Can Go AIs be adversarially robust?

0
🤿
Sign in to get full access
Overview
- Previous research has shown that superhuman Go AI systems like KataGo can be defeated by simple adversarial strategies.
- This paper examines whether simple defenses can improve KataGo's performance against the worst-case scenarios.
- The paper tests three natural defenses: adversarial training on hand-constructed positions, iterated adversarial training, and changing the network architecture.
Plain English Explanation
The researchers wanted to see if they could make the powerful Go AI system KataGo more robust against sneaky tactics that could defeat it. They tried three different approaches to defend KataGo:
- Training it on carefully crafted board positions that could trick it, to help it learn to avoid those traps.
- Repeatedly training it on new adversarial examples to make it better at handling them.
- Changing the underlying neural network architecture of KataGo to see if that could help.
The good news is that some of these defenses did help protect KataGo against the previously discovered attacks. However, the bad news is that none of them could fully withstand new, more advanced attacks that the researchers were able to develop. These new attacks could still cause KataGo to make mistakes that even human players would not.
The key takeaway is that building truly robust and reliable AI systems is very challenging, even in narrow domains like the game of Go. There's still a lot of work to be done to make AI systems that can reliably handle the worst-case scenarios they might face.
Technical Explanation
The researchers tested three potential defenses against adversarial attacks on the superhuman Go AI system KataGo:
- Adversarial training on hand-constructed positions: They manually created a set of board positions designed to trick KataGo, and then trained the system on those positions to try to make it more robust.
- Iterated adversarial training: They repeatedly trained KataGo on newly generated adversarial examples to continually improve its defenses.
- Changing the network architecture: They modified the underlying neural network structure of KataGo to see if that could enhance its robustness.
The results showed that some of these defenses were effective at protecting KataGo against the previously known attacks. However, the researchers were then able to develop new, more sophisticated adversarial examples that could still reliably cause KataGo to blunder in ways that would be unnatural for human players.
Critical Analysis
The researchers acknowledge the limitations of their work - they were only able to test a small set of potential defenses, and there may be other approaches that could yield better results. Additionally, the attacks they developed were specific to the KataGo system, so it's unclear how well the findings would generalize to other AI models.
Further research is needed to explore a wider range of defense mechanisms and to better understand the fundamental challenges of building truly robust AI systems, even in narrow domains. The fact that KataGo, a state-of-the-art Go player, could still be defeated by carefully crafted adversarial examples suggests that the problem of adversarial robustness is deeply challenging.
Developing effective defenses may require rethinking how AI models are trained and architected, moving beyond just trying to make them more robust to single attacks. The strategic incentives of adversaries and the inherent tension between robustness and other desirable model properties will need to be carefully considered.
Conclusion
This research highlights the significant challenges involved in building AI systems that are truly robust to adversarial attacks, even in narrow domains like the game of Go. While some defenses were able to protect KataGo against previously known attacks, the researchers were ultimately able to develop new adversarial examples that could still reliably defeat the defended models.
The findings suggest that there is still much work to be done to develop reliable and trustworthy AI systems that can withstand the worst-case scenarios they may face. Continued research and innovation will be needed to address this critical challenge and unlock the full potential of AI technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
0
Can Go AIs be adversarially robust?
Tom Tseng, Euan McLean, Kellin Pelrine, Tony T. Wang, Adam Gleave
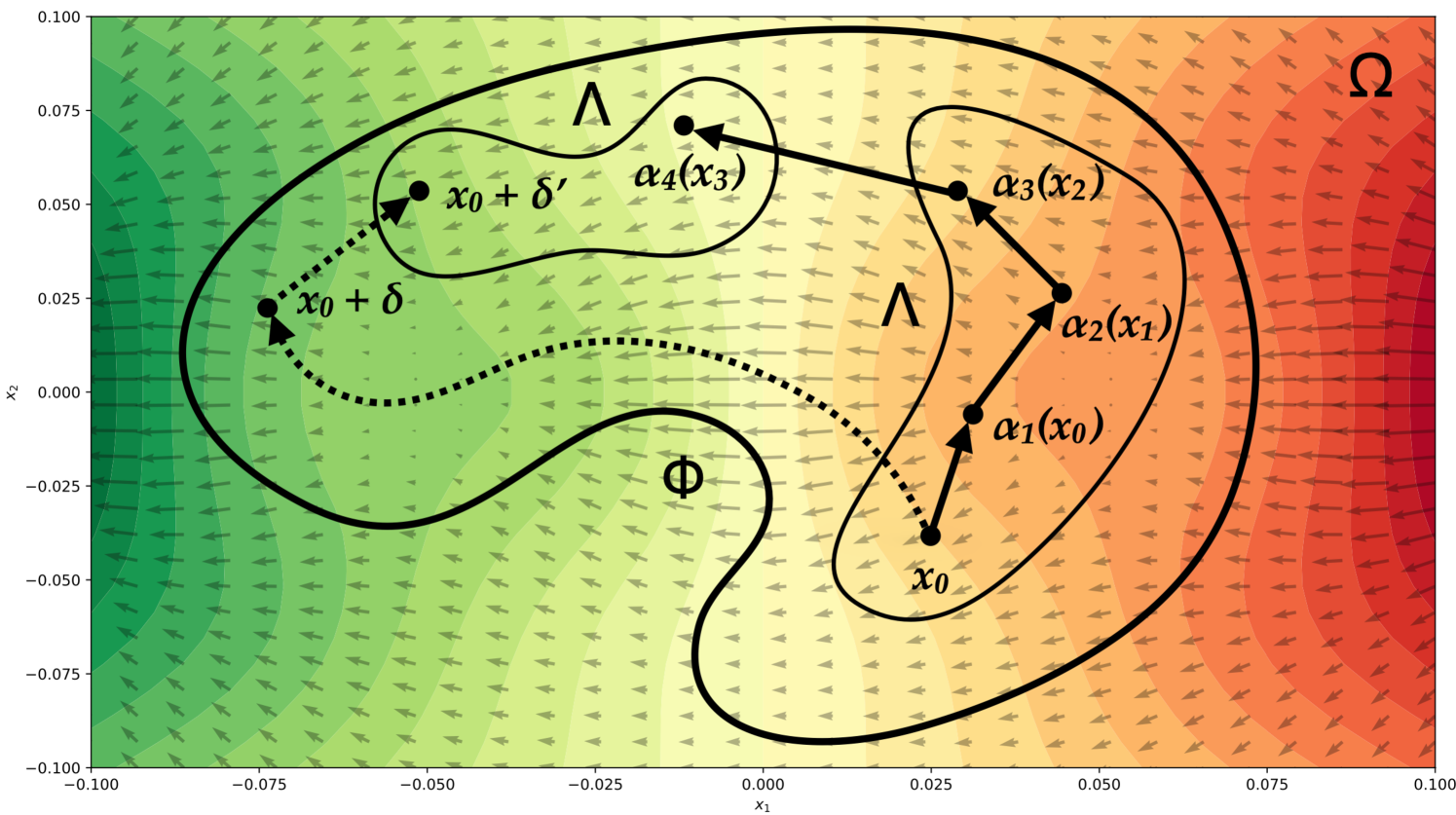
Prior work found that superhuman Go AIs like KataGo can be defeated by simple adversarial strategies. In this paper, we study if simple defenses can improve KataGo's worst-case performance. We test three natural defenses: adversarial training on hand-constructed positions, iterated adversarial training, and changing the network architecture. We find that some of these defenses are able to protect against previously discovered attacks. Unfortunately, we also find that none of these defenses are able to withstand adaptive attacks. In particular, we are able to train new adversaries that reliably defeat our defended agents by causing them to blunder in ways humans would not. Our results suggest that building robust AI systems is challenging even in narrow domains such as Go. For interactive examples of attacks and a link to our codebase, see https://goattack.far.ai.
Read more6/19/2024

0
A Novel Approach to Guard from Adversarial Attacks using Stable Diffusion
Trinath Sai Subhash Reddy Pittala, Uma Maheswara Rao Meleti, Geethakrishna Puligundla
Recent developments in adversarial machine learning have highlighted the importance of building robust AI systems to protect against increasingly sophisticated attacks. While frameworks like AI Guardian are designed to defend against these threats, they often rely on assumptions that can limit their effectiveness. For example, they may assume attacks only come from one direction or include adversarial images in their training data. Our proposal suggests a different approach to the AI Guardian framework. Instead of including adversarial examples in the training process, we propose training the AI system without them. This aims to create a system that is inherently resilient to a wider range of attacks. Our method focuses on a dynamic defense strategy using stable diffusion that learns continuously and models threats comprehensively. We believe this approach can lead to a more generalized and robust defense against adversarial attacks. In this paper, we outline our proposed approach, including the theoretical basis, experimental design, and expected impact on improving AI security against adversarial threats.
Read more5/6/2024

0
Explainable AI Security: Exploring Robustness of Graph Neural Networks to Adversarial Attacks
Tao Wu, Canyixing Cui, Xingping Xian, Shaojie Qiao, Chao Wang, Lin Yuan, Shui Yu
Graph neural networks (GNNs) have achieved tremendous success, but recent studies have shown that GNNs are vulnerable to adversarial attacks, which significantly hinders their use in safety-critical scenarios. Therefore, the design of robust GNNs has attracted increasing attention. However, existing research has mainly been conducted via experimental trial and error, and thus far, there remains a lack of a comprehensive understanding of the vulnerability of GNNs. To address this limitation, we systematically investigate the adversarial robustness of GNNs by considering graph data patterns, model-specific factors, and the transferability of adversarial examples. Through extensive experiments, a set of principled guidelines is obtained for improving the adversarial robustness of GNNs, for example: (i) rather than highly regular graphs, the training graph data with diverse structural patterns is crucial for model robustness, which is consistent with the concept of adversarial training; (ii) the large model capacity of GNNs with sufficient training data has a positive effect on model robustness, and only a small percentage of neurons in GNNs are affected by adversarial attacks; (iii) adversarial transfer is not symmetric and the adversarial examples produced by the small-capacity model have stronger adversarial transferability. This work illuminates the vulnerabilities of GNNs and opens many promising avenues for designing robust GNNs.
Read more6/21/2024
0
How to Train your Antivirus: RL-based Hardening through the Problem-Space
Ilias Tsingenopoulos, Jacopo Cortellazzi, Branislav Bov{s}ansk'y, Simone Aonzo, Davy Preuveneers, Wouter Joosen, Fabio Pierazzi, Lorenzo Cavallaro
ML-based malware detection on dynamic analysis reports is vulnerable to both evasion and spurious correlations. In this work, we investigate a specific ML architecture employed in the pipeline of a widely-known commercial antivirus company, with the goal to harden it against adversarial malware. Adversarial training, the sole defensive technique that can confer empirical robustness, is not applicable out of the box in this domain, for the principal reason that gradient-based perturbations rarely map back to feasible problem-space programs. We introduce a novel Reinforcement Learning approach for constructing adversarial examples, a constituent part of adversarially training a model against evasion. Our approach comes with multiple advantages. It performs modifications that are feasible in the problem-space, and only those; thus it circumvents the inverse mapping problem. It also makes possible to provide theoretical guarantees on the robustness of the model against a particular set of adversarial capabilities. Our empirical exploration validates our theoretical insights, where we can consistently reach 0% Attack Success Rate after a few adversarial retraining iterations.
Read more9/6/2024