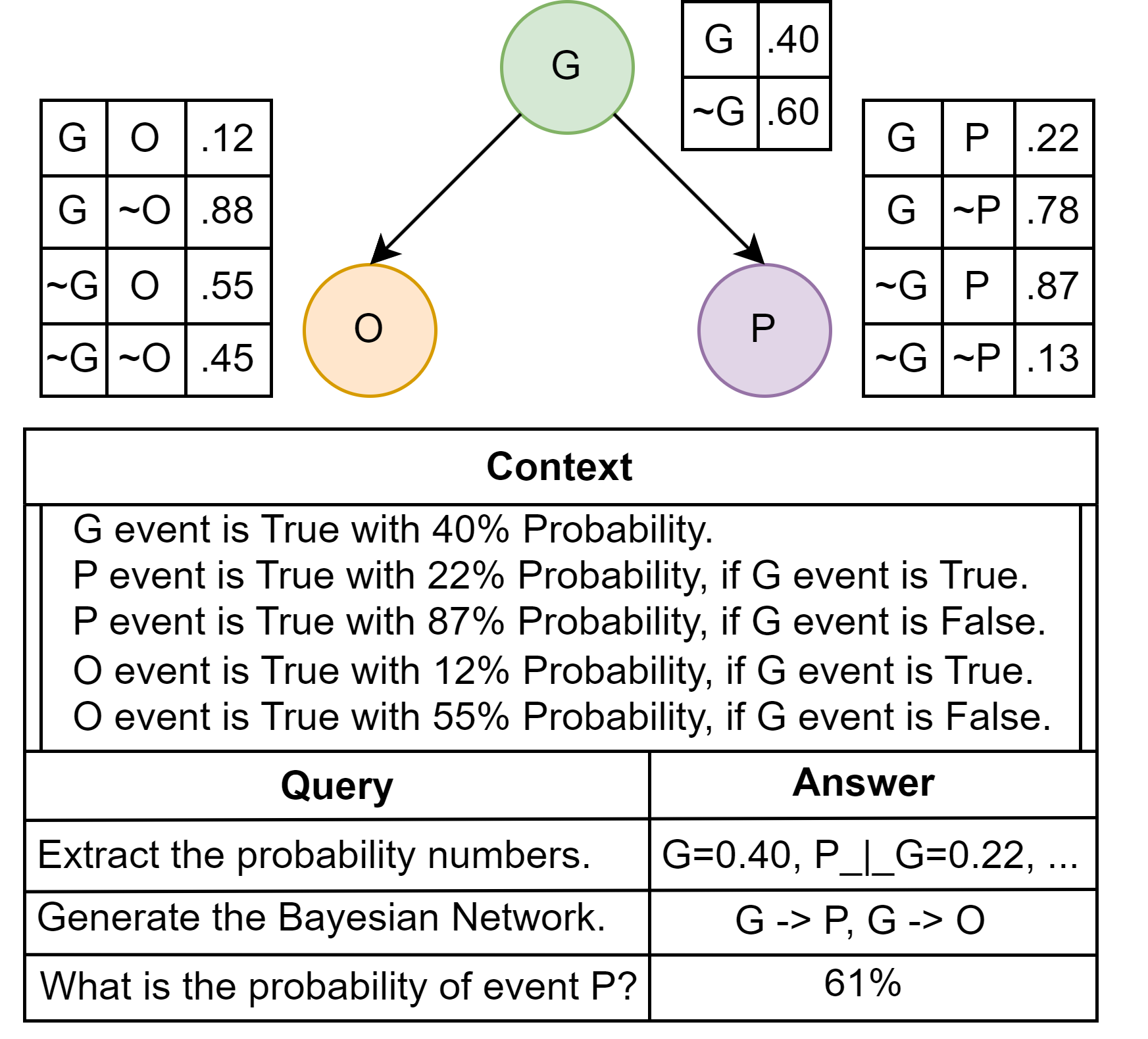
This paper considers the challenges Large Language Models (LLMs) face when reasoning over text that includes information involving uncertainty explicitly quantified via probability values. This type of reasoning is relevant to a variety of contexts ranging from everyday conversations to medical decision-making. Despite improvements in the mathematical reasoning capabilities of LLMs, they still exhibit significant difficulties when it comes to probabilistic reasoning. To deal with this problem, we introduce the Bayesian Linguistic Inference Dataset (BLInD), a new dataset specifically designed to test the probabilistic reasoning capabilities of LLMs. We use BLInD to find out the limitations of LLMs for tasks involving probabilistic reasoning. In addition, we present several prompting strategies that map the problem to different formal representations, including Python code, probabilistic algorithms, and probabilistic logical programming. We conclude by providing an evaluation of our methods on BLInD and an adaptation of a causal reasoning question-answering dataset. Our empirical results highlight the effectiveness of our proposed strategies for multiple LLMs.
Read more6/18/2024

0
LLMExplainer: Large Language Model based Bayesian Inference for Graph Explanation Generation
Jiaxing Zhang, Jiayi Liu, Dongsheng Luo, Jennifer Neville, Hua Wei
Recent studies seek to provide Graph Neural Network (GNN) interpretability via multiple unsupervised learning models. Due to the scarcity of datasets, current methods easily suffer from learning bias. To solve this problem, we embed a Large Language Model (LLM) as knowledge into the GNN explanation network to avoid the learning bias problem. We inject LLM as a Bayesian Inference (BI) module to mitigate learning bias. The efficacy of the BI module has been proven both theoretically and experimentally. We conduct experiments on both synthetic and real-world datasets. The innovation of our work lies in two parts: 1. We provide a novel view of the possibility of an LLM functioning as a Bayesian inference to improve the performance of existing algorithms; 2. We are the first to discuss the learning bias issues in the GNN explanation problem.
Read more7/24/2024
🤿
0
Bayesian Statistical Modeling with Predictors from LLMs
Michael Franke, Polina Tsvilodub, Fausto Carcassi
State of the art large language models (LLMs) have shown impressive performance on a variety of benchmark tasks and are increasingly used as components in larger applications, where LLM-based predictions serve as proxies for human judgements or decision. This raises questions about the human-likeness of LLM-derived information, alignment with human intuition, and whether LLMs could possibly be considered (parts of) explanatory models of (aspects of) human cognition or language use. To shed more light on these issues, we here investigate the human-likeness of LLMs' predictions for multiple-choice decision tasks from the perspective of Bayesian statistical modeling. Using human data from a forced-choice experiment on pragmatic language use, we find that LLMs do not capture the variance in the human data at the item-level. We suggest different ways of deriving full distributional predictions from LLMs for aggregate, condition-level data, and find that some, but not all ways of obtaining condition-level predictions yield adequate fits to human data. These results suggests that assessment of LLM performance depends strongly on seemingly subtle choices in methodology, and that LLMs are at best predictors of human behavior at the aggregate, condition-level, for which they are, however, not designed to, or usually used to, make predictions in the first place.
Read more6/14/2024