Executable Code Actions Elicit Better LLM Agents

0
Sign in to get full access
Overview
- This paper explores how "executable code actions" can help improve the performance of large language models (LLMs) as agents.
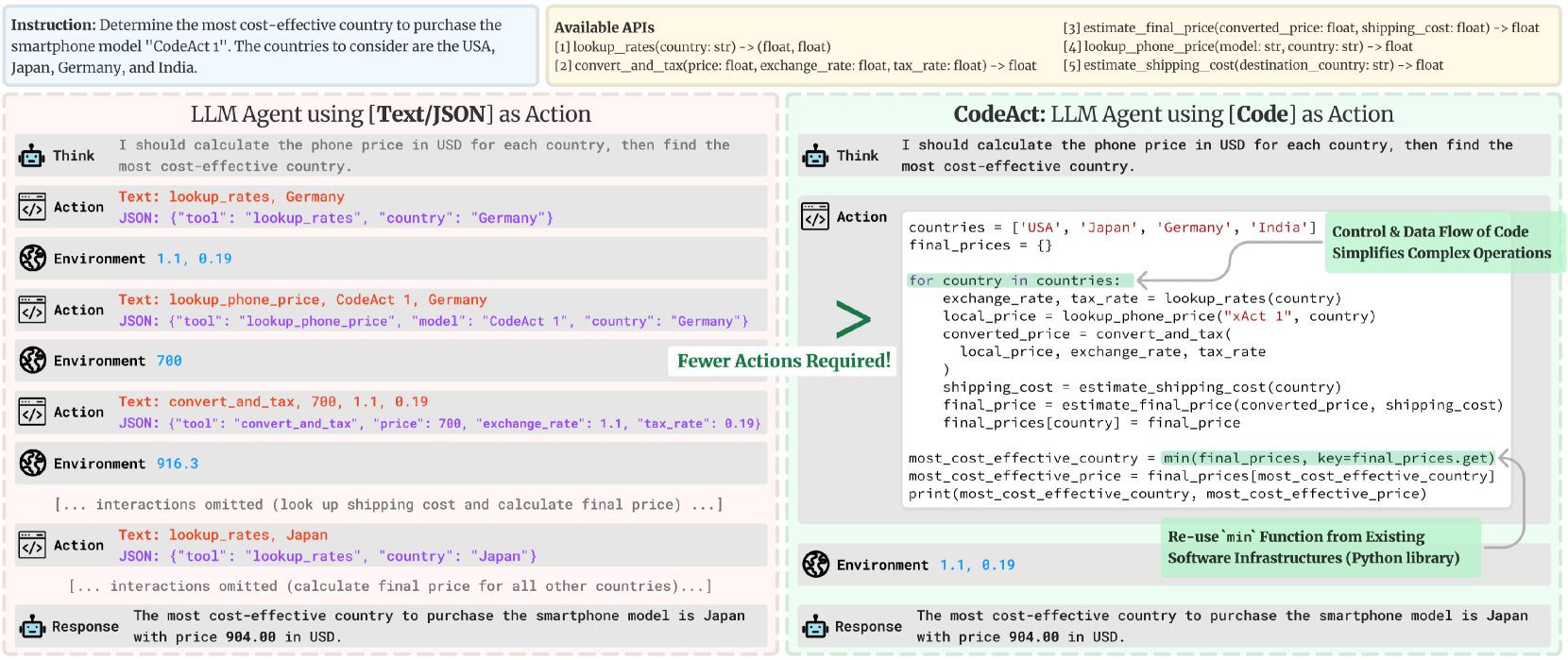
- The authors introduce a new approach called "CodeAct" that enables LLMs to perform actions through executable code, rather than just generating text.
- The results show that LLMs trained with CodeAct can outperform standard LLMs on a variety of tasks, demonstrating the benefits of incorporating executable code capabilities.
Plain English Explanation
The paper discusses a new way to make large language models (LLMs) better at completing tasks and acting as AI agents. LLMs are powerful models that can generate human-like text, but they are often limited to just producing language output. The authors propose a system called "CodeAct" that allows LLMs to do more than just generate text - it lets them take actions by running executable code.
The key idea is that by training LLMs to not only produce language but also execute code, the models can become more capable and effective at completing tasks. For example, an LLM trained with CodeAct could be asked to solve a math problem, and it would be able to generate the necessary Python code to solve the problem, rather than just describing the steps. This ability to take concrete actions, not just describe them, is what the authors believe makes LLMs better agents.
The results in the paper show that LLMs trained with CodeAct perform better than standard LLMs on a range of tasks. This suggests that the ability to execute code is an important capability that can improve the overall performance of these powerful language models.
Technical Explanation
The paper introduces a new approach called "CodeAct" that enables large language models (LLMs) to perform executable actions, rather than just generating text. In the traditional LLM setup, the model is trained to produce human-like language as output, but it has no ability to take concrete actions.
CodeAct addresses this by training the LLM to not only generate text, but also produce executable code that can be run to perform specific tasks. This is achieved by modifying the training process to include "executable code actions" in addition to the usual language modeling objective.
During training, the LLM is presented with a prompt that requires a specific action, such as solving a math problem or generating a data visualization. The model is then trained to output both a natural language description of the solution, as well as the actual code needed to implement that solution.
The authors evaluate the CodeAct approach on a variety of tasks, including math problem solving, table generation, and code summarization. The results show that LLMs trained with CodeAct consistently outperform standard LLMs that can only generate text. This indicates that the ability to execute code is an important capability that improves the overall performance of these language models when acting as agents.
Critical Analysis
The paper presents a compelling argument for the benefits of incorporating executable code actions into the training of large language models. The authors make a strong case that this capability can improve the models' ability to function as effective agents, going beyond just generating text to actually taking concrete actions.
One potential limitation of the research is that it focuses primarily on relatively narrow, well-defined tasks like math problems and table generation. It would be interesting to see how the CodeAct approach performs on more open-ended, real-world tasks that require a broader range of skills and knowledge.
Additionally, the paper does not delve deeply into the computational and training complexities introduced by the CodeAct approach. Executing code and integrating that capability into the language modeling objective likely adds significant complexity and computational overhead, which could be a practical concern for some applications.
Another area for further exploration is the interpretability and transparency of the CodeAct-trained models. Since the models are generating both text and executable code, it may be important to understand how the two outputs are related and how the models arrive at their decisions.
Overall, the research presented in this paper represents an important step forward in enhancing the capabilities of large language models, and the authors' insights open up intriguing possibilities for future work in this area.
Conclusion
This paper introduces a novel approach called "CodeAct" that enables large language models (LLMs) to not only generate human-like text, but also execute concrete actions through the production of executable code. The results demonstrate that LLMs trained with CodeAct can outperform standard LLMs on a variety of tasks, suggesting that the ability to take executable actions is a crucial capability for these models to function effectively as agents.
The implications of this research are significant, as it points to new ways of empowering LLMs to move beyond purely linguistic tasks and engage in more tangible, task-oriented behaviors. By bridging the gap between language and action, CodeAct holds the potential to unlock new frontiers in AI agent development and expand the utility of these powerful models in real-world applications.
As the field of large language models continues to evolve, the insights and techniques presented in this paper will likely serve as an important foundation for future advancements, paving the way for even more capable and versatile AI agents that can seamlessly blend language and executable capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Executable Code Actions Elicit Better LLM Agents
Xingyao Wang, Yangyi Chen, Lifan Yuan, Yizhe Zhang, Yunzhu Li, Hao Peng, Heng Ji
Large Language Model (LLM) agents, capable of performing a broad range of actions, such as invoking tools and controlling robots, show great potential in tackling real-world challenges. LLM agents are typically prompted to produce actions by generating JSON or text in a pre-defined format, which is usually limited by constrained action space (e.g., the scope of pre-defined tools) and restricted flexibility (e.g., inability to compose multiple tools). This work proposes to use executable Python code to consolidate LLM agents' actions into a unified action space (CodeAct). Integrated with a Python interpreter, CodeAct can execute code actions and dynamically revise prior actions or emit new actions upon new observations through multi-turn interactions. Our extensive analysis of 17 LLMs on API-Bank and a newly curated benchmark shows that CodeAct outperforms widely used alternatives (up to 20% higher success rate). The encouraging performance of CodeAct motivates us to build an open-source LLM agent that interacts with environments by executing interpretable code and collaborates with users using natural language. To this end, we collect an instruction-tuning dataset CodeActInstruct that consists of 7k multi-turn interactions using CodeAct. We show that it can be used with existing data to improve models in agent-oriented tasks without compromising their general capability. CodeActAgent, finetuned from Llama2 and Mistral, is integrated with Python interpreter and uniquely tailored to perform sophisticated tasks (e.g., model training) using existing libraries and autonomously self-debug.
Read more6/10/2024
⚙️
0
WorldCoder, a Model-Based LLM Agent: Building World Models by Writing Code and Interacting with the Environment
Hao Tang, Darren Key, Kevin Ellis
We give a model-based agent that builds a Python program representing its knowledge of the world based on its interactions with the environment. The world model tries to explain its interactions, while also being optimistic about what reward it can achieve. We define this optimism as a logical constraint between a program and a planner. We study our agent on gridworlds, and on task planning, finding our approach is more sample-efficient compared to deep RL, more compute-efficient compared to ReAct-style agents, and that it can transfer its knowledge across environments by editing its code.
Read more9/24/2024

0
PyBench: Evaluating LLM Agent on various real-world coding tasks
Yaolun Zhang, Yinxu Pan, Yudong Wang, Jie Cai, Zhi Zheng, Guoyang Zeng, Zhiyuan Liu
The LLM Agent, equipped with a code interpreter, is capable of automatically solving real-world coding tasks, such as data analysis and image editing. However, existing benchmarks primarily focus on either simplistic tasks, such as completing a few lines of code, or on extremely complex and specific tasks at the repository level, neither of which are representative of various daily coding tasks. To address this gap, we introduce textbf{PyBench}, a benchmark encompassing five main categories of real-world tasks, covering more than 10 types of files. Given a high-level user query and related files, the LLM Agent needs to reason and execute Python code via a code interpreter for a few turns before making a formal response to fulfill the user's requirements. Successfully addressing tasks in PyBench demands a robust understanding of various Python packages, superior reasoning capabilities, and the ability to incorporate feedback from executed code. Our evaluations indicate that current open-source LLMs are struggling with these tasks. Hence, we conduct analysis and experiments on four kinds of datasets proving that comprehensive abilities are needed for PyBench. Our fine-tuned 8B size model: textbf{PyLlama3} achieves an exciting performance on PyBench which surpasses many 33B and 70B size models. Our Benchmark, Training Dataset, and Model are available at: href{https://github.com/Mercury7353/PyBench}{https://github.com/Mercury7353/PyBench}
Read more7/25/2024

0
AutoAct: Automatic Agent Learning from Scratch for QA via Self-Planning
Shuofei Qiao, Ningyu Zhang, Runnan Fang, Yujie Luo, Wangchunshu Zhou, Yuchen Eleanor Jiang, Chengfei Lv, Huajun Chen
Language agents have achieved considerable performance on various complex question-answering tasks by planning with external tools. Despite the incessant exploration in this field, existing language agent systems still struggle with costly, non-reproducible data reliance and face the challenge of compelling a single model for multiple functions. To this end, we introduce AutoAct, an automatic agent learning framework for QA that does not rely on large-scale annotated data and synthetic planning trajectories from closed-source models (e.g., GPT-4). Given limited data with a tool library, AutoAct first automatically synthesizes planning trajectories without any assistance from humans or strong closed-source models. Then, AutoAct leverages a division-of-labor strategy to automatically differentiate based on the target task information and synthesized trajectories, producing a sub-agent group to complete the task. We conduct comprehensive experiments with different LLMs, which demonstrates that AutoAct yields better or parallel performance compared to various strong baselines. Further analysis demonstrates the effectiveness of the division-of-labor strategy, with the trajectory quality generated by AutoAct generally outperforming that of others. Code will be available at https://github.com/zjunlp/AutoAct.
Read more5/28/2024