EXTRACT: Efficient Policy Learning by Extracting Transferable Robot Skills from Offline Data

0

Sign in to get full access
Overview
- Efficient policy learning by extracting transferrable robot skills from offline data
- Focuses on developing a method to learn effective robot control policies from pre-collected offline data
- Aims to extract transferable skills that can be applied across different tasks and environments
Plain English Explanation
The paper presents a method called \method that allows robots to learn efficient control policies by extracting useful skills from existing offline data. Instead of starting from scratch, the approach seeks to identify transferable skills that can be leveraged across different tasks and environments.
This is beneficial because collecting new data for each task can be costly and time-consuming. By reusing skills learned from previous experiences, robots can plan and learn more efficiently, leading to better performance.
The key idea behind \method is to extract these transferable skills from offline datasets, without requiring the robot to actually practice the tasks. This makes the approach more sample-efficient compared to learning directly from interactions.
Technical Explanation
The \method framework consists of two main components:
-
Skill Extraction: The first step is to identify useful skills within the offline dataset. This is done by applying unsupervised skill discovery techniques to extract a set of reusable skills.
-
Policy Learning: Once the transferable skills are identified, the method uses them to learn efficient control policies for new tasks. This is achieved by framing the policy learning problem as a constrained optimization, where the policy must satisfy the extracted skill constraints.
The key technical insights behind \method are:
- Leveraging offline data to extract transferable skills, rather than learning from scratch
- Formulating policy learning as a constrained optimization problem to ensure the learned policies incorporate the extracted skills
Critical Analysis
The paper presents a promising approach for efficient policy learning, but there are a few potential limitations and areas for further research:
-
Skill Extraction Quality: The effectiveness of \method relies heavily on the quality of the extracted skills. If the unsupervised skill discovery process fails to identify truly transferable skills, the subsequent policy learning may be suboptimal.
-
Generalization Across Tasks: The paper demonstrates the effectiveness of \method on a set of related tasks, but it's unclear how well the approach would generalize to more diverse task domains. Further research is needed to assess the breadth of the extracted skills.
-
Scalability and Computational Complexity: The paper does not discuss the computational complexity of the \method framework, which could be a concern for large-scale or real-time applications.
Despite these potential limitations, the \method approach represents an important step towards more sample-efficient reinforcement learning by leveraging offline data and extracting transferable skills.
Conclusion
The \method framework presented in this paper offers a novel approach for efficient policy learning by extracting transferable robot skills from offline data. By reusing previously learned skills, the method can learn effective control policies more quickly and with fewer interactions, which has significant implications for real-world robot applications.
The key contributions of this work include the skill extraction and constrained policy learning components, which together enable robots to plan and learn more efficiently. While some potential limitations and areas for further research remain, the \method approach shows promise as a way to accelerate the deployment of capable robot systems in a wide range of domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
EXTRACT: Efficient Policy Learning by Extracting Transferable Robot Skills from Offline Data
Jesse Zhang, Minho Heo, Zuxin Liu, Erdem Biyik, Joseph J Lim, Yao Liu, Rasool Fakoor
Most reinforcement learning (RL) methods focus on learning optimal policies over low-level action spaces. While these methods can perform well in their training environments, they lack the flexibility to transfer to new tasks. Instead, RL agents that can act over useful, temporally extended skills rather than low-level actions can learn new tasks more easily. Prior work in skill-based RL either requires expert supervision to define useful skills, which is hard to scale, or learns a skill-space from offline data with heuristics that limit the adaptability of the skills, making them difficult to transfer during downstream RL. Our approach, EXTRACT, instead utilizes pre-trained vision language models to extract a discrete set of semantically meaningful skills from offline data, each of which is parameterized by continuous arguments, without human supervision. This skill parameterization allows robots to learn new tasks by only needing to learn when to select a specific skill and how to modify its arguments for the specific task. We demonstrate through experiments in sparse-reward, image-based, robot manipulation environments that EXTRACT can more quickly learn new tasks than prior works, with major gains in sample efficiency and performance over prior skill-based RL. Website at https://www.jessezhang.net/projects/extract/.
Read more9/20/2024
0
Agentic Skill Discovery
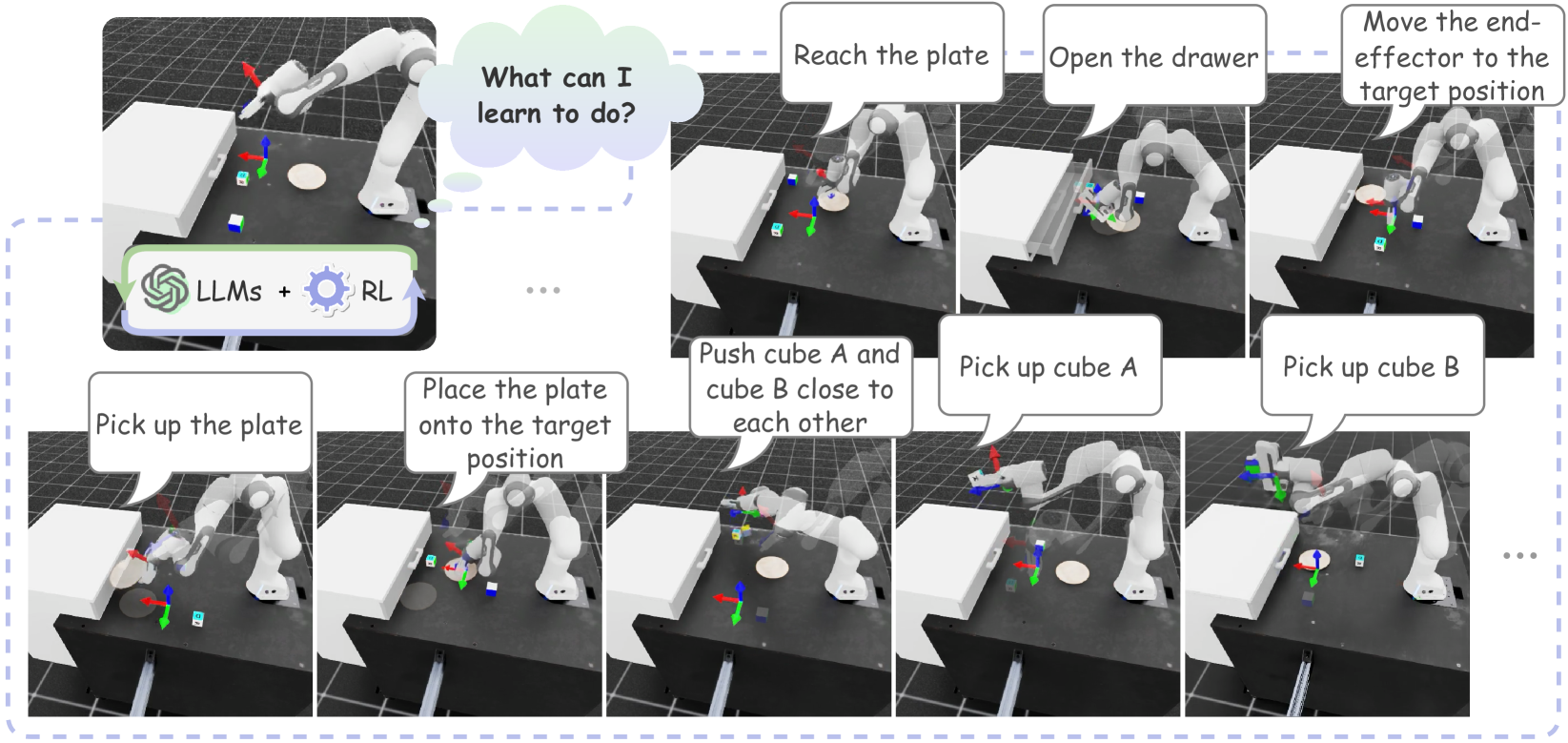
Xufeng Zhao, Cornelius Weber, Stefan Wermter
Language-conditioned robotic skills make it possible to apply the high-level reasoning of Large Language Models (LLMs) to low-level robotic control. A remaining challenge is to acquire a diverse set of fundamental skills. Existing approaches either manually decompose a complex task into atomic robotic actions in a top-down fashion, or bootstrap as many combinations as possible in a bottom-up fashion to cover a wider range of task possibilities. These decompositions or combinations, however, require an initial skill library. For example, a ``grasping'' capability can never emerge from a skill library containing only diverse ``pushing'' skills. Existing skill discovery techniques with reinforcement learning acquire skills by an exhaustive exploration but often yield non-meaningful behaviors. In this study, we introduce a novel framework for skill discovery that is entirely driven by LLMs. The framework begins with an LLM generating task proposals based on the provided scene description and the robot's configurations, aiming to incrementally acquire new skills upon task completion. For each proposed task, a series of reinforcement learning processes are initiated, utilizing reward and success determination functions sampled by the LLM to develop the corresponding policy. The reliability and trustworthiness of learned behaviors are further ensured by an independent vision-language model. We show that starting with zero skill, the skill library emerges and expands to more and more meaningful and reliable skills, enabling the robot to efficiently further propose and complete advanced tasks. Project page: url{https://agentic-skill-discovery.github.io}.
Read more8/19/2024
0
Robust Policy Learning via Offline Skill Diffusion
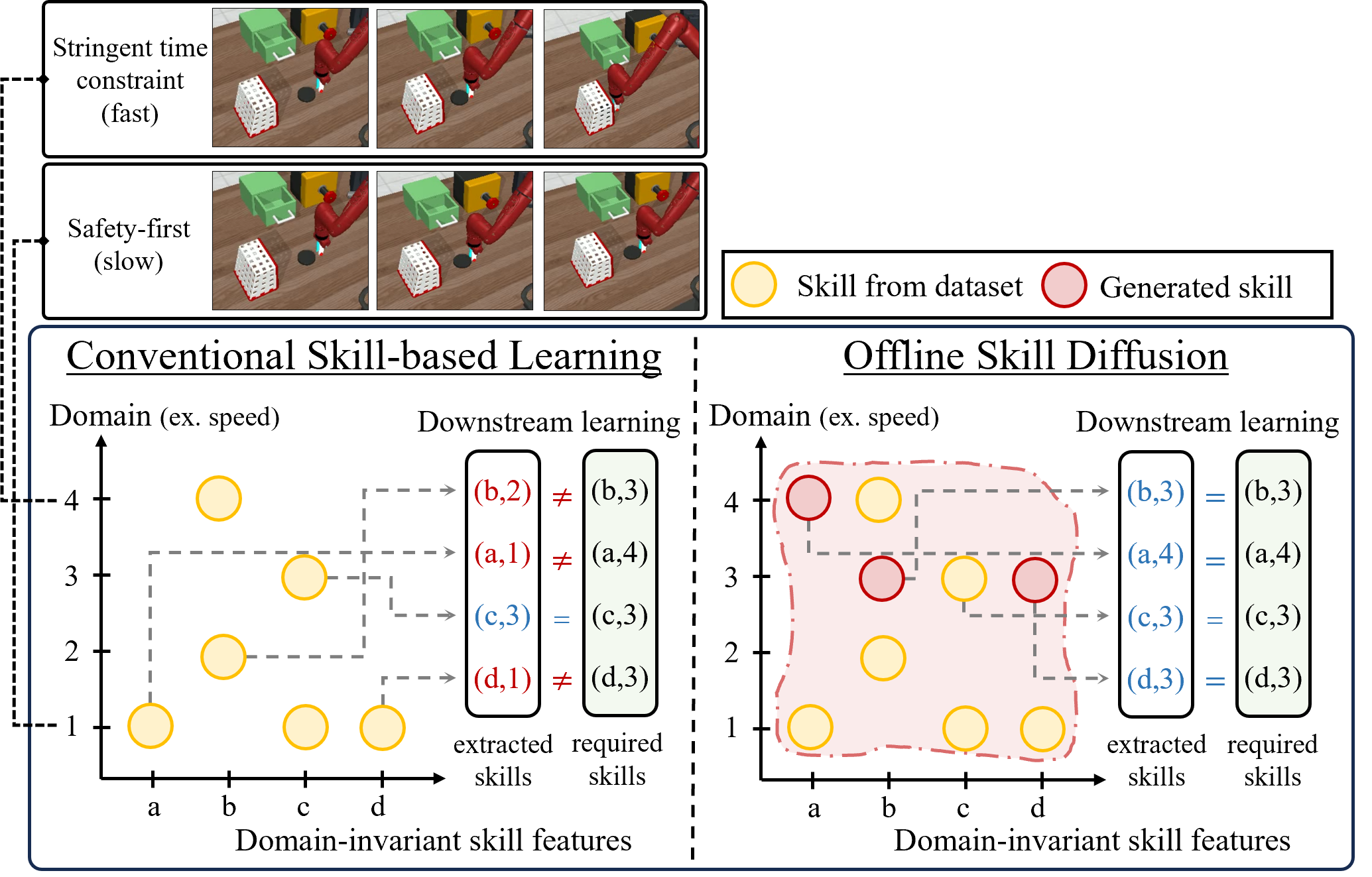
Woo Kyung Kim, Minjong Yoo, Honguk Woo
Skill-based reinforcement learning (RL) approaches have shown considerable promise, especially in solving long-horizon tasks via hierarchical structures. These skills, learned task-agnostically from offline datasets, can accelerate the policy learning process for new tasks. Yet, the application of these skills in different domains remains restricted due to their inherent dependency on the datasets, which poses a challenge when attempting to learn a skill-based policy via RL for a target domain different from the datasets' domains. In this paper, we present a novel offline skill learning framework DuSkill which employs a guided Diffusion model to generate versatile skills extended from the limited skills in datasets, thereby enhancing the robustness of policy learning for tasks in different domains. Specifically, we devise a guided diffusion-based skill decoder in conjunction with the hierarchical encoding to disentangle the skill embedding space into two distinct representations, one for encapsulating domain-invariant behaviors and the other for delineating the factors that induce domain variations in the behaviors. Our DuSkill framework enhances the diversity of skills learned offline, thus enabling to accelerate the learning procedure of high-level policies for different domains. Through experiments, we show that DuSkill outperforms other skill-based imitation learning and RL algorithms for several long-horizon tasks, demonstrating its benefits in few-shot imitation and online RL.
Read more8/23/2024

0
Practice Makes Perfect: Planning to Learn Skill Parameter Policies
Nishanth Kumar, Tom Silver, Willie McClinton, Linfeng Zhao, Stephen Proulx, Tom'as Lozano-P'erez, Leslie Pack Kaelbling, Jennifer Barry
One promising approach towards effective robot decision making in complex, long-horizon tasks is to sequence together parameterized skills. We consider a setting where a robot is initially equipped with (1) a library of parameterized skills, (2) an AI planner for sequencing together the skills given a goal, and (3) a very general prior distribution for selecting skill parameters. Once deployed, the robot should rapidly and autonomously learn to improve its performance by specializing its skill parameter selection policy to the particular objects, goals, and constraints in its environment. In this work, we focus on the active learning problem of choosing which skills to practice to maximize expected future task success. We propose that the robot should estimate the competence of each skill, extrapolate the competence (asking: how much would the competence improve through practice?), and situate the skill in the task distribution through competence-aware planning. This approach is implemented within a fully autonomous system where the robot repeatedly plans, practices, and learns without any environment resets. Through experiments in simulation, we find that our approach learns effective parameter policies more sample-efficiently than several baselines. Experiments in the real-world demonstrate our approach's ability to handle noise from perception and control and improve the robot's ability to solve two long-horizon mobile-manipulation tasks after a few hours of autonomous practice. Project website: http://ees.csail.mit.edu
Read more5/21/2024