CRCL at SemEval-2024 Task 2: Simple prompt optimizations

0

Sign in to get full access
Overview
- This paper presents simple prompt optimizations for the CRCL team's participation in SemEval-2024 Task 2.
- The task involves evaluating the safety and efficacy of biomedical language models.
- The authors explore different strategies for optimizing the prompts used to generate model outputs.
Plain English Explanation
In this paper, the researchers from the CRCL team describe their approach to participating in a challenge called SemEval-2024 Task 2. This challenge is focused on evaluating how safe and effective certain language models are, particularly when it comes to working with biomedical information.
The key part of the CRCL team's strategy was exploring different ways to optimize the prompts, or instructions, that are given to the language models. Prompts are important because they can significantly influence the outputs generated by the models. By testing out various prompt modifications, the researchers aimed to find approaches that would help the models perform better on the task.
The paper provides details on the specific prompt optimization techniques they tried, as well as the results they obtained. The goal was to identify simple yet effective ways to improve the models' safety and efficacy when working with sensitive biomedical data.
Technical Explanation
The paper describes the CRCL team's participation in SemEval-2024 Task 2: Safe Biomedical Natural Language Generation, which evaluates the safety and efficacy of biomedical language models. The authors focus on exploring simple prompt optimization strategies to improve model performance.
The key prompt optimization techniques investigated include:
- Comparing different prompt structures and syntax
- Incorporating additional contextual information into the prompts
- Leveraging prompt ensembling and other ensemble methods
The authors evaluate the impact of these prompt optimization strategies on the models' safety and efficacy metrics, as defined by the SemEval-2024 Task 2 guidelines. The results provide insights into simple yet effective ways to improve the performance of biomedical language models on this important task.
Critical Analysis
The paper provides a focused exploration of prompt optimization techniques for the SemEval-2024 Task 2 challenge. The authors acknowledge the importance of prompt engineering in language model performance and present a practical, empirical approach to investigating different strategies.
One potential limitation is the relatively narrow scope of the study, which is limited to the specific task and dataset provided by the SemEval-2024 challenge. Applying these prompt optimization techniques to other biomedical language modeling tasks or datasets may yield different results, and further research would be needed to assess the generalizability of the findings.
Additionally, the paper does not delve deeply into the underlying reasons why certain prompt optimizations are more effective than others. A more detailed analysis of the linguistic and cognitive factors influencing prompt effectiveness could provide valuable insights for the broader field of prompt engineering.
Despite these minor caveats, the paper offers a solid contribution to the growing body of research on improving the safety and efficacy of biomedical language models through simple, yet impactful, prompt optimization strategies.
Conclusion
This paper presents the CRCL team's work on prompt optimization techniques for the SemEval-2024 Task 2 challenge, which focuses on evaluating the safety and efficacy of biomedical language models. The authors explore various prompt engineering strategies, including comparing different prompt structures, incorporating additional contextual information, and leveraging ensemble methods.
The results provide practical insights into simple yet effective ways to enhance the performance of language models on this important task. While the scope of the study is limited to the specific challenge, the findings could have broader implications for improving the safety and reliability of biomedical language AI systems more generally.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
CRCL at SemEval-2024 Task 2: Simple prompt optimizations
Cl'ement Brutti-Mairesse, Loic Verlingue
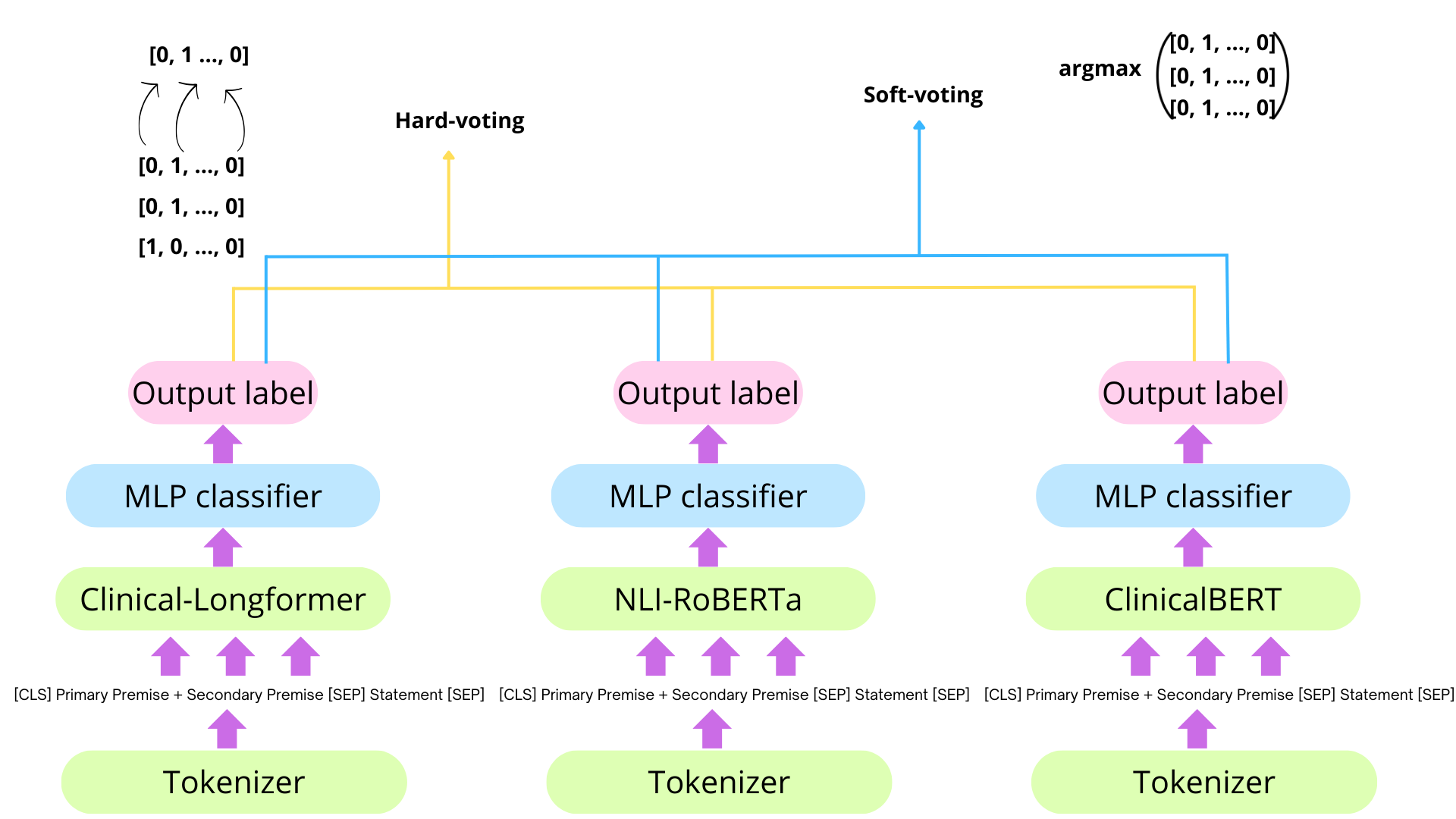
We present a baseline for the SemEval 2024 task 2 challenge, whose objective is to ascertain the inference relationship between pairs of clinical trial report sections and statements. We apply prompt optimization techniques with LLM Instruct models provided as a Language Model-as-a-Service (LMaaS). We observed, in line with recent findings, that synthetic CoT prompts significantly enhance manually crafted ones.
Read more5/6/2024
0
SEME at SemEval-2024 Task 2: Comparing Masked and Generative Language Models on Natural Language Inference for Clinical Trials
Mathilde Aguiar, Pierre Zweigenbaum, Nona Naderi
This paper describes our submission to Task 2 of SemEval-2024: Safe Biomedical Natural Language Inference for Clinical Trials. The Multi-evidence Natural Language Inference for Clinical Trial Data (NLI4CT) consists of a Textual Entailment (TE) task focused on the evaluation of the consistency and faithfulness of Natural Language Inference (NLI) models applied to Clinical Trial Reports (CTR). We test 2 distinct approaches, one based on finetuning and ensembling Masked Language Models and the other based on prompting Large Language Models using templates, in particular, using Chain-Of-Thought and Contrastive Chain-Of-Thought. Prompting Flan-T5-large in a 2-shot setting leads to our best system that achieves 0.57 F1 score, 0.64 Faithfulness, and 0.56 Consistency.
Read more4/8/2024
📈
0
Lisbon Computational Linguists at SemEval-2024 Task 2: Using A Mistral 7B Model and Data Augmentation
Artur Guimar~aes, Bruno Martins, Jo~ao Magalh~aes
This paper describes our approach to the SemEval-2024 safe biomedical Natural Language Inference for Clinical Trials (NLI4CT) task, which concerns classifying statements about Clinical Trial Reports (CTRs). We explored the capabilities of Mistral-7B, a generalist open-source Large Language Model (LLM). We developed a prompt for the NLI4CT task, and fine-tuned a quantized version of the model using an augmented version of the training dataset. The experimental results show that this approach can produce notable results in terms of the macro F1-score, while having limitations in terms of faithfulness and consistency. All the developed code is publicly available on a GitHub repository
Read more8/7/2024

0
SemEval-2024 Task 2: Safe Biomedical Natural Language Inference for Clinical Trials
Mael Jullien, Marco Valentino, Andr'e Freitas
Large Language Models (LLMs) are at the forefront of NLP achievements but fall short in dealing with shortcut learning, factual inconsistency, and vulnerability to adversarial inputs.These shortcomings are especially critical in medical contexts, where they can misrepresent actual model capabilities. Addressing this, we present SemEval-2024 Task 2: Safe Biomedical Natural Language Inference for ClinicalTrials. Our contributions include the refined NLI4CT-P dataset (i.e., Natural Language Inference for Clinical Trials - Perturbed), designed to challenge LLMs with interventional and causal reasoning tasks, along with a comprehensive evaluation of methods and results for participant submissions. A total of 106 participants registered for the task contributing to over 1200 individual submissions and 25 system overview papers. This initiative aims to advance the robustness and applicability of NLI models in healthcare, ensuring safer and more dependable AI assistance in clinical decision-making. We anticipate that the dataset, models, and outcomes of this task can support future research in the field of biomedical NLI. The dataset, competition leaderboard, and website are publicly available.
Read more4/9/2024