Discovering Preference Optimization Algorithms with and for Large Language Models

1
Sign in to get full access
Overview
- This paper explores the development of preference optimization algorithms for use with large language models (LLMs).
- The researchers investigate methods for training LLMs to align with human preferences, which is a crucial challenge as these models become more powerful and influential.
- The paper covers several key approaches, including generalized preference optimization, causal modeling of preference learning, and efficient online preference tuning.
Plain English Explanation
As large language models (LLMs) like GPT-3 become increasingly capable and influential, it's crucial that we find ways to ensure they behave in alignment with human preferences and values. This paper explores several approaches to tackling this challenge.
One key idea is generalized preference optimization, which provides a unified framework for training LLMs to optimize for human preferences, even in complex, high-dimensional settings. This could allow us to imbue LLMs with a more nuanced understanding of what humans value.
The paper also looks at causal modeling of preference learning, which aims to better understand how LLMs can learn human preferences by modeling the underlying causal factors. This could lead to more robust and transparent preference alignment.
Additionally, the researchers investigate efficient online preference tuning, which would allow LLMs to quickly adapt to individual users' preferences in real-time. This could enable highly personalized language models that cater to each user's unique needs and values.
Overall, this work represents an important step towards developing LLMs that reliably act in accordance with human preferences, which is crucial as these models become more ubiquitous and influential in our lives.
Technical Explanation
The paper explores several approaches to the challenge of aligning large language models (LLMs) with human preferences.
One key contribution is the generalized preference optimization framework, which provides a unified mathematical formulation for training LLMs to optimize for complex, high-dimensional human preferences. This builds on prior work in preference learning and preference optimization, offering a more principled and scalable approach.
The researchers also investigate causal modeling of preference learning, which aims to understand how LLMs can learn human preferences by modeling the underlying causal factors. This could lead to more robust and interpretable preference alignment.
Additionally, the paper explores efficient online preference tuning, which would enable LLMs to quickly adapt to individual users' preferences in real-time. This could facilitate the development of highly personalized language models that cater to each user's unique needs and values.
Critical Analysis
The paper presents a compelling set of technical approaches for aligning large language models (LLMs) with human preferences. However, it's important to note that the challenge of preference alignment is complex and multifaceted, with many open questions and potential pitfalls.
One key limitation is the inherent difficulty in capturing the full breadth and nuance of human preferences, which can be highly subjective, context-dependent, and even contradictory. The researchers acknowledge this challenge and emphasize the need for further work to refine and validate their approaches.
Additionally, there are important ethical considerations around the use of preference optimization algorithms, particularly in high-stakes domains like healthcare or finance. The paper does not delve deeply into these concerns, which will need to be carefully addressed as this technology is developed and deployed.
Overall, this paper represents an important step forward in the quest to create LLMs that reliably act in alignment with human values. However, continued research, robust testing, and thoughtful consideration of the societal implications will be crucial as these techniques are refined and applied in the real world.
Conclusion
This paper presents several promising approaches for developing preference optimization algorithms that can be used to align large language models (LLMs) with human preferences. By exploring methods like generalized preference optimization, causal modeling of preference learning, and efficient online preference tuning, the researchers are making important strides towards creating LLMs that reliably behave in accordance with human values.
As these powerful language models become increasingly ubiquitous and influential, ensuring their alignment with human preferences is a crucial challenge that will have far-reaching implications for society. The technical insights and conceptual breakthroughs presented in this paper represent a significant contribution to this critical area of research, paving the way for the development of LLMs that can be safely and responsibly deployed to enhance our lives.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
1
Discovering Preference Optimization Algorithms with and for Large Language Models
Chris Lu, Samuel Holt, Claudio Fanconi, Alex J. Chan, Jakob Foerster, Mihaela van der Schaar, Robert Tjarko Lange
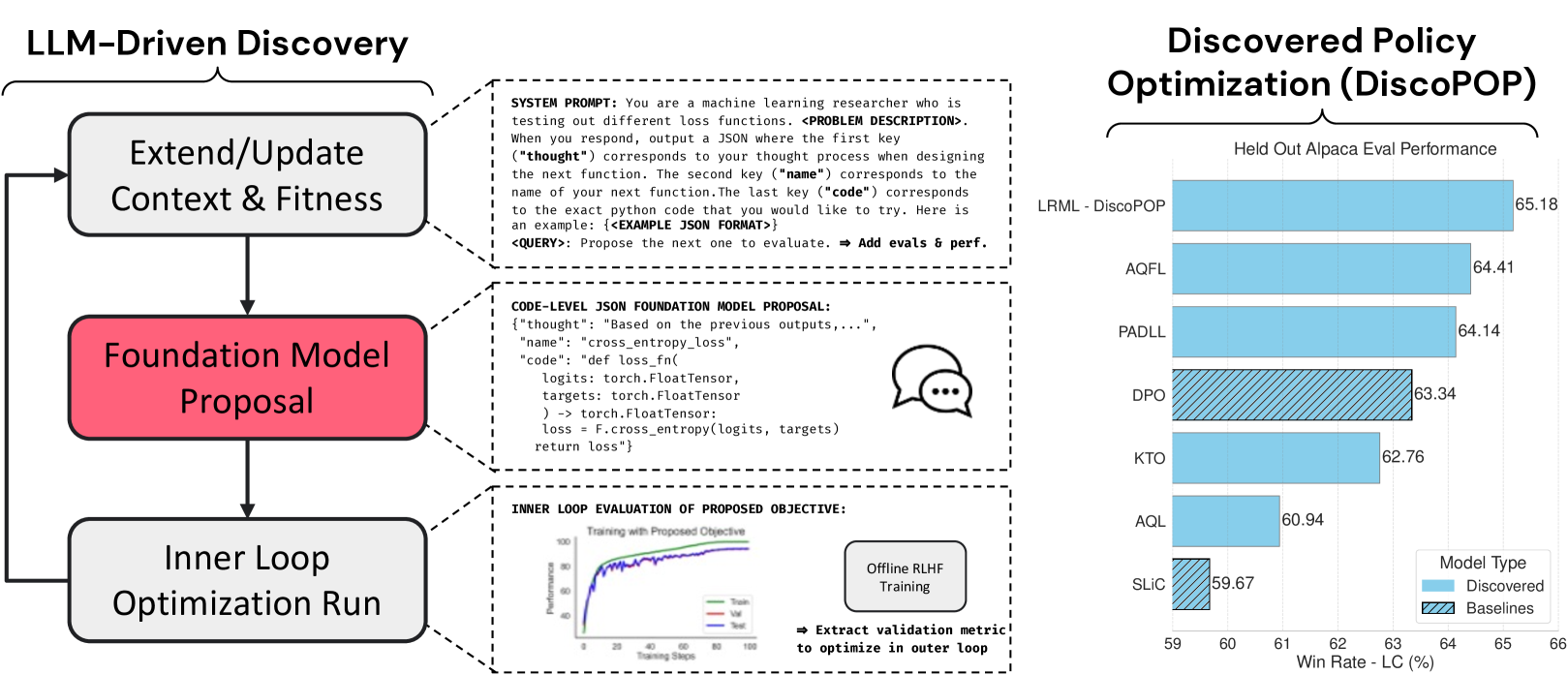
Offline preference optimization is a key method for enhancing and controlling the quality of Large Language Model (LLM) outputs. Typically, preference optimization is approached as an offline supervised learning task using manually-crafted convex loss functions. While these methods are based on theoretical insights, they are inherently constrained by human creativity, so the large search space of possible loss functions remains under explored. We address this by performing LLM-driven objective discovery to automatically discover new state-of-the-art preference optimization algorithms without (expert) human intervention. Specifically, we iteratively prompt an LLM to propose and implement new preference optimization loss functions based on previously-evaluated performance metrics. This process leads to the discovery of previously-unknown and performant preference optimization algorithms. The best performing of these we call Discovered Preference Optimization (DiscoPOP), a novel algorithm that adaptively blends logistic and exponential losses. Experiments demonstrate the state-of-the-art performance of DiscoPOP and its successful transfer to held-out tasks.
Read more9/4/2024
👨🏫
0
Generalized Preference Optimization: A Unified Approach to Offline Alignment
Yunhao Tang, Zhaohan Daniel Guo, Zeyu Zheng, Daniele Calandriello, R'emi Munos, Mark Rowland, Pierre Harvey Richemond, Michal Valko, Bernardo 'Avila Pires, Bilal Piot
Offline preference optimization allows fine-tuning large models directly from offline data, and has proved effective in recent alignment practices. We propose generalized preference optimization (GPO), a family of offline losses parameterized by a general class of convex functions. GPO enables a unified view over preference optimization, encompassing existing algorithms such as DPO, IPO and SLiC as special cases, while naturally introducing new variants. The GPO framework also sheds light on how offline algorithms enforce regularization, through the design of the convex function that defines the loss. Our analysis and experiments reveal the connections and subtle differences between the offline regularization and the KL divergence regularization intended by the canonical RLHF formulation. In a controlled setting akin to Gao et al 2023, we also show that different GPO variants achieve similar trade-offs between regularization and performance, though the optimal values of hyper-parameter might differ as predicted by theory. In all, our results present new algorithmic toolkits and empirical insights to alignment practitioners.
Read more5/30/2024

0
Optimizing Language Models for Human Preferences is a Causal Inference Problem
Victoria Lin, Eli Ben-Michael, Louis-Philippe Morency
As large language models (LLMs) see greater use in academic and commercial settings, there is increasing interest in methods that allow language models to generate texts aligned with human preferences. In this paper, we present an initial exploration of language model optimization for human preferences from direct outcome datasets, where each sample consists of a text and an associated numerical outcome measuring the reader's response. We first propose that language model optimization should be viewed as a causal problem to ensure that the model correctly learns the relationship between the text and the outcome. We formalize this causal language optimization problem, and we develop a method--causal preference optimization (CPO)--that solves an unbiased surrogate objective for the problem. We further extend CPO with doubly robust CPO (DR-CPO), which reduces the variance of the surrogate objective while retaining provably strong guarantees on bias. Finally, we empirically demonstrate the effectiveness of (DR-)CPO in optimizing state-of-the-art LLMs for human preferences on direct outcome data, and we validate the robustness of DR-CPO under difficult confounding conditions.
Read more6/7/2024

0
Understanding Preference Fine-Tuning Through the Lens of Coverage
Yuda Song, Gokul Swamy, Aarti Singh, J. Andrew Bagnell, Wen Sun
Learning from human preference data has emerged as the dominant paradigm for fine-tuning large language models (LLMs). The two most common families of techniques -- online reinforcement learning (RL) such as Proximal Policy Optimization (PPO) and offline contrastive methods such as Direct Preference Optimization (DPO) -- were positioned as equivalent in prior work due to the fact that both have to start from the same offline preference dataset. To further expand our theoretical understanding of the similarities and differences between online and offline techniques for preference fine-tuning, we conduct a rigorous analysis through the lens of dataset coverage, a concept that captures how the training data covers the test distribution and is widely used in RL. We prove that a global coverage condition is both necessary and sufficient for offline contrastive methods to converge to the optimal policy, but a weaker partial coverage condition suffices for online RL methods. This separation provides one explanation of why online RL methods can perform better than offline methods, especially when the offline preference data is not diverse enough. Finally, motivated by our preceding theoretical observations, we derive a hybrid preference optimization (HyPO) algorithm that uses offline data for contrastive-based preference optimization and online data for KL regularization. Theoretically and empirically, we demonstrate that HyPO is more performant than its pure offline counterpart DPO, while still preserving its computation and memory efficiency.
Read more7/17/2024