Deep Grokking: Would Deep Neural Networks Generalize Better?

0
Sign in to get full access
Overview
- This paper investigates whether deep neural networks can "grok" or generalize better to new data, using a series of experiments.
- The researchers explore how different training approaches and model architectures affect the ability of neural networks to generalize beyond the training data.
- The findings provide insights into the potential of deep learning models to learn robust and transferable representations.
Plain English Explanation
The paper examines whether deep neural networks, a type of powerful machine learning model, can "grok" or learn to generalize their knowledge to new, unseen data. This is an important capability, as it allows AI systems to apply what they've learned to novel situations, rather than just memorizing patterns in the training data.
The researchers conducted a series of experiments to test different training strategies and model designs, to see how they impact the network's ability to generalize. For example, they looked at how the choice of activation functions or the use of skip connections in the model architecture might affect generalization performance.
The key idea behind "grokking" is that the network is able to extract the underlying patterns and rules from the training data, rather than just memorizing specific examples. This allows the model to make accurate predictions on new, previously unseen inputs - a crucial capability for real-world AI applications.
The findings from this research provide valuable insights into how to design and train deep learning models that can learn more robust and transferable representations. This could lead to AI systems that are more flexible, adaptable and capable of generalizing their knowledge to novel situations.
Technical Explanation
The paper investigates the phenomenon of "deep grokking", where deep neural networks are able to extract the underlying structure of a problem and generalize their knowledge beyond the training data. The researchers conduct a series of experiments to understand the factors that influence a network's ability to grok.
In one set of experiments, the authors explore how the choice of activation function impacts generalization. They find that Swish activations, which have a smoother derivative than ReLUs, lead to better grokking performance. This suggests that the model's ability to learn smooth, continuous representations is an important factor for generalization.
The paper also examines the role of skip connections, which allow information to flow directly between distant layers in the network. The results indicate that skip connections can improve a model's grokking capabilities, likely by facilitating the learning of hierarchical abstractions.
Additionally, the researchers investigate the impact of the training dataset size and noise level. They find that larger datasets and lower noise levels tend to produce models that grok more effectively. This aligns with the intuition that having more high-quality training data allows the network to better capture the underlying patterns.
The technical analysis provided in the paper offers valuable insights into the inductive biases and architectural choices that can enable deep neural networks to learn more generalizable representations. These findings have important implications for the design of robust and adaptable AI systems.
Critical Analysis
The paper provides a thoughtful investigation into the factors that influence the generalization capabilities of deep neural networks. The experimental results offer nuanced insights, highlighting the complex interplay between model architecture, training data, and the ability to grok.
One potential limitation of the study is the reliance on synthetic datasets, which may not fully capture the challenges of real-world generalization tasks. While the controlled experiments allow for cleaner analysis, it would be valuable to see how the identified grokking factors translate to performance on diverse, natural data.
Additionally, the paper does not delve deeply into the theoretical underpinnings of grokking. A more rigorous mathematical analysis of the mechanisms underlying this phenomenon could further strengthen the theoretical foundations of the work.
That said, the authors do acknowledge the need for additional research to fully understand the generalization capabilities of deep learning. They encourage the community to build on these findings and explore alternative approaches to enable more robust and adaptable AI systems.
Overall, this paper represents an important contribution to the ongoing quest to develop deep learning models that can reliably generalize their knowledge to new, unseen data. The insights provided here serve as a solid foundation for future work in this critical area of machine learning research.
Conclusion
This paper presents a comprehensive investigation into the concept of "deep grokking", which refers to the ability of deep neural networks to extract the underlying structure of a problem and generalize their knowledge beyond the training data.
Through a series of carefully designed experiments, the researchers explore how factors such as activation functions, skip connections, dataset size, and noise levels impact a model's grokking capabilities. The findings offer valuable insights into the inductive biases and architectural choices that can enable deep learning models to learn more robust and transferable representations.
The implications of this work are significant, as the development of AI systems that can reliably generalize their knowledge is a crucial step toward building more flexible, adaptable, and capable machine learning applications. By shedding light on the mechanisms underlying grokking, this paper lays the groundwork for future research aimed at further advancing the generalization abilities of deep neural networks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Deep Grokking: Would Deep Neural Networks Generalize Better?
Simin Fan, Razvan Pascanu, Martin Jaggi
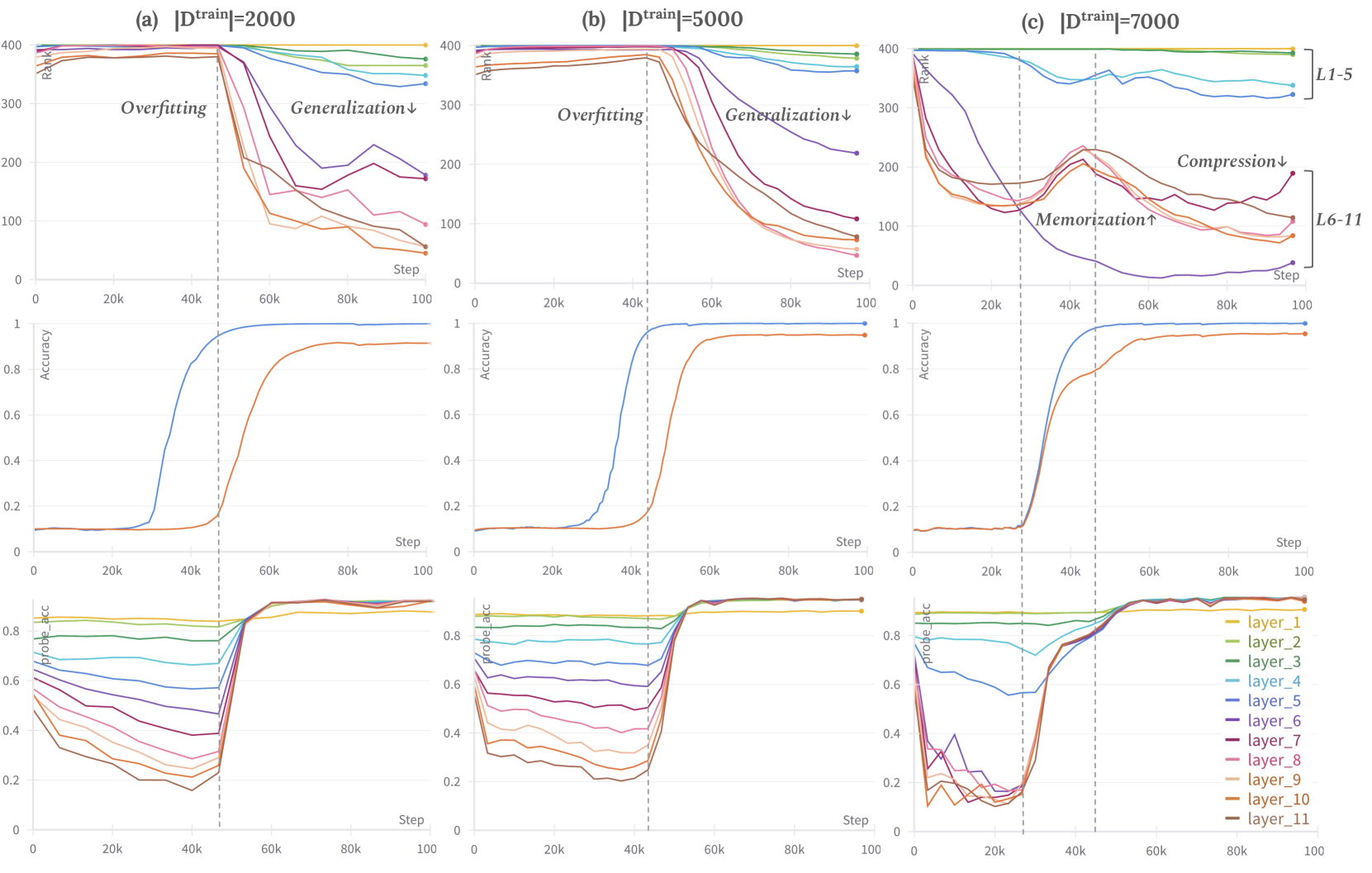
Recent research on the grokking phenomenon has illuminated the intricacies of neural networks' training dynamics and their generalization behaviors. Grokking refers to a sharp rise of the network's generalization accuracy on the test set, which occurs long after an extended overfitting phase, during which the network perfectly fits the training set. While the existing research primarily focus on shallow networks such as 2-layer MLP and 1-layer Transformer, we explore grokking on deep networks (e.g. 12-layer MLP). We empirically replicate the phenomenon and find that deep neural networks can be more susceptible to grokking than its shallower counterparts. Meanwhile, we observe an intriguing multi-stage generalization phenomenon when increase the depth of the MLP model where the test accuracy exhibits a secondary surge, which is scarcely seen on shallow models. We further uncover compelling correspondences between the decreasing of feature ranks and the phase transition from overfitting to the generalization stage during grokking. Additionally, we find that the multi-stage generalization phenomenon often aligns with a double-descent pattern in feature ranks. These observations suggest that internal feature rank could serve as a more promising indicator of the model's generalization behavior compared to the weight-norm. We believe our work is the first one to dive into grokking in deep neural networks, and investigate the relationship of feature rank and generalization performance.
Read more5/31/2024
0
Deep Networks Always Grok and Here is Why
Ahmed Imtiaz Humayun, Randall Balestriero, Richard Baraniuk
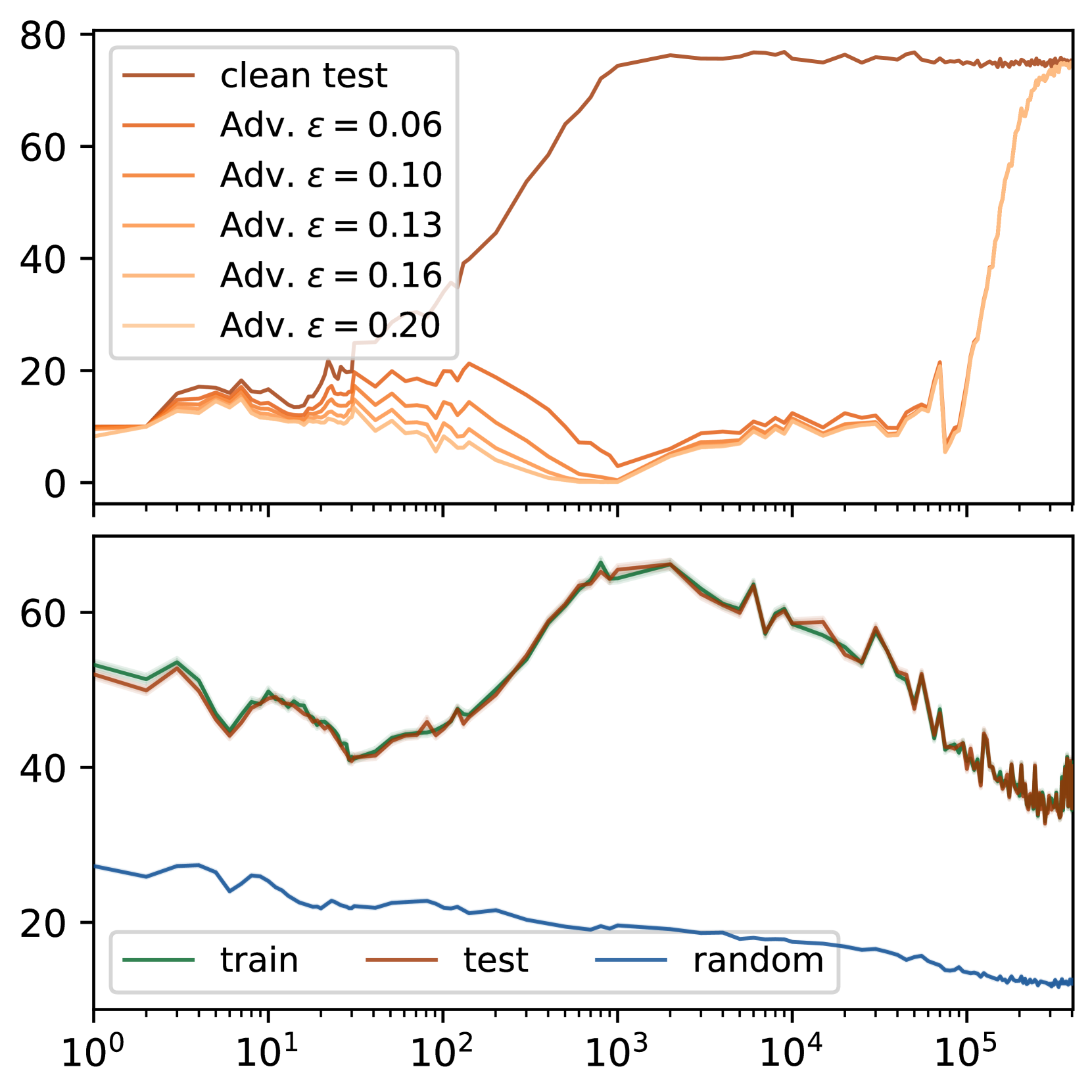
Grokking, or delayed generalization, is a phenomenon where generalization in a deep neural network (DNN) occurs long after achieving near zero training error. Previous studies have reported the occurrence of grokking in specific controlled settings, such as DNNs initialized with large-norm parameters or transformers trained on algorithmic datasets. We demonstrate that grokking is actually much more widespread and materializes in a wide range of practical settings, such as training of a convolutional neural network (CNN) on CIFAR10 or a Resnet on Imagenette. We introduce the new concept of delayed robustness, whereby a DNN groks adversarial examples and becomes robust, long after interpolation and/or generalization. We develop an analytical explanation for the emergence of both delayed generalization and delayed robustness based on the local complexity of a DNN's input-output mapping. Our local complexity measures the density of so-called linear regions (aka, spline partition regions) that tile the DNN input space and serves as a utile progress measure for training. We provide the first evidence that, for classification problems, the linear regions undergo a phase transition during training whereafter they migrate away from the training samples (making the DNN mapping smoother there) and towards the decision boundary (making the DNN mapping less smooth there). Grokking occurs post phase transition as a robust partition of the input space thanks to the linearization of the DNN mapping around the training points. Website: https://bit.ly/grok-adversarial
Read more6/10/2024
0
Grokking as the Transition from Lazy to Rich Training Dynamics
Tanishq Kumar, Blake Bordelon, Samuel J. Gershman, Cengiz Pehlevan
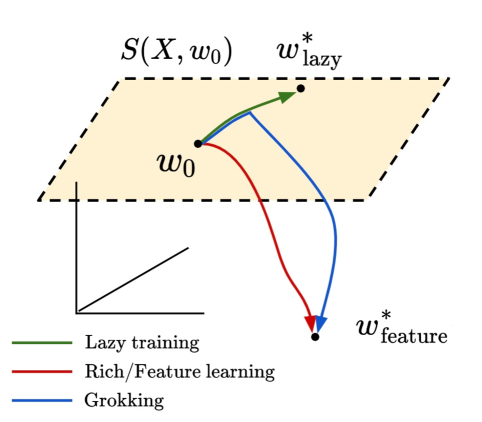
We propose that the grokking phenomenon, where the train loss of a neural network decreases much earlier than its test loss, can arise due to a neural network transitioning from lazy training dynamics to a rich, feature learning regime. To illustrate this mechanism, we study the simple setting of vanilla gradient descent on a polynomial regression problem with a two layer neural network which exhibits grokking without regularization in a way that cannot be explained by existing theories. We identify sufficient statistics for the test loss of such a network, and tracking these over training reveals that grokking arises in this setting when the network first attempts to fit a kernel regression solution with its initial features, followed by late-time feature learning where a generalizing solution is identified after train loss is already low. We find that the key determinants of grokking are the rate of feature learning -- which can be controlled precisely by parameters that scale the network output -- and the alignment of the initial features with the target function $y(x)$. We argue this delayed generalization arises when (1) the top eigenvectors of the initial neural tangent kernel and the task labels $y(x)$ are misaligned, but (2) the dataset size is large enough so that it is possible for the network to generalize eventually, but not so large that train loss perfectly tracks test loss at all epochs, and (3) the network begins training in the lazy regime so does not learn features immediately. We conclude with evidence that this transition from lazy (linear model) to rich training (feature learning) can control grokking in more general settings, like on MNIST, one-layer Transformers, and student-teacher networks.
Read more4/12/2024

0
A rationale from frequency perspective for grokking in training neural network
Zhangchen Zhou, Yaoyu Zhang, Zhi-Qin John Xu
Grokking is the phenomenon where neural networks NNs initially fit the training data and later generalize to the test data during training. In this paper, we empirically provide a frequency perspective to explain the emergence of this phenomenon in NNs. The core insight is that the networks initially learn the less salient frequency components present in the test data. We observe this phenomenon across both synthetic and real datasets, offering a novel viewpoint for elucidating the grokking phenomenon by characterizing it through the lens of frequency dynamics during the training process. Our empirical frequency-based analysis sheds new light on understanding the grokking phenomenon and its underlying mechanisms.
Read more5/29/2024