EFM3D: A Benchmark for Measuring Progress Towards 3D Egocentric Foundation Models

0
Sign in to get full access
Overview
- This paper introduces EFM3D, a benchmark for measuring progress towards 3D egocentric foundation models.
- 3D egocentric foundation models are AI systems that can understand and reason about the 3D world from an egocentric (first-person) perspective.
- EFM3D aims to track advancements in this field and spur further research and development.
Plain English Explanation
The paper is about a new benchmark called EFM3D, which is designed to measure progress in developing AI systems that can understand and interact with the 3D world from a first-person point of view. These types of AI systems, known as 3D egocentric foundation models, have the potential to power a wide range of applications, from augmented reality and robotics to accessibility tools.
The EFM3D benchmark provides a set of tasks and datasets that AI researchers and engineers can use to test and compare the capabilities of their 3D egocentric models. By having a common benchmark, the field can track advancements over time and identify areas that need more research and development.
The goal is to spur innovation in this important area of AI, which could lead to breakthroughs that transform how we interact with and experience the 3D world around us. The insights gained from the EFM3D benchmark could also have implications for related fields, such as 3D LFM: Lifting Foundation Models to 3D and 3D Human Pose Perception from Egocentric Stereo.
Technical Explanation
The EFM3D benchmark consists of a suite of tasks and datasets designed to test the capabilities of 3D egocentric foundation models. The tasks cover a range of challenges, including 3D object detection and segmentation, 3D scene understanding, 3D human pose estimation, and probing 3D awareness in visual foundation models.
The benchmark is built on top of existing datasets, such as EPIC-KITCHENS-100 and EgoPose, as well as newly curated datasets that capture the egocentric 3D world. The datasets provide a diverse range of environments, objects, and human interactions, allowing researchers to thoroughly evaluate the capabilities of their models.
The paper also introduces a set of evaluation metrics that go beyond traditional 2D metrics, focusing on 3D-specific measures such as 3D bounding box IoU, 3D segmentation IoU, and 3D human pose estimation error. These metrics are designed to provide a comprehensive assessment of a model's 3D understanding and reasoning abilities.
Critical Analysis
The EFM3D benchmark is a valuable contribution to the field of 3D egocentric understanding, as it provides a standardized way to measure progress and identify areas for further research. The authors have carefully curated the datasets and tasks to capture the key challenges in this domain, and the evaluation metrics seem well-suited to the task at hand.
However, the paper does not address some potential limitations of the benchmark. For example, the datasets may not fully capture the diversity of real-world environments and interactions, and the benchmark may not be able to measure certain higher-level cognitive abilities that are important for 3D egocentric understanding. Additionally, the benchmark may not be able to capture the performance of models that use novel architectures or training approaches, such as VFM3D: Releasing the Potential of Vision Foundation Models for 3D Understanding.
Further research and refinement of the EFM3D benchmark may be needed to address these challenges and ensure that it remains a useful tool for driving progress in the field of 3D egocentric understanding.
Conclusion
The EFM3D benchmark is an important step forward in the development of 3D egocentric foundation models, which have the potential to transform a wide range of applications. By providing a standardized way to measure progress and identify areas for further research, the EFM3D benchmark can help spur innovation and drive advancements in this critical field of AI.
The insights and lessons learned from the EFM3D benchmark may also have implications for related areas of AI, such as instance tracking in 3D scenes from egocentric videos, and could contribute to a broader understanding of how AI systems can interact with and reason about the 3D world around us.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
EFM3D: A Benchmark for Measuring Progress Towards 3D Egocentric Foundation Models
Julian Straub, Daniel DeTone, Tianwei Shen, Nan Yang, Chris Sweeney, Richard Newcombe
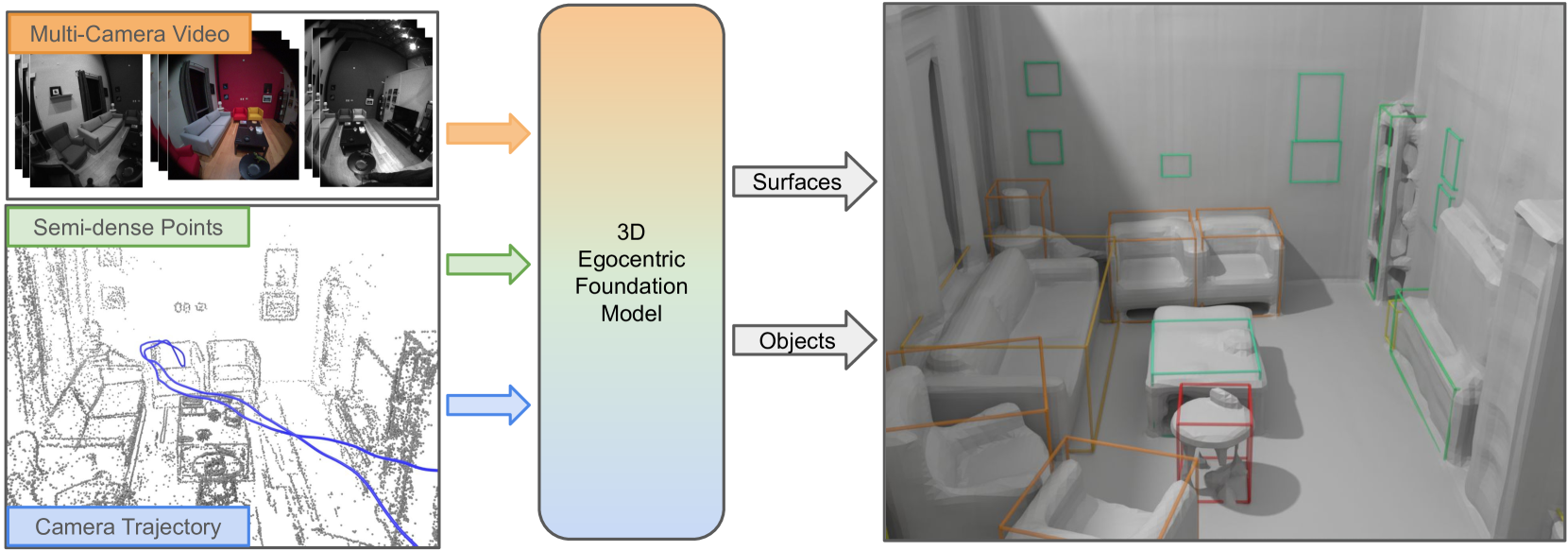
The advent of wearable computers enables a new source of context for AI that is embedded in egocentric sensor data. This new egocentric data comes equipped with fine-grained 3D location information and thus presents the opportunity for a novel class of spatial foundation models that are rooted in 3D space. To measure progress on what we term Egocentric Foundation Models (EFMs) we establish EFM3D, a benchmark with two core 3D egocentric perception tasks. EFM3D is the first benchmark for 3D object detection and surface regression on high quality annotated egocentric data of Project Aria. We propose Egocentric Voxel Lifting (EVL), a baseline for 3D EFMs. EVL leverages all available egocentric modalities and inherits foundational capabilities from 2D foundation models. This model, trained on a large simulated dataset, outperforms existing methods on the EFM3D benchmark.
Read more6/17/2024
0
VFMM3D: Releasing the Potential of Image by Vision Foundation Model for Monocular 3D Object Detection
Bonan Ding, Jin Xie, Jing Nie, Jiale Cao, Xuelong Li, Yanwei Pang
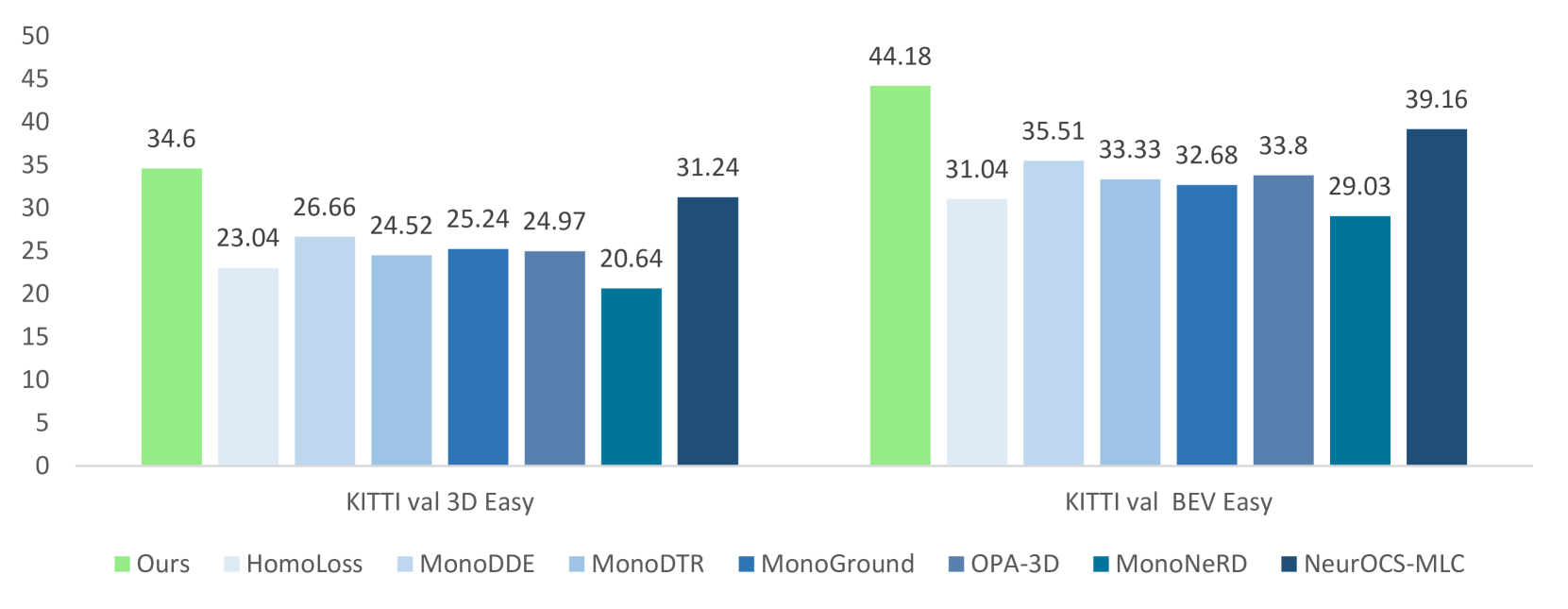
Due to its cost-effectiveness and widespread availability, monocular 3D object detection, which relies solely on a single camera during inference, holds significant importance across various applications, including autonomous driving and robotics. Nevertheless, directly predicting the coordinates of objects in 3D space from monocular images poses challenges. Therefore, an effective solution involves transforming monocular images into LiDAR-like representations and employing a LiDAR-based 3D object detector to predict the 3D coordinates of objects. The key step in this method is accurately converting the monocular image into a reliable point cloud form. In this paper, we present VFMM3D, an innovative framework that leverages the capabilities of Vision Foundation Models (VFMs) to accurately transform single-view images into LiDAR point cloud representations. VFMM3D utilizes the Segment Anything Model (SAM) and Depth Anything Model (DAM) to generate high-quality pseudo-LiDAR data enriched with rich foreground information. Specifically, the Depth Anything Model (DAM) is employed to generate dense depth maps. Subsequently, the Segment Anything Model (SAM) is utilized to differentiate foreground and background regions by predicting instance masks. These predicted instance masks and depth maps are then combined and projected into 3D space to generate pseudo-LiDAR points. Finally, any object detectors based on point clouds can be utilized to predict the 3D coordinates of objects. Comprehensive experiments are conducted on two challenging 3D object detection datasets, KITTI and Waymo. Our VFMM3D establishes a new state-of-the-art performance on both datasets. Additionally, experimental results demonstrate the generality of VFMM3D, showcasing its seamless integration into various LiDAR-based 3D object detectors.
Read more8/27/2024
0
3D-LFM: Lifting Foundation Model
Mosam Dabhi, Laszlo A. Jeni, Simon Lucey
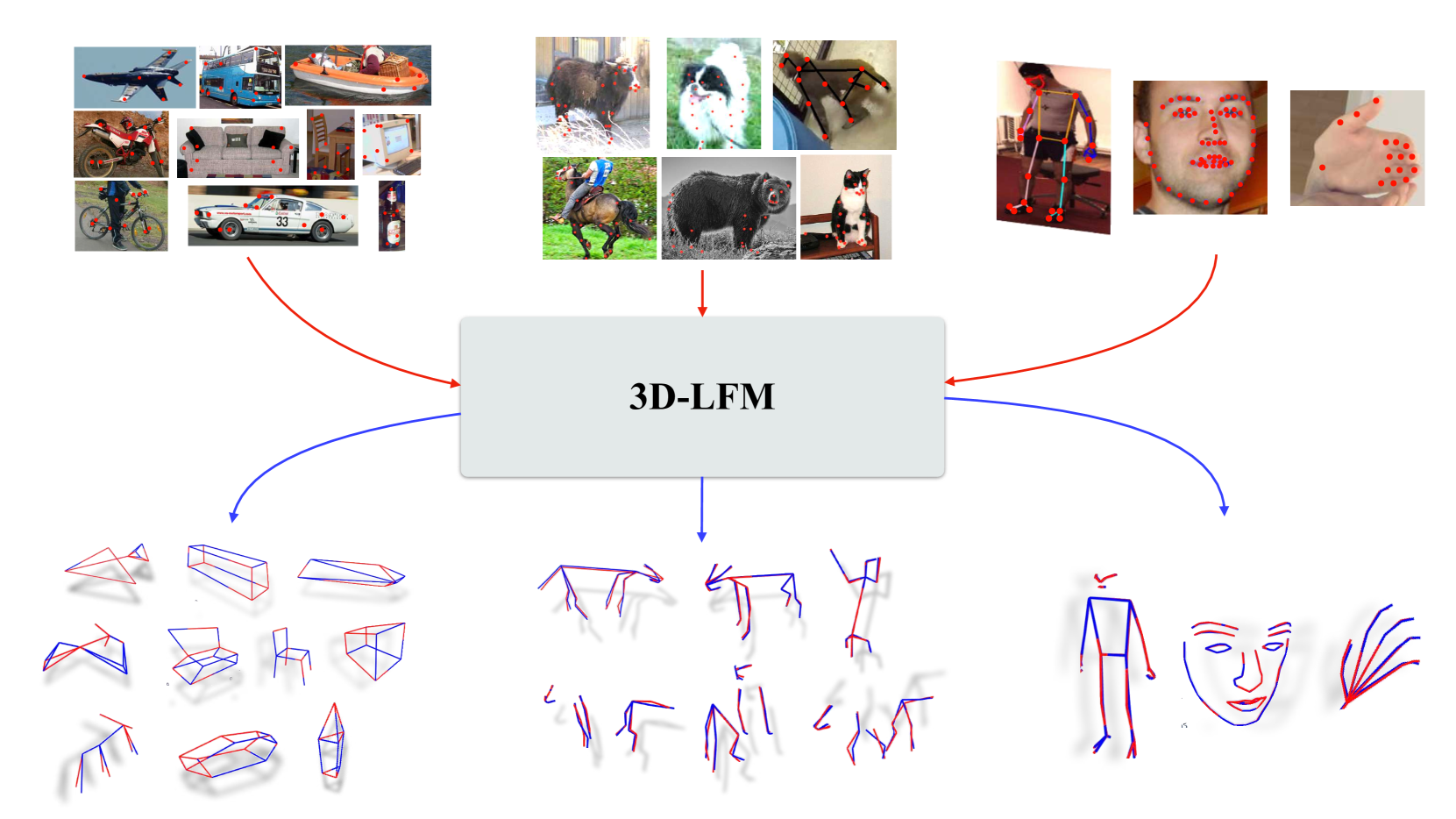
The lifting of 3D structure and camera from 2D landmarks is at the cornerstone of the entire discipline of computer vision. Traditional methods have been confined to specific rigid objects, such as those in Perspective-n-Point (PnP) problems, but deep learning has expanded our capability to reconstruct a wide range of object classes (e.g. C3DPO and PAUL) with resilience to noise, occlusions, and perspective distortions. All these techniques, however, have been limited by the fundamental need to establish correspondences across the 3D training data -- significantly limiting their utility to applications where one has an abundance of in-correspondence 3D data. Our approach harnesses the inherent permutation equivariance of transformers to manage varying number of points per 3D data instance, withstands occlusions, and generalizes to unseen categories. We demonstrate state of the art performance across 2D-3D lifting task benchmarks. Since our approach can be trained across such a broad class of structures we refer to it simply as a 3D Lifting Foundation Model (3D-LFM) -- the first of its kind.
Read more4/29/2024
🏋️
0
Empir3D : A Framework for Multi-Dimensional Point Cloud Assessment
Yash Turkar, Pranay Meshram, Christo Aluckal, Charuvahan Adhivarahan, Karthik Dantu
Advancements in sensors, algorithms, and compute hardware have made 3D perception feasible in real time. Current methods to compare and evaluate the quality of a 3D model, such as Chamfer, Hausdorff, and Earth-Mover's distance, are uni-dimensional and have limitations, including an inability to capture coverage, local variations in density and error, and sensitivity to outliers. In this paper, we propose an evaluation framework for point clouds (Empir3D) that consists of four metrics: resolution to quantify the ability to distinguish between individual parts in the point cloud, accuracy to measure registration error, coverage to evaluate the portion of missing data, and artifact score to characterize the presence of artifacts. Through detailed analysis, we demonstrate the complementary nature of each of these dimensions and the improvements they provide compared to the aforementioned uni-dimensional measures. Furthermore, we illustrate the utility of Empir3D by comparing our metrics with uni-dimensional metrics for two 3D perception applications (SLAM and point cloud completion). We believe that Empir3D advances our ability to reason about point clouds and helps better debug 3D perception applications by providing a richer evaluation of their performance. Our implementation of Empir3D, custom real-world datasets, evaluations on learning methods, and detailed documentation on how to integrate the pipeline will be made available upon publication.
Read more9/20/2024