Discovering influential text using convolutional neural networks

0
🧠
Sign in to get full access
Overview
- This paper provides instructions for authors submitting papers to the ACL 2023 conference proceedings.
- It covers topics like formatting, templates, and submission guidelines.
- The instructions aim to ensure a consistent look and feel for the published papers.
Plain English Explanation
The paper you provided contains the instructions for authors who want to submit their research papers to the ACL 2023 conference proceedings. This is an important conference in the field of natural language processing, and the organizers want the published papers to have a uniform style and format.
The instructions cover things like how to format the paper, what templates to use, and the submission process. This helps ensure that all the papers in the proceedings look and feel consistent, making it easier for readers to navigate and understand the content.
By providing clear guidelines, the conference organizers can streamline the publication process and make it simpler for authors to prepare their submissions. This benefits both the authors and the readers, as it creates a polished and cohesive final product.
Technical Explanation
The paper outlines the instructions for authors submitting papers to the ACL 2023 conference proceedings. It covers the formatting requirements, such as the use of specific templates and guidelines for section headings, figures, and references.
The instructions also detail the submission process, including the use of the Softconf platform and the deadlines for various stages of the process. This ensures a standardized approach to paper submission and review.
Additionally, the paper provides information on the use of engines, such as LaTeX, to generate the final paper files. This helps maintain a consistent visual style and layout for the published proceedings.
Critical Analysis
The instructions provided in this paper are comprehensive and well-structured, ensuring a streamlined submission and publication process for the ACL 2023 conference. The clear guidelines and use of standardized templates and formats help to create a cohesive and professional-looking proceedings.
However, one potential limitation is the reliance on specific software and tools, such as LaTeX and the Softconf platform. This may pose challenges for authors who are less familiar with these technologies, potentially creating barriers to participation. The organizers could consider providing more support or alternative options to ensure a more inclusive and accessible submission process.
Conclusion
The instructions for the ACL 2023 proceedings outline a well-organized and consistent approach to paper submission and publication. By providing clear guidelines and standardized templates, the organizers aim to create a cohesive and professional-looking final product.
While the reliance on specific software and tools may present some challenges, the overall structure and attention to detail in these instructions are commendable. They will likely contribute to a successful and high-quality conference proceedings that showcases the latest research in natural language processing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧠
0
Discovering influential text using convolutional neural networks
Megan Ayers, Luke Sanford, Margaret Roberts, Eddie Yang
Experimental methods for estimating the impacts of text on human evaluation have been widely used in the social sciences. However, researchers in experimental settings are usually limited to testing a small number of pre-specified text treatments. While efforts to mine unstructured texts for features that causally affect outcomes have been ongoing in recent years, these models have primarily focused on the topics or specific words of text, which may not always be the mechanism of the effect. We connect these efforts with NLP interpretability techniques and present a method for flexibly discovering clusters of similar text phrases that are predictive of human reactions to texts using convolutional neural networks. When used in an experimental setting, this method can identify text treatments and their effects under certain assumptions. We apply the method to two datasets. The first enables direct validation of the model's ability to detect phrases known to cause the outcome. The second demonstrates its ability to flexibly discover text treatments with varying textual structures. In both cases, the model learns a greater variety of text treatments compared to benchmark methods, and these text features quantitatively meet or exceed the ability of benchmark methods to predict the outcome.
Read more6/26/2024
0
End-To-End Causal Effect Estimation from Unstructured Natural Language Data
Nikita Dhawan, Leonardo Cotta, Karen Ullrich, Rahul G. Krishnan, Chris J. Maddison
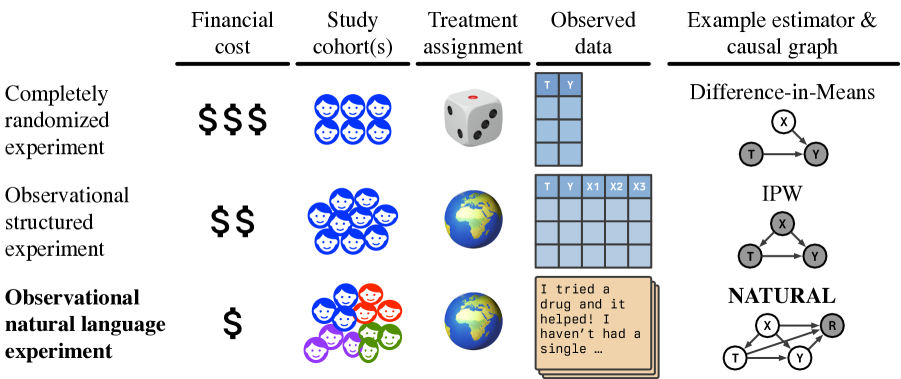
Knowing the effect of an intervention is critical for human decision-making, but current approaches for causal effect estimation rely on manual data collection and structuring, regardless of the causal assumptions. This increases both the cost and time-to-completion for studies. We show how large, diverse observational text data can be mined with large language models (LLMs) to produce inexpensive causal effect estimates under appropriate causal assumptions. We introduce NATURAL, a novel family of causal effect estimators built with LLMs that operate over datasets of unstructured text. Our estimators use LLM conditional distributions (over variables of interest, given the text data) to assist in the computation of classical estimators of causal effect. We overcome a number of technical challenges to realize this idea, such as automating data curation and using LLMs to impute missing information. We prepare six (two synthetic and four real) observational datasets, paired with corresponding ground truth in the form of randomized trials, which we used to systematically evaluate each step of our pipeline. NATURAL estimators demonstrate remarkable performance, yielding causal effect estimates that fall within 3 percentage points of their ground truth counterparts, including on real-world Phase 3/4 clinical trials. Our results suggest that unstructured text data is a rich source of causal effect information, and NATURAL is a first step towards an automated pipeline to tap this resource.
Read more8/26/2024

0
New!From Text to Treatment Effects: A Meta-Learning Approach to Handling Text-Based Confounding
Henri Arno, Paloma Rabaey, Thomas Demeester
One of the central goals of causal machine learning is the accurate estimation of heterogeneous treatment effects from observational data. In recent years, meta-learning has emerged as a flexible, model-agnostic paradigm for estimating conditional average treatment effects (CATE) using any supervised model. This paper examines the performance of meta-learners when the confounding variables are embedded in text. Through synthetic data experiments, we show that learners using pre-trained text representations of confounders, in addition to tabular background variables, achieve improved CATE estimates compare to those relying solely on the tabular variables, particularly when sufficient data is available. However, due to the entangled nature of the text embeddings, these models do not fully match the performance of meta-learners with perfect confounder knowledge. These findings highlight both the potential and the limitations of pre-trained text representations for causal inference and open up interesting avenues for future research.
Read more9/25/2024
🔗
0
Human-interpretable clustering of short-text using large language models
Justin K. Miller, Tristram J. Alexander
Large language models have seen extraordinary growth in popularity due to their human-like content generation capabilities. We show that these models can also be used to successfully cluster human-generated content, with success defined through the measures of distinctiveness and interpretability. This success is validated by both human reviewers and ChatGPT, providing an automated means to close the 'validation gap' that has challenged short-text clustering. Comparing the machine and human approaches we identify the biases inherent in each, and question the reliance on human-coding as the 'gold standard'. We apply our methodology to Twitter bios and find characteristic ways humans describe themselves, agreeing well with prior specialist work, but with interesting differences characteristic of the medium used to express identity.
Read more5/14/2024