CATS: Contextually-Aware Thresholding for Sparsity in Large Language Models

0

Sign in to get full access
Overview
- This paper introduces CATS (Contextually-Aware Thresholding for Sparsity), a novel approach to reducing the computational cost of large language models by selectively pruning less important parameters.
- CATS leverages contextual information to determine which parameters can be pruned without significantly impacting model performance, leading to more efficient and compact models.
- The authors demonstrate the effectiveness of CATS on various large language models, including CATP: Cross-Attention Token Pruning for Accuracy Preserved model compression, LaTTE: Low-Precision Approximate Attention, and Sheared-LLaMA: Accelerating Language Model Pre-Training.
Plain English Explanation
Large language models, like those used in ChatGPT, are incredibly powerful but also computationally expensive to run. This paper introduces a new technique called CATS that can make these models more efficient without significantly reducing their performance.
The key idea behind CATS is to selectively prune, or remove, parts of the model that are less important for a given task or input. This is done by looking at the context of the input and determining which model parameters are most relevant.
For example, if you're asking the model a question about cats, CATS would focus on the parts of the model that deal with cats and prune away the parts that are less relevant, like information about dogs. This allows the model to run faster and use less computational resources, while still maintaining its overall performance.
The authors show that CATS can be applied to various large language models, including some recent advances like CATP, LaTTE, and Sheared-LLaMA, with great results. This suggests that CATS could be a valuable tool for making large language models more practical and accessible, especially in resource-constrained environments.
Technical Explanation
The paper introduces CATS, a novel approach to reducing the computational cost of large language models by selectively pruning model parameters based on their contextual relevance. CATS leverages the insight that not all model parameters are equally important for a given input or task, and that by identifying and pruning the less critical parameters, significant efficiency gains can be achieved without a substantial loss in model performance.
The key components of CATS include:
-
Contextual Importance Estimation: CATS employs a contextualized importance scoring mechanism to quantify the relevance of each model parameter based on the current input and task. This allows the system to identify which parameters are most critical for the given context.
-
Adaptive Thresholding: CATS uses an adaptive thresholding approach to determine the optimal level of pruning, balancing the trade-off between model efficiency and performance. The thresholds are adjusted dynamically based on the input and task, ensuring that the most relevant parameters are retained.
-
Model Fine-Tuning: After pruning the less important parameters, CATS fine-tunes the resulting sparse model to recover any potential performance degradation, further optimizing the model for the target task.
The authors evaluate CATS on a variety of large language models, including CATP, LaTTE, and Sheared-LLaMA, demonstrating significant reductions in model size and inference latency without compromising model performance.
Critical Analysis
The CATS approach presents a promising strategy for improving the efficiency of large language models, but it is important to consider some potential limitations and areas for further research:
-
Generalization Across Tasks: While the authors demonstrate the effectiveness of CATS on various language models and tasks, it would be valuable to investigate how well the approach generalizes across a broader range of applications, especially those with significantly different characteristics or requirements.
-
Interpretability and Explainability: The contextual importance estimation mechanism used by CATS may not be fully transparent, making it challenging to understand the underlying reasons for the pruning decisions. Enhancing the interpretability of the system could help build trust and enable more informed decision-making.
-
Robustness to Adversarial Inputs: It is unclear how CATS would perform in the face of adversarial inputs designed to exploit the selective pruning approach. Evaluating the system's resilience to such adversarial examples would be an important direction for future research.
-
Hardware-Aware Optimization: The paper focuses on model-level optimizations, but further gains in efficiency could potentially be achieved by considering hardware-specific constraints and opportunities, such as leveraging specialized hardware accelerators for sparse computations.
Overall, the CATS approach represents a valuable contribution to the ongoing efforts to make large language models more practical and accessible, particularly in resource-constrained environments. By seamlessly integrating contextual awareness into the pruning process, the authors have demonstrated a promising path towards more efficient and effective language models.
Conclusion
The CATS (Contextually-Aware Thresholding for Sparsity) technique introduced in this paper offers a novel approach to reducing the computational cost of large language models without significantly compromising their performance. By leveraging contextual information to selectively prune less important model parameters, CATS can lead to more efficient and compact models that are better suited for real-world applications.
The authors' evaluation of CATS on various state-of-the-art language models, including CATP, LaTTE, and Sheared-LLaMA, demonstrates the versatility and effectiveness of the approach. As large language models continue to grow in size and complexity, techniques like CATS will be crucial for making these powerful AI systems more practical and accessible, especially in resource-constrained environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
CATS: Contextually-Aware Thresholding for Sparsity in Large Language Models
Je-Yong Lee, Donghyun Lee, Genghan Zhang, Mo Tiwari, Azalia Mirhoseini
Large Language Models (LLMs) have dramatically advanced AI applications, yet their deployment remains challenging due to their immense inference costs. Recent studies ameliorate the computational costs of LLMs by increasing their activation sparsity but suffer from significant performance degradation on downstream tasks. In this work, we introduce a new framework for sparsifying the activations of base LLMs and reducing inference costs, dubbed Contextually Aware Thresholding for Sparsity (CATS). CATS is relatively simple, easy to implement, and highly effective. At the heart of our framework is a new non-linear activation function. We demonstrate that CATS can be applied to various base models, including Mistral-7B and Llama2-7B, and outperforms existing sparsification techniques in downstream task performance. More precisely, CATS-based models often achieve downstream task performance within 1-2% of their base models without any fine-tuning and even at activation sparsity levels of 50%. Furthermore, CATS-based models converge faster and display better task performance than competing techniques when fine-tuning is applied. Finally, we develop a custom GPU kernel for efficient implementation of CATS that translates the activation of sparsity of CATS to real wall-clock time speedups. Our custom kernel implementation of CATS results in a ~15% improvement in wall-clock inference latency of token generation on both Llama-7B and Mistral-7B.
Read more4/30/2024

0
Training-Free Activation Sparsity in Large Language Models
James Liu, Pragaash Ponnusamy, Tianle Cai, Han Guo, Yoon Kim, Ben Athiwaratkun
Activation sparsity can enable practical inference speedups in large language models (LLMs) by reducing the compute and memory-movement required for matrix multiplications during the forward pass. However, existing methods face limitations that inhibit widespread adoption. Some approaches are tailored towards older models with ReLU-based sparsity, while others require extensive continued pre-training on up to hundreds of billions of tokens. This paper describes TEAL, a simple training-free method that applies magnitude-based activation sparsity to hidden states throughout the entire model. TEAL achieves 40-50% model-wide sparsity with minimal performance degradation across Llama-2, Llama-3, and Mistral families, with sizes varying from 7B to 70B. We improve existing sparse kernels and demonstrate wall-clock decoding speed-ups of up to 1.53$times$ and 1.8$times$ at 40% and 50% model-wide sparsity. TEAL is compatible with weight quantization, enabling further efficiency gains.
Read more8/28/2024

0
ShadowLLM: Predictor-based Contextual Sparsity for Large Language Models
Yash Akhauri, Ahmed F AbouElhamayed, Jordan Dotzel, Zhiru Zhang, Alexander M Rush, Safeen Huda, Mohamed S Abdelfattah
The high power consumption and latency-sensitive deployments of large language models (LLMs) have motivated techniques like quantization and sparsity. Contextual sparsity, where the sparsity pattern is input-dependent, is crucial in LLMs because the permanent removal of attention heads or neurons from LLMs can significantly degrade accuracy. Prior work has attempted to model contextual sparsity using neural networks trained to predict activation magnitudes, which can be used to dynamically prune structures with low predicted activation magnitude. In this paper, we look beyond magnitude-based pruning criteria to assess attention head and neuron importance in LLMs. We developed a novel predictor called ShadowLLM, which can shadow the LLM behavior and enforce better sparsity patterns, resulting in over 15% improvement in end-to-end accuracy without increasing latency compared to previous methods. ShadowLLM achieves up to a 20% speed-up over the state-of-the-art DejaVu framework. These enhancements are validated on models with up to 30 billion parameters. Our code is available at href{https://github.com/abdelfattah-lab/shadow_llm/}{ShadowLLM}.
Read more6/26/2024
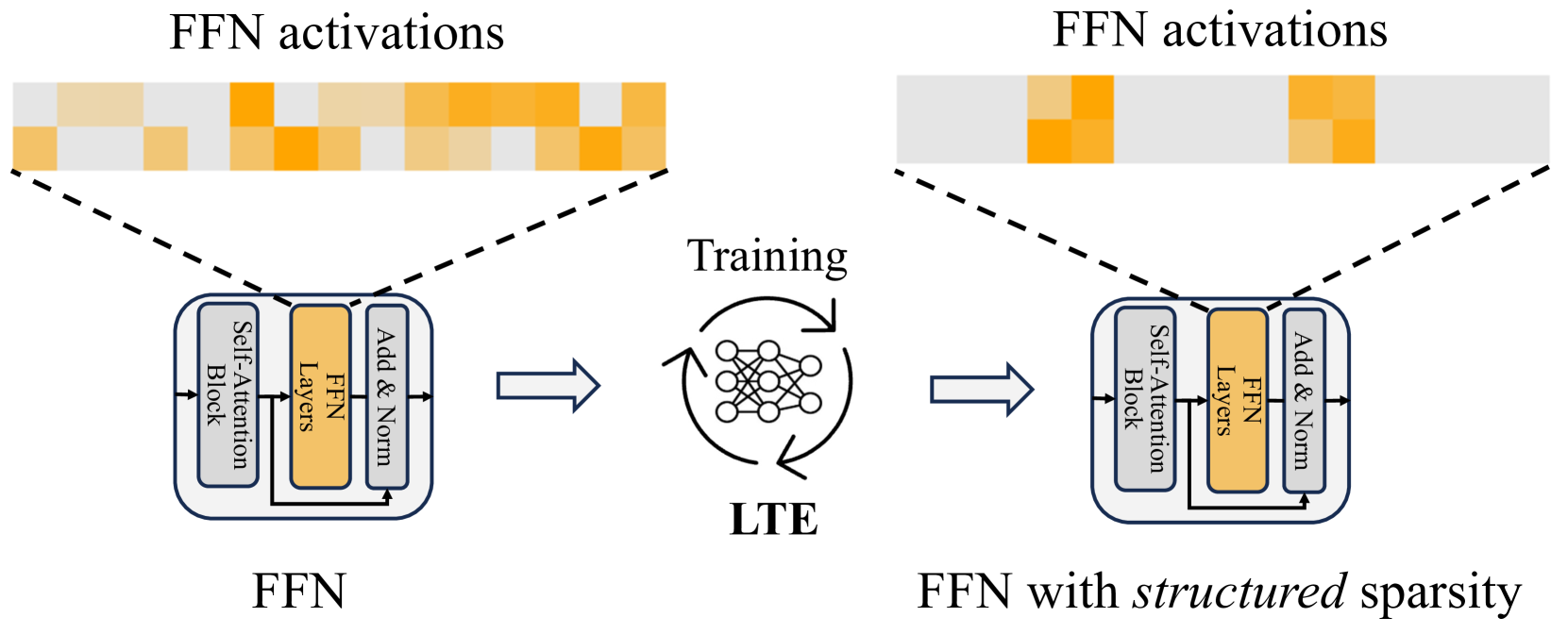
0
Learn To be Efficient: Build Structured Sparsity in Large Language Models
Haizhong Zheng, Xiaoyan Bai, Xueshen Liu, Z. Morley Mao, Beidi Chen, Fan Lai, Atul Prakash
Large Language Models (LLMs) have achieved remarkable success with their billion-level parameters, yet they incur high inference overheads. The emergence of activation sparsity in LLMs provides a natural approach to reduce this cost by involving only parts of the parameters for inference. However, existing methods only focus on utilizing this naturally formed activation sparsity in a post-training setting, overlooking the potential for further amplifying this inherent sparsity. In this paper, we hypothesize that LLMs can learn to be efficient by achieving more structured activation sparsity. To achieve this, we introduce a novel training algorithm, Learn-To-be-Efficient (LTE), designed to train efficiency-aware LLMs to learn to activate fewer neurons and achieve a better trade-off between sparsity and performance. Furthermore, unlike SOTA MoEfication methods, which mainly focus on ReLU-based models, LTE can also be applied to LLMs like LLaMA using non-ReLU activations. Extensive evaluation on language understanding, language generation, and instruction tuning tasks show that LTE consistently outperforms SOTA baselines. Along with our hardware-aware custom kernel implementation, LTE reduces LLaMA2-7B inference latency by 25% at 50% sparsity.
Read more6/5/2024