COMQ: A Backpropagation-Free Algorithm for Post-Training Quantization

0

Sign in to get full access
Overview
- This paper presents COMQ, a novel post-training quantization algorithm that is backpropagation-free.
- Post-training quantization is a technique to compress deep learning models by reducing the precision of their weights and activations without retraining the model.
- COMQ aims to overcome the limitations of existing post-training quantization methods, which often require expensive retraining or hand-crafted hyperparameters.
Plain English Explanation
The paper introduces a new way to make deep learning models more efficient by reducing the amount of memory and computation they require, without having to go through the full training process again. This is done through a technique called post-training quantization, which shrinks the size of the model's internal components (called weights and activations) by representing them with fewer bits of information.
Previous post-training quantization methods have had some drawbacks - they either required expensive retraining of the model, or needed a lot of manual tuning of hyperparameters (settings that control how the quantization process works). The new COMQ algorithm aims to solve these issues by providing a simpler, more automated way to quantize models without needing to retrain them from scratch.
The key idea behind COMQ is that it can find the optimal way to quantize a model by directly analyzing the existing weights and activations, without relying on the complex process of backpropagation that is used during normal model training. This makes the quantization process much faster and easier to apply, while still preserving the model's accuracy.
Technical Explanation
The COMQ algorithm works by first analyzing the statistical distribution of the weights and activations in the pre-trained deep learning model. It then uses this information to determine the optimal number of bits to use when representing each component, in order to minimize the loss in model accuracy.
COMQ does this in a backpropagation-free way, avoiding the need to retrain the entire model from scratch as is required by some other post-training quantization methods like CBQ and OAC. This makes COMQ much faster and more efficient to apply.
The paper demonstrates the effectiveness of COMQ through experiments on a variety of deep learning models and datasets, showing that it can achieve similar or better accuracy compared to other state-of-the-art post-training quantization techniques, but with a simpler and more automated workflow.
Critical Analysis
The COMQ algorithm provides a promising advance in post-training quantization, addressing some key limitations of prior approaches. By avoiding the need for expensive retraining, COMQ makes model compression more accessible and practical.
However, the paper does not explore the limits of COMQ's effectiveness. It would be valuable to understand how COMQ performs on extremely low-precision quantization (e.g. 2-3 bits per parameter), or on more complex models like large language models, which have been the focus of other recent quantization research like ADPQ and QLLM.
Additionally, the paper does not provide much insight into the trade-offs involved in the COMQ quantization process. It would be helpful to understand how COMQ balances factors like model size reduction, inference speed-up, and accuracy preservation.
Conclusion
The COMQ algorithm presented in this paper offers a novel, backpropagation-free approach to post-training quantization of deep learning models. By avoiding the need for expensive retraining, COMQ provides a simpler and more automated way to compress models without sacrificing too much accuracy.
This advance in model compression technology has important implications for deploying deep learning in resource-constrained environments, such as on mobile devices or embedded systems. Further research exploring the limits and trade-offs of COMQ could help unlock even more efficient and practical deep learning solutions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
COMQ: A Backpropagation-Free Algorithm for Post-Training Quantization
Aozhong Zhang, Zi Yang, Naigang Wang, Yingyong Qin, Jack Xin, Xin Li, Penghang Yin
Post-training quantization (PTQ) has emerged as a practical approach to compress large neural networks, making them highly efficient for deployment. However, effectively reducing these models to their low-bit counterparts without compromising the original accuracy remains a key challenge. In this paper, we propose an innovative PTQ algorithm termed COMQ, which sequentially conducts coordinate-wise minimization of the layer-wise reconstruction errors. We consider the widely used integer quantization, where every quantized weight can be decomposed into a shared floating-point scalar and an integer bit-code. Within a fixed layer, COMQ treats all the scaling factor(s) and bit-codes as the variables of the reconstruction error. Every iteration improves this error along a single coordinate while keeping all other variables constant. COMQ is easy to use and requires no hyper-parameter tuning. It instead involves only dot products and rounding operations. We update these variables in a carefully designed greedy order, significantly enhancing the accuracy. COMQ achieves remarkable results in quantizing 4-bit Vision Transformers, with a negligible loss of less than 1% in Top-1 accuracy. In 4-bit INT quantization of convolutional neural networks, COMQ maintains near-lossless accuracy with a minimal drop of merely 0.3% in Top-1 accuracy.
Read more6/5/2024

0
Attention-aware Post-training Quantization without Backpropagation
Junhan Kim, Ho-young Kim, Eulrang Cho, Chungman Lee, Joonyoung Kim, Yongkweon Jeon
Quantization is a promising solution for deploying large-scale language models (LLMs) on resource-constrained devices. Existing quantization approaches, however, rely on gradient-based optimization, regardless of it being post-training quantization (PTQ) or quantization-aware training (QAT), which becomes problematic for hyper-scale LLMs with billions of parameters. This overhead can be alleviated via recently proposed backpropagation-free PTQ methods; however, their performance is somewhat limited by their lack of consideration of inter-layer dependencies. In this paper, we thus propose a novel PTQ algorithm that considers inter-layer dependencies without relying on backpropagation. The fundamental concept involved is the development of attention-aware Hessian matrices, which facilitates the consideration of inter-layer dependencies within the attention module. Extensive experiments demonstrate that the proposed algorithm significantly outperforms conventional PTQ methods, particularly for low bit-widths.
Read more6/21/2024
⛏️
0
CDQuant: Accurate Post-training Weight Quantization of Large Pre-trained Models using Greedy Coordinate Descent
Pranav Ajit Nair, Arun Sai Suggala
Large language models (LLMs) have recently demonstrated remarkable performance across diverse language tasks. But their deployment is often constrained by their substantial computational and storage requirements. Quantization has emerged as a key technique for addressing this challenge, enabling the compression of large models with minimal impact on performance. The recent GPTQ algorithm, a post-training quantization (PTQ) method, has proven highly effective for compressing LLMs, sparking a wave of research that leverages GPTQ as a core component. Recognizing the pivotal role of GPTQ in the PTQ landscape, we introduce CDQuant, a simple and scalable alternative to GPTQ with improved performance. CDQuant uses coordinate descent to minimize the layer-wise reconstruction loss to achieve high-quality quantized weights. Our algorithm is easy to implement and scales efficiently to models with hundreds of billions of parameters. Through extensive evaluation on the PaLM2 model family, we demonstrate that CDQuant consistently outperforms GPTQ across diverse model sizes and quantization levels. In particular, for INT2 quantization of PaLM2-Otter, CDQuant achieves a 10% reduction in perplexity compared to GPTQ.
Read more6/27/2024
0
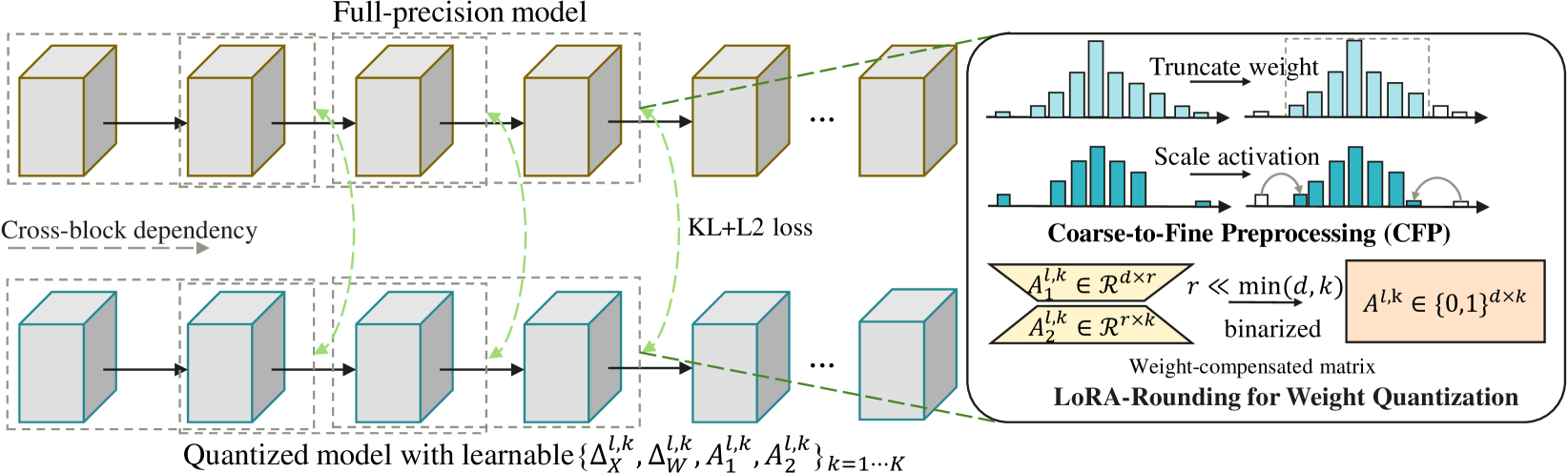
CBQ: Cross-Block Quantization for Large Language Models
Xin Ding, Xiaoyu Liu, Zhijun Tu, Yun Zhang, Wei Li, Jie Hu, Hanting Chen, Yehui Tang, Zhiwei Xiong, Baoqun Yin, Yunhe Wang
Post-training quantization (PTQ) has played a key role in compressing large language models (LLMs) with ultra-low costs. However, existing PTQ methods only focus on handling the outliers within one layer or one block, which ignores the dependency of blocks and leads to severe performance degradation in low-bit settings. In this paper, we propose CBQ, a cross-block reconstruction-based PTQ method for LLMs. CBQ employs a cross-block dependency using a homologous reconstruction scheme, establishing long-range dependencies across multiple blocks to minimize error accumulation. Furthermore, CBQ incorporates a coarse-to-fine preprocessing (CFP) strategy for suppressing weight and activation outliers, coupled with an adaptive LoRA-Rounding technique for precise weight quantization. These innovations enable CBQ to not only handle extreme outliers effectively but also improve overall quantization accuracy. Extensive experiments show that CBQ achieves superior low-bit quantization (W4A4, W4A8, W2A16) and outperforms existing state-of-the-art methods across various LLMs and datasets. Notably, CBQ quantizes the 4-bit LLAMA1-65B model within only 4.3 hours on a single GPU, achieving a commendable tradeoff between performance and quantization efficiency.
Read more4/16/2024