Generalized Preference Optimization: A Unified Approach to Offline Alignment

0
👨🏫
Sign in to get full access
Overview
- This paper introduces a new family of offline preference optimization algorithms called Generalized Preference Optimization (GPO).
- GPO encompasses existing algorithms like Direct Preference Optimization (DPO), Inverse Preference Optimization (IPO), and Soft Lagrangian Constrained Optimization (SLiC) as special cases.
- The paper analyzes how offline preference optimization algorithms enforce regularization and how this relates to the KL divergence regularization intended by the canonical Reinforcement Learning from Human Feedback (RLHF) formulation.
Plain English Explanation
Offline preference optimization is a technique that allows fine-tuning large AI models directly from offline data, without the need for interactive training. This has proved effective in recent efforts to align AI systems with human preferences.
The paper introduces a new family of offline preference optimization algorithms called Generalized Preference Optimization (GPO). GPO is a flexible framework that encompasses several existing algorithms, such as Direct Preference Optimization (DPO), Inverse Preference Optimization (IPO), and Soft Lagrangian Constrained Optimization (SLiC), as special cases.
The key insight is that these different algorithms can be viewed as using different "convex functions" to define the loss function for preference optimization. By generalizing this idea, the paper introduces new variants of preference optimization algorithms that can be tailored to different use cases and requirements.
The paper also sheds light on how these offline preference optimization algorithms enforce regularization, and how this relates to the KL divergence regularization typically used in the canonical Reinforcement Learning from Human Feedback (RLHF) approach. The authors show that there are interesting connections and subtle differences between these two types of regularization.
Technical Explanation
The paper introduces a family of offline preference optimization algorithms called Generalized Preference Optimization (GPO). GPO is parameterized by a general class of convex functions, which allows it to encompass a wide range of existing algorithms as special cases.
The authors show that algorithms like Direct Preference Optimization (DPO), Inverse Preference Optimization (IPO), and Soft Lagrangian Constrained Optimization (SLiC) can be viewed as instances of the GPO framework, each using a different convex function to define the loss.
The paper also analyzes how these offline preference optimization algorithms enforce regularization, and how this relates to the KL divergence regularization intended by the canonical RLHF formulation. The authors show that there are interesting connections and subtle differences between these two approaches to regularization.
In a controlled experiment, the paper demonstrates that different GPO variants can achieve similar trade-offs between regularization and performance, though the optimal values of hyperparameters may differ as predicted by the theoretical analysis.
Critical Analysis
The paper provides a valuable contribution by unifying a range of existing offline preference optimization algorithms under the GPO framework. This offers alignment practitioners a more systematic understanding of the design choices and trade-offs involved in these approaches.
One potential limitation is that the paper focuses primarily on the theoretical analysis and does not provide extensive empirical comparisons between the different GPO variants. While the authors do show some results in a controlled setting, it would be helpful to see how these algorithms perform on a wider range of tasks and datasets.
Additionally, the paper does not delve into the practical challenges of deploying these offline preference optimization algorithms in real-world scenarios, such as the availability and quality of offline data, the scalability of the algorithms, or the potential for unintended consequences or negative societal impacts.
Further research could explore the robustness and generalization of GPO algorithms, as well as investigate their performance in more complex and realistic settings. Addressing these aspects could provide valuable insights for alignment practitioners seeking to deploy these techniques in production systems.
Conclusion
This paper introduces a new family of offline preference optimization algorithms called Generalized Preference Optimization (GPO), which offers a unified view of several existing algorithms. The GPO framework sheds light on how these offline algorithms enforce regularization and how this relates to the KL divergence regularization used in the canonical RLHF approach.
The paper's theoretical analysis and experiments provide new algorithmic toolkits and empirical insights that can help alignment practitioners better understand the trade-offs and design choices involved in offline preference optimization. While the paper focuses on the technical details, further research is needed to explore the practical challenges and real-world implications of deploying these techniques in production AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👨🏫
0
Generalized Preference Optimization: A Unified Approach to Offline Alignment
Yunhao Tang, Zhaohan Daniel Guo, Zeyu Zheng, Daniele Calandriello, R'emi Munos, Mark Rowland, Pierre Harvey Richemond, Michal Valko, Bernardo 'Avila Pires, Bilal Piot
Offline preference optimization allows fine-tuning large models directly from offline data, and has proved effective in recent alignment practices. We propose generalized preference optimization (GPO), a family of offline losses parameterized by a general class of convex functions. GPO enables a unified view over preference optimization, encompassing existing algorithms such as DPO, IPO and SLiC as special cases, while naturally introducing new variants. The GPO framework also sheds light on how offline algorithms enforce regularization, through the design of the convex function that defines the loss. Our analysis and experiments reveal the connections and subtle differences between the offline regularization and the KL divergence regularization intended by the canonical RLHF formulation. In a controlled setting akin to Gao et al 2023, we also show that different GPO variants achieve similar trade-offs between regularization and performance, though the optimal values of hyper-parameter might differ as predicted by theory. In all, our results present new algorithmic toolkits and empirical insights to alignment practitioners.
Read more5/30/2024
0
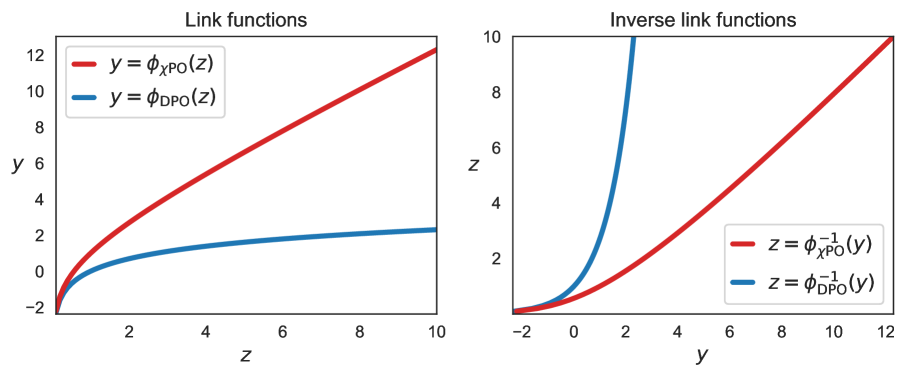
Correcting the Mythos of KL-Regularization: Direct Alignment without Overparameterization via Chi-squared Preference Optimization
Audrey Huang, Wenhao Zhan, Tengyang Xie, Jason D. Lee, Wen Sun, Akshay Krishnamurthy, Dylan J. Foster
Language model alignment methods, such as reinforcement learning from human feedback (RLHF), have led to impressive advances in language model capabilities, but existing techniques are limited by a widely observed phenomenon known as overoptimization, where the quality of the language model plateaus or degrades over the course of the alignment process. Overoptimization is often attributed to overfitting to an inaccurate reward model, and while it can be mitigated through online data collection, this is infeasible in many settings. This raises a fundamental question: Do existing offline alignment algorithms make the most of the data they have, or can their sample-efficiency be improved further? We address this question with a new algorithm for offline alignment, $chi^2$-Preference Optimization ($chi$PO). $chi$PO is a one-line change to Direct Preference Optimization (DPO; Rafailov et al., 2023), which only involves modifying the logarithmic link function in the DPO objective. Despite this minimal change, $chi$PO implicitly implements the principle of pessimism in the face of uncertainty via regularization with the $chi^2$-divergence -- which quantifies uncertainty more effectively than KL-regularization -- and provably alleviates overoptimization, achieving sample-complexity guarantees based on single-policy concentrability -- the gold standard in offline reinforcement learning. $chi$PO's simplicity and strong guarantees make it the first practical and general-purpose offline alignment algorithm that is provably robust to overoptimization.
Read more7/23/2024

0
Understanding Preference Fine-Tuning Through the Lens of Coverage
Yuda Song, Gokul Swamy, Aarti Singh, J. Andrew Bagnell, Wen Sun
Learning from human preference data has emerged as the dominant paradigm for fine-tuning large language models (LLMs). The two most common families of techniques -- online reinforcement learning (RL) such as Proximal Policy Optimization (PPO) and offline contrastive methods such as Direct Preference Optimization (DPO) -- were positioned as equivalent in prior work due to the fact that both have to start from the same offline preference dataset. To further expand our theoretical understanding of the similarities and differences between online and offline techniques for preference fine-tuning, we conduct a rigorous analysis through the lens of dataset coverage, a concept that captures how the training data covers the test distribution and is widely used in RL. We prove that a global coverage condition is both necessary and sufficient for offline contrastive methods to converge to the optimal policy, but a weaker partial coverage condition suffices for online RL methods. This separation provides one explanation of why online RL methods can perform better than offline methods, especially when the offline preference data is not diverse enough. Finally, motivated by our preceding theoretical observations, we derive a hybrid preference optimization (HyPO) algorithm that uses offline data for contrastive-based preference optimization and online data for KL regularization. Theoretically and empirically, we demonstrate that HyPO is more performant than its pure offline counterpart DPO, while still preserving its computation and memory efficiency.
Read more7/17/2024
1
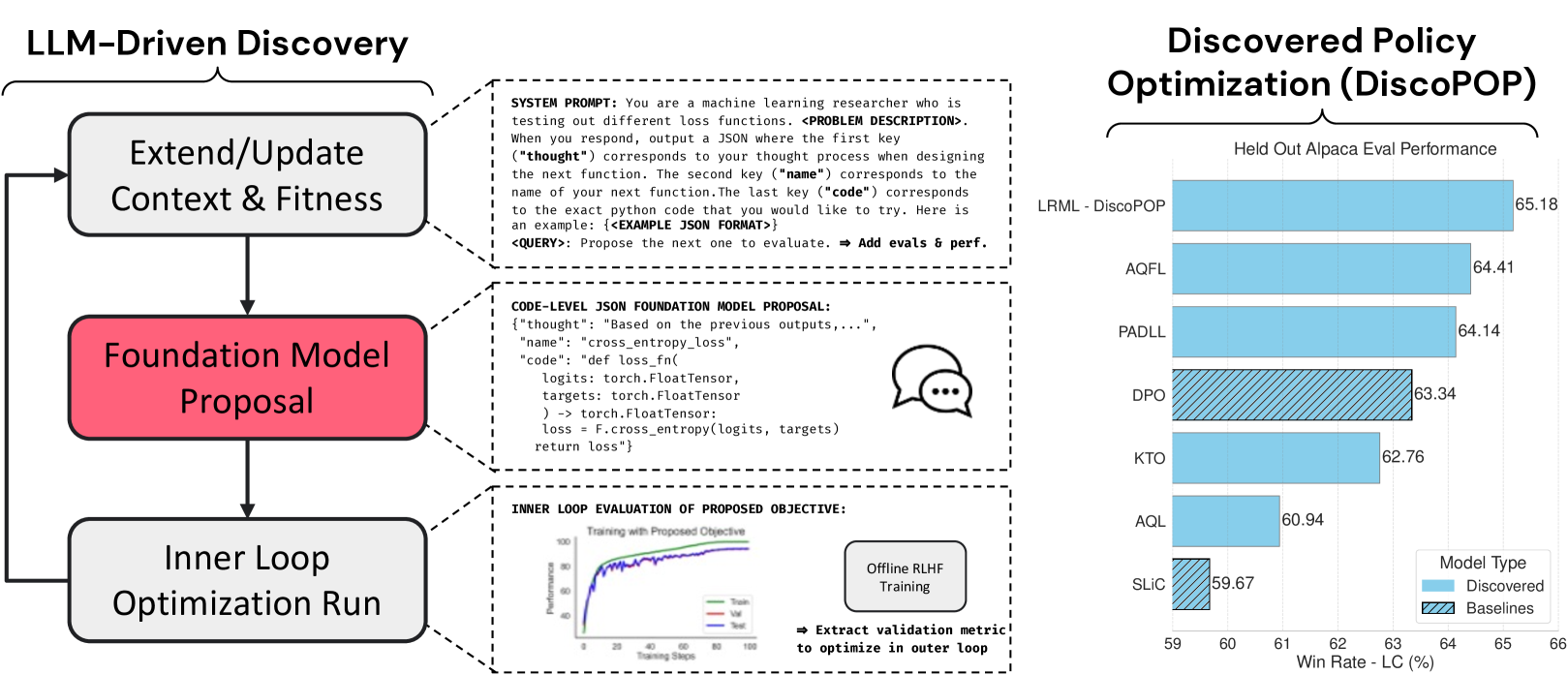
Discovering Preference Optimization Algorithms with and for Large Language Models
Chris Lu, Samuel Holt, Claudio Fanconi, Alex J. Chan, Jakob Foerster, Mihaela van der Schaar, Robert Tjarko Lange
Offline preference optimization is a key method for enhancing and controlling the quality of Large Language Model (LLM) outputs. Typically, preference optimization is approached as an offline supervised learning task using manually-crafted convex loss functions. While these methods are based on theoretical insights, they are inherently constrained by human creativity, so the large search space of possible loss functions remains under explored. We address this by performing LLM-driven objective discovery to automatically discover new state-of-the-art preference optimization algorithms without (expert) human intervention. Specifically, we iteratively prompt an LLM to propose and implement new preference optimization loss functions based on previously-evaluated performance metrics. This process leads to the discovery of previously-unknown and performant preference optimization algorithms. The best performing of these we call Discovered Preference Optimization (DiscoPOP), a novel algorithm that adaptively blends logistic and exponential losses. Experiments demonstrate the state-of-the-art performance of DiscoPOP and its successful transfer to held-out tasks.
Read more9/4/2024