Dichotomy of Early and Late Phase Implicit Biases Can Provably Induce Grokking

0

Sign in to get full access
Overview
- The research paper explores how a dichotomy of early and late phase implicit biases can provably induce "grokking" - the ability to rapidly learn and generalize complex patterns.
- The paper presents a motivating experiment on modular addition to demonstrate this phenomenon.
- It provides a theoretical analysis and proofs showing how this dichotomy of biases can enable the rapid learning and generalization observed in the experiment.
Plain English Explanation
The paper investigates an intriguing property of machine learning models, where they can sometimes develop a deep, intuitive understanding of a task, allowing them to quickly apply what they've learned to new, related problems. This ability is often referred to as "grokking."
The researchers hypothesized that the development of this grokking behavior could be linked to a specific pattern of biases that emerge during the training process. Specifically, they propose that models go through an "early phase" where they pick up on certain superficial cues or patterns, followed by a "late phase" where they discover more fundamental, generalizable principles.
To test this idea, the researchers designed an experiment using the task of modular addition - adding numbers while wrapping around a fixed value, like a clock. They trained models on this task and found that the models were able to rapidly learn and apply the underlying principles, even when faced with new types of problems.
The paper then provides a theoretical analysis to explain why this dichotomy of early and late phase biases can provably lead to this grokking behavior. Essentially, the early biases allow the model to quickly latch onto certain patterns, while the later biases push it to discover more general, transferable knowledge.
The researchers argue that this insight could have important implications for building more capable and efficient machine learning systems, as well as for understanding how human cognition works.
Technical Explanation
The paper begins by introducing the concept of "grokking" - the ability of machine learning models to rapidly learn and generalize complex patterns. The authors hypothesize that this phenomenon can be provably induced by a dichotomy of early and late phase implicit biases that emerge during training.
To demonstrate this, the paper presents a motivating experiment on the task of modular addition. Models were trained on a range of modular addition problems, and the results showed that they were able to quickly learn the underlying principles and apply them to novel instances, exhibiting grokking behavior.
The authors then provide a theoretical analysis to explain this finding. They show that the models go through two distinct phases during training:
- An "early phase" where they pick up on certain superficial cues or patterns in the training data.
- A "late phase" where they discover more fundamental, generalizable principles.
The paper proves that this dichotomy of biases can provably induce grokking, as the early phase biases allow the model to quickly latch onto certain patterns, while the later biases push it to discover more general, transferable knowledge.
The authors argue that this insight could have important implications for building more capable and efficient machine learning systems, as well as for understanding how human cognition works. They suggest that engineering the right kind of biases into machine learning models could be a promising avenue for enabling grokking and rapid learning.
Critical Analysis
The paper provides a rigorous theoretical analysis and experimental demonstration of how a dichotomy of early and late phase biases can induce grokking behavior in machine learning models. The authors make a compelling case for the importance of understanding these bias dynamics, as they could be crucial for developing more powerful and efficient AI systems.
However, the paper does not delve into potential limitations or caveats of the proposed approach. For instance, it is unclear how sensitive the grokking phenomenon is to the specific model architecture, training procedure, or task complexity. Additionally, the paper does not address potential negative societal implications if these biases are not carefully controlled, such as the propagation of unintended biases.
Further research could explore the generalizability of these findings across a broader range of tasks and model types, as well as investigate practical methods for engineering the desired bias dichotomy in real-world machine learning systems. Careful consideration of ethical and fairness concerns should also be a priority, as the ability to rapidly learn and generalize could have significant societal impact.
Conclusion
The research presented in this paper offers a novel perspective on the mechanisms underlying grokking, a remarkable property of machine learning models. By demonstrating how a dichotomy of early and late phase biases can provably induce this behavior, the authors provide valuable insights that could inform the development of more capable and efficient AI systems.
While the theoretical analysis and experimental results are compelling, further investigation is needed to fully understand the limitations and potential implications of this approach. Nonetheless, this work represents an important step forward in our understanding of the factors that enable rapid learning and generalization in machine learning, with significant potential for advancing the field of artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Dichotomy of Early and Late Phase Implicit Biases Can Provably Induce Grokking
Kaifeng Lyu, Jikai Jin, Zhiyuan Li, Simon S. Du, Jason D. Lee, Wei Hu
Recent work by Power et al. (2022) highlighted a surprising grokking phenomenon in learning arithmetic tasks: a neural net first memorizes the training set, resulting in perfect training accuracy but near-random test accuracy, and after training for sufficiently longer, it suddenly transitions to perfect test accuracy. This paper studies the grokking phenomenon in theoretical setups and shows that it can be induced by a dichotomy of early and late phase implicit biases. Specifically, when training homogeneous neural nets with large initialization and small weight decay on both classification and regression tasks, we prove that the training process gets trapped at a solution corresponding to a kernel predictor for a long time, and then a very sharp transition to min-norm/max-margin predictors occurs, leading to a dramatic change in test accuracy.
Read more4/3/2024
0
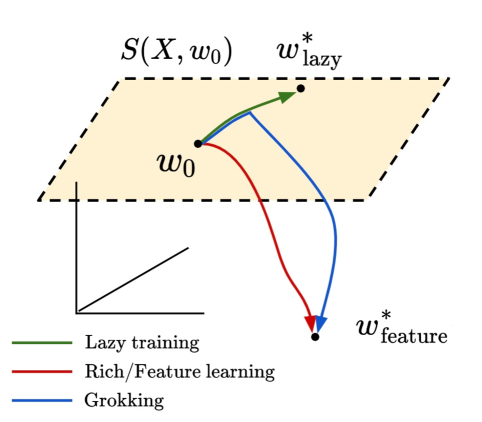
Grokking as the Transition from Lazy to Rich Training Dynamics
Tanishq Kumar, Blake Bordelon, Samuel J. Gershman, Cengiz Pehlevan
We propose that the grokking phenomenon, where the train loss of a neural network decreases much earlier than its test loss, can arise due to a neural network transitioning from lazy training dynamics to a rich, feature learning regime. To illustrate this mechanism, we study the simple setting of vanilla gradient descent on a polynomial regression problem with a two layer neural network which exhibits grokking without regularization in a way that cannot be explained by existing theories. We identify sufficient statistics for the test loss of such a network, and tracking these over training reveals that grokking arises in this setting when the network first attempts to fit a kernel regression solution with its initial features, followed by late-time feature learning where a generalizing solution is identified after train loss is already low. We find that the key determinants of grokking are the rate of feature learning -- which can be controlled precisely by parameters that scale the network output -- and the alignment of the initial features with the target function $y(x)$. We argue this delayed generalization arises when (1) the top eigenvectors of the initial neural tangent kernel and the task labels $y(x)$ are misaligned, but (2) the dataset size is large enough so that it is possible for the network to generalize eventually, but not so large that train loss perfectly tracks test loss at all epochs, and (3) the network begins training in the lazy regime so does not learn features immediately. We conclude with evidence that this transition from lazy (linear model) to rich training (feature learning) can control grokking in more general settings, like on MNIST, one-layer Transformers, and student-teacher networks.
Read more4/12/2024
1
Information-Theoretic Progress Measures reveal Grokking is an Emergent Phase Transition
Kenzo Clauw, Sebastiano Stramaglia, Daniele Marinazzo
This paper studies emergent phenomena in neural networks by focusing on grokking where models suddenly generalize after delayed memorization. To understand this phase transition, we utilize higher-order mutual information to analyze the collective behavior (synergy) and shared properties (redundancy) between neurons during training. We identify distinct phases before grokking allowing us to anticipate when it occurs. We attribute grokking to an emergent phase transition caused by the synergistic interactions between neurons as a whole. We show that weight decay and weight initialization can enhance the emergent phase.
Read more8/20/2024

0
Grokking as a First Order Phase Transition in Two Layer Networks
Noa Rubin, Inbar Seroussi, Zohar Ringel
A key property of deep neural networks (DNNs) is their ability to learn new features during training. This intriguing aspect of deep learning stands out most clearly in recently reported Grokking phenomena. While mainly reflected as a sudden increase in test accuracy, Grokking is also believed to be a beyond lazy-learning/Gaussian Process (GP) phenomenon involving feature learning. Here we apply a recent development in the theory of feature learning, the adaptive kernel approach, to two teacher-student models with cubic-polynomial and modular addition teachers. We provide analytical predictions on feature learning and Grokking properties of these models and demonstrate a mapping between Grokking and the theory of phase transitions. We show that after Grokking, the state of the DNN is analogous to the mixed phase following a first-order phase transition. In this mixed phase, the DNN generates useful internal representations of the teacher that are sharply distinct from those before the transition.
Read more5/7/2024