DuetRAG: Collaborative Retrieval-Augmented Generation

0
🛸
Sign in to get full access
Overview
- Retrieval-Augmented Generation (RAG) methods aim to improve the performance of Large Language Models (LLMs) on knowledge-intensive tasks by providing relevant information from retrieved passages.
- However, existing RAG approaches can struggle with retrieving relevant knowledge, especially for complex domain questions, leading to low-quality generations.
- To address this issue, the authors propose a new framework called DuetRAG, which integrates domain fine-tuning and RAG models to improve the quality of knowledge retrieval and generation.
- The authors demonstrate that DuetRAG matches the performance of expert human researchers on the HotPot QA benchmark.
Plain English Explanation
Retrieval-Augmented Generation (RAG) methods are a way to improve the knowledge and accuracy of large language models (LLMs) by providing them with relevant information from external sources. The idea is that by combining the language modeling capabilities of LLMs with targeted information retrieval, the models can produce more factually accurate and relevant outputs, especially for knowledge-intensive tasks.
However, the authors explain that existing RAG approaches often struggle to retrieve the most relevant information, particularly for complex questions in specialized domains. This can lead to the language models generating low-quality outputs, as they are working with incomplete or irrelevant knowledge.
To solve this problem, the researchers developed a new framework called DuetRAG. The key insight behind DuetRAG is to simultaneously train the retrieval and generation components of the system, rather than treating them as separate steps. By integrating the domain-specific fine-tuning of the language model with the training of the retrieval module, the system can learn to retrieve more relevant information, which in turn leads to higher-quality generated outputs.
The authors demonstrate that this collaborative approach allows DuetRAG to match the performance of expert human researchers on the challenging HotPot QA benchmark, which tests a model's ability to answer complex, multi-hop questions that require integrating information from multiple sources.
Technical Explanation
Retrieval-Augmented Generation (RAG) methods aim to augment the input of Large Language Models (LLMs) with relevant retrieved passages, reducing factual errors in knowledge-intensive tasks. However, the authors explain that contemporary RAG approaches suffer from issues with retrieving irrelevant knowledge, especially for complex domain questions (e.g., HotPot QA), due to a lack of corresponding domain knowledge. This leads to low-quality generations.
To address this problem, the researchers propose a novel Collaborative Retrieval-Augmented Generation framework, DuetRAG. The key innovation is to simultaneously integrate the domain fine-tuning and RAG models to improve the knowledge retrieval quality, thereby enhancing the overall generation quality.
The authors evaluate DuetRAG on the HotPot QA benchmark and demonstrate that it matches the performance of expert human researchers. This suggests that the collaborative integration of the retrieval and generation components is an effective way to address the shortcomings of existing RAG approaches in complex, knowledge-intensive domains.
Critical Analysis
The paper presents a thoughtful approach to improving retrieval-augmented generation (RAG) systems, which are an important class of models for enhancing the knowledge and factual accuracy of large language models. The authors' key insight of jointly training the retrieval and generation components, rather than treating them as separate steps, is a promising direction for addressing the limitations of existing RAG methods.
One potential area for further research highlighted in the paper is the need for better techniques to handle the retrieval of relevant information for complex, domain-specific questions. While DuetRAG represents an improvement over prior RAG approaches, the authors acknowledge that there is still room for further advancements in this area.
Additionally, the paper does not provide a detailed analysis of the computational and memory requirements of the DuetRAG framework, which could be an important consideration for real-world deployment. It would be valuable to understand the trade-offs between the performance gains and the increased model complexity and resource demands.
Overall, the paper makes a valuable contribution to the field of retrieval-augmented generation and provides a solid foundation for future research in this area. Readers are encouraged to think critically about the proposed approach and consider how it might be extended or adapted to address other challenges in language modeling and knowledge-intensive tasks.
Conclusion
The Collaborative Retrieval-Augmented Generation framework, DuetRAG, proposed in this paper represents a significant advancement in the field of retrieval-augmented generation (RAG). By jointly training the retrieval and generation components of the system, DuetRAG is able to overcome the limitations of existing RAG approaches, particularly in terms of their ability to retrieve relevant information for complex, domain-specific questions.
The authors' demonstration that DuetRAG can match the performance of expert human researchers on the challenging HotPot QA benchmark is a strong validation of their approach. This suggests that the integration of domain-specific fine-tuning and RAG modeling can lead to substantial improvements in the knowledge and factual accuracy of large language models.
As the field of language modeling continues to evolve, techniques like DuetRAG will likely play an increasingly important role in enhancing the capabilities of AI systems, enabling them to tackle more complex, knowledge-intensive tasks with greater precision and reliability. The insights and methodologies presented in this paper provide a valuable contribution to this ongoing research effort.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
0
DuetRAG: Collaborative Retrieval-Augmented Generation
Dian Jiao, Li Cai, Jingsheng Huang, Wenqiao Zhang, Siliang Tang, Yueting Zhuang
Retrieval-Augmented Generation (RAG) methods augment the input of Large Language Models (LLMs) with relevant retrieved passages, reducing factual errors in knowledge-intensive tasks. However, contemporary RAG approaches suffer from irrelevant knowledge retrieval issues in complex domain questions (e.g., HotPot QA) due to the lack of corresponding domain knowledge, leading to low-quality generations. To address this issue, we propose a novel Collaborative Retrieval-Augmented Generation framework, DuetRAG. Our bootstrapping philosophy is to simultaneously integrate the domain fintuning and RAG models to improve the knowledge retrieval quality, thereby enhancing generation quality. Finally, we demonstrate DuetRAG' s matches with expert human researchers on HotPot QA.
Read more5/24/2024

0
A Survey on Retrieval-Augmented Text Generation for Large Language Models
Yizheng Huang, Jimmy Huang
Retrieval-Augmented Generation (RAG) merges retrieval methods with deep learning advancements to address the static limitations of large language models (LLMs) by enabling the dynamic integration of up-to-date external information. This methodology, focusing primarily on the text domain, provides a cost-effective solution to the generation of plausible but possibly incorrect responses by LLMs, thereby enhancing the accuracy and reliability of their outputs through the use of real-world data. As RAG grows in complexity and incorporates multiple concepts that can influence its performance, this paper organizes the RAG paradigm into four categories: pre-retrieval, retrieval, post-retrieval, and generation, offering a detailed perspective from the retrieval viewpoint. It outlines RAG's evolution and discusses the field's progression through the analysis of significant studies. Additionally, the paper introduces evaluation methods for RAG, addressing the challenges faced and proposing future research directions. By offering an organized framework and categorization, the study aims to consolidate existing research on RAG, clarify its technological underpinnings, and highlight its potential to broaden the adaptability and applications of LLMs.
Read more8/26/2024

0
Retrieval-Augmented Generation for Natural Language Processing: A Survey
Shangyu Wu, Ying Xiong, Yufei Cui, Haolun Wu, Can Chen, Ye Yuan, Lianming Huang, Xue Liu, Tei-Wei Kuo, Nan Guan, Chun Jason Xue
Large language models (LLMs) have demonstrated great success in various fields, benefiting from their huge amount of parameters that store knowledge. However, LLMs still suffer from several key issues, such as hallucination problems, knowledge update issues, and lacking domain-specific expertise. The appearance of retrieval-augmented generation (RAG), which leverages an external knowledge database to augment LLMs, makes up those drawbacks of LLMs. This paper reviews all significant techniques of RAG, especially in the retriever and the retrieval fusions. Besides, tutorial codes are provided for implementing the representative techniques in RAG. This paper further discusses the RAG training, including RAG with/without datastore update. Then, we introduce the application of RAG in representative natural language processing tasks and industrial scenarios. Finally, this paper discusses the future directions and challenges of RAG for promoting its development.
Read more7/22/2024
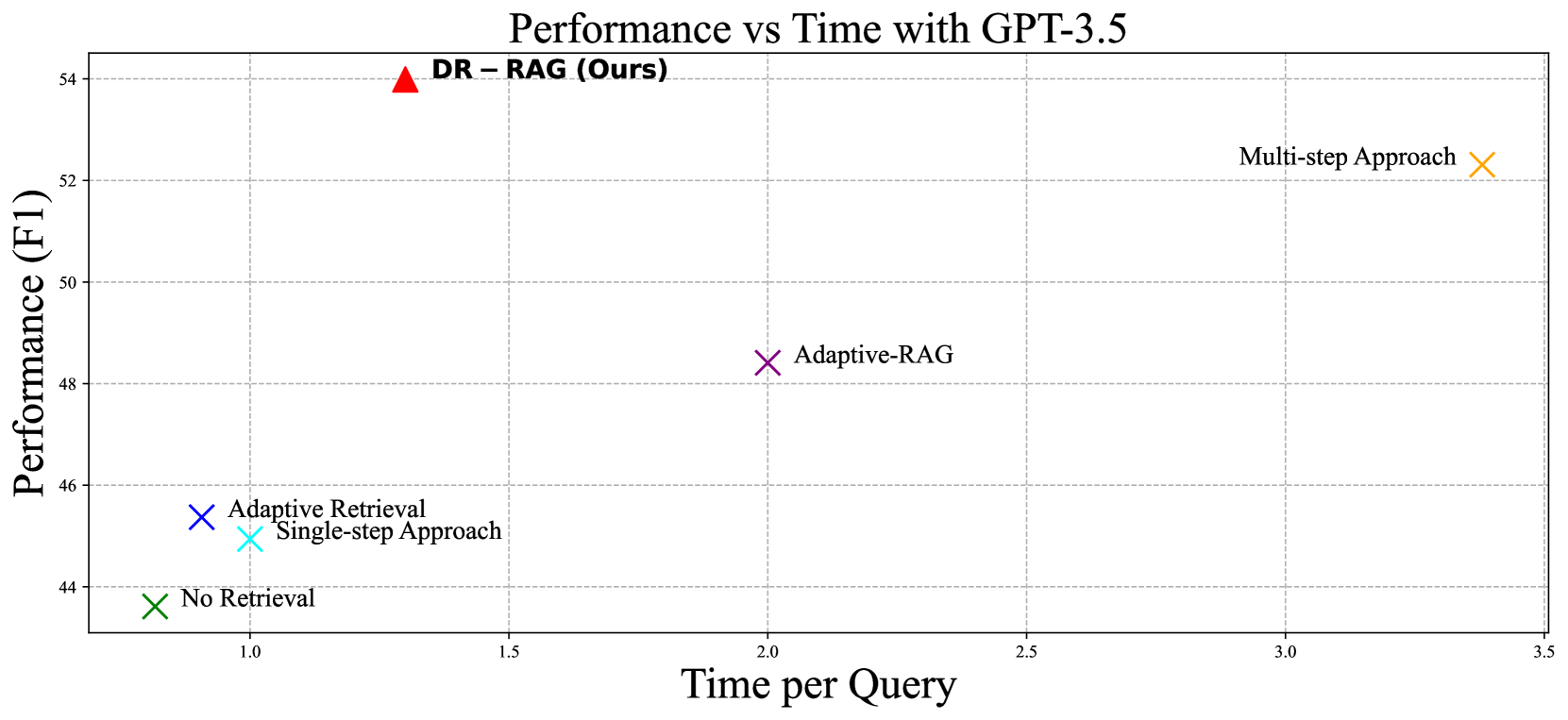
0
DR-RAG: Applying Dynamic Document Relevance to Retrieval-Augmented Generation for Question-Answering
Zijian Hei, Weiling Liu, Wenjie Ou, Juyi Qiao, Junming Jiao, Guowen Song, Ting Tian, Yi Lin
Retrieval-Augmented Generation (RAG) has recently demonstrated the performance of Large Language Models (LLMs) in the knowledge-intensive tasks such as Question-Answering (QA). RAG expands the query context by incorporating external knowledge bases to enhance the response accuracy. However, it would be inefficient to access LLMs multiple times for each query and unreliable to retrieve all the relevant documents by a single query. We have found that even though there is low relevance between some critical documents and query, it is possible to retrieve the remaining documents by combining parts of the documents with the query. To mine the relevance, a two-stage retrieval framework called Dynamic-Relevant Retrieval-Augmented Generation (DR-RAG) is proposed to improve document retrieval recall and the accuracy of answers while maintaining efficiency. Additionally, a compact classifier is applied to two different selection strategies to determine the contribution of the retrieved documents to answering the query and retrieve the relatively relevant documents. Meanwhile, DR-RAG call the LLMs only once, which significantly improves the efficiency of the experiment. The experimental results on multi-hop QA datasets show that DR-RAG can significantly improve the accuracy of the answers and achieve new progress in QA systems.
Read more6/18/2024