Hype, Sustainability, and the Price of the Bigger-is-Better Paradigm in AI

0

Sign in to get full access
Overview
- The paper examines the growing trend in AI of focusing on scale and size, often at the expense of other important factors like sustainability and environmental impact.
- It argues that the "bigger-is-better" paradigm in AI has become a dominant narrative, shaping research priorities and industrial practices in problematic ways.
- The paper aims to highlight the need for a more balanced approach that considers the long-term viability and responsible development of AI systems.
Plain English Explanation
The paper discusses a concerning trend in the AI field where the focus has shifted too heavily towards making bigger and more powerful AI models, often at the expense of other important considerations. This "bigger-is-better" mindset has become the dominant narrative, influencing the priorities of both researchers and industry.
The authors argue that this narrow focus on scale and size can be problematic in the long run. While impressive breakthroughs have been achieved with these massive AI systems, there are significant concerns about their sustainability, environmental impact, and overall societal implications that need to be addressed.
The paper aims to encourage a more balanced approach to AI development, one that considers not just the raw capabilities of these systems, but also their long-term viability, energy efficiency, and responsible deployment. By broadening the scope of AI research and development, the authors hope to promote a more sustainable and holistic path forward for the field.
Technical Explanation
The paper starts by examining the rise of the "bigger-is-better" paradigm in AI, where the pursuit of ever-larger models with greater capabilities has become the dominant narrative. The authors trace this trend back to the success of large language models like GPT-3, which have demonstrated impressive performance on a wide range of tasks.
This focus on scale has led to a phenomenon the authors call "hype," where the narrative of "bigger is better" has become entrenched in the AI community, shaping research priorities and industrial practices. The paper delves into the potential downsides of this approach, including concerns about energy consumption, environmental impact, and the long-term sustainability of these systems.
The authors also explore the broader societal implications of this "bigger-is-better" paradigm, arguing that it may exacerbate issues of inequality and marginalization, as access to the most advanced AI systems becomes concentrated in the hands of a few powerful entities.
To address these concerns, the paper advocates for a more balanced and holistic approach to AI development, one that considers not just raw capabilities but also environmental impact, energy efficiency, and responsible deployment. The authors suggest that a shift in mindset, away from the pursuit of scale for its own sake, could lead to more sustainable and equitable AI systems that better serve the needs of society.
Critical Analysis
The paper raises valid concerns about the potential downsides of the "bigger-is-better" paradigm in AI, particularly in terms of sustainability, environmental impact, and social implications. The authors make a compelling case that the field has become too narrowly focused on scale and size, often at the expense of other crucial factors.
One strength of the paper is its nuanced approach, acknowledging the impressive achievements enabled by large-scale AI systems while also highlighting the need for a more balanced perspective. The authors do not dismiss the value of these systems, but rather call for a more holistic consideration of their long-term viability and responsible development.
However, the paper could have delved deeper into some of the specific technical and practical challenges associated with the sustainability of these systems, such as the energy demands of training and inference, the e-waste generated by frequent model updates, and the logistical difficulties of deploying and maintaining these large-scale AI systems in diverse contexts.
Additionally, the paper could have explored in more detail the potential societal impacts of the "bigger-is-better" paradigm, such as the risk of AI-driven job displacement, the exacerbation of digital divides, and the ethical implications of deploying powerful AI systems in sensitive domains like healthcare, criminal justice, and social services.
Overall, the paper provides a thought-provoking and necessary critique of the current trajectory of AI development, and it serves as a call to action for the AI community to embrace a more balanced and sustainable approach to innovation.
Conclusion
The paper makes a compelling argument that the AI field has become overly focused on the pursuit of scale and size, often at the expense of other important factors like sustainability, environmental impact, and responsible deployment. The authors warn that this "bigger-is-better" paradigm has become the dominant narrative, shaping research priorities and industrial practices in problematic ways.
By highlighting the potential downsides of this approach, the paper encourages the AI community to adopt a more balanced and holistic perspective, one that considers not just raw capabilities but also long-term viability, energy efficiency, and the broader societal implications of these powerful systems. Ultimately, the authors call for a shift in mindset that prioritizes sustainable and equitable AI development, a path that may be more challenging but promises to deliver more responsible and impactful innovations in the long run.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!Hype, Sustainability, and the Price of the Bigger-is-Better Paradigm in AI
Gael Varoquaux, Alexandra Sasha Luccioni, Meredith Whittaker
With the growing attention and investment in recent AI approaches such as large language models, the narrative that the larger the AI system the more valuable, powerful and interesting it is is increasingly seen as common sense. But what is this assumption based on, and how are we measuring value, power, and performance? And what are the collateral consequences of this race to ever-increasing scale? Here, we scrutinize the current scaling trends and trade-offs across multiple axes and refute two common assumptions underlying the 'bigger-is-better' AI paradigm: 1) that improved performance is a product of increased scale, and 2) that all interesting problems addressed by AI require large-scale models. Rather, we argue that this approach is not only fragile scientifically, but comes with undesirable consequences. First, it is not sustainable, as its compute demands increase faster than model performance, leading to unreasonable economic requirements and a disproportionate environmental footprint. Second, it implies focusing on certain problems at the expense of others, leaving aside important applications, e.g. health, education, or the climate. Finally, it exacerbates a concentration of power, which centralizes decision-making in the hands of a few actors while threatening to disempower others in the context of shaping both AI research and its applications throughout society.
Read more9/24/2024
🔮
0
Scaling Laws Do Not Scale
Fernando Diaz, Michael Madaio
Recent work has advocated for training AI models on ever-larger datasets, arguing that as the size of a dataset increases, the performance of a model trained on that dataset will correspondingly increase (referred to as scaling laws). In this paper, we draw on literature from the social sciences and machine learning to critically interrogate these claims. We argue that this scaling law relationship depends on metrics used to measure performance that may not correspond with how different groups of people perceive the quality of models' output. As the size of datasets used to train large AI models grows and AI systems impact ever larger groups of people, the number of distinct communities represented in training or evaluation datasets grows. It is thus even more likely that communities represented in datasets may have values or preferences not reflected in (or at odds with) the metrics used to evaluate model performance in scaling laws. Different communities may also have values in tension with each other, leading to difficult, potentially irreconcilable choices about metrics used for model evaluations -- threatening the validity of claims that model performance is improving at scale. We end the paper with implications for AI development: that the motivation for scraping ever-larger datasets may be based on fundamentally flawed assumptions about model performance. That is, models may not, in fact, continue to improve as the datasets get larger -- at least not for all people or communities impacted by those models. We suggest opportunities for the field to rethink norms and values in AI development, resisting claims for universality of large models, fostering more local, small-scale designs, and other ways to resist the impetus towards scale in AI.
Read more7/30/2024
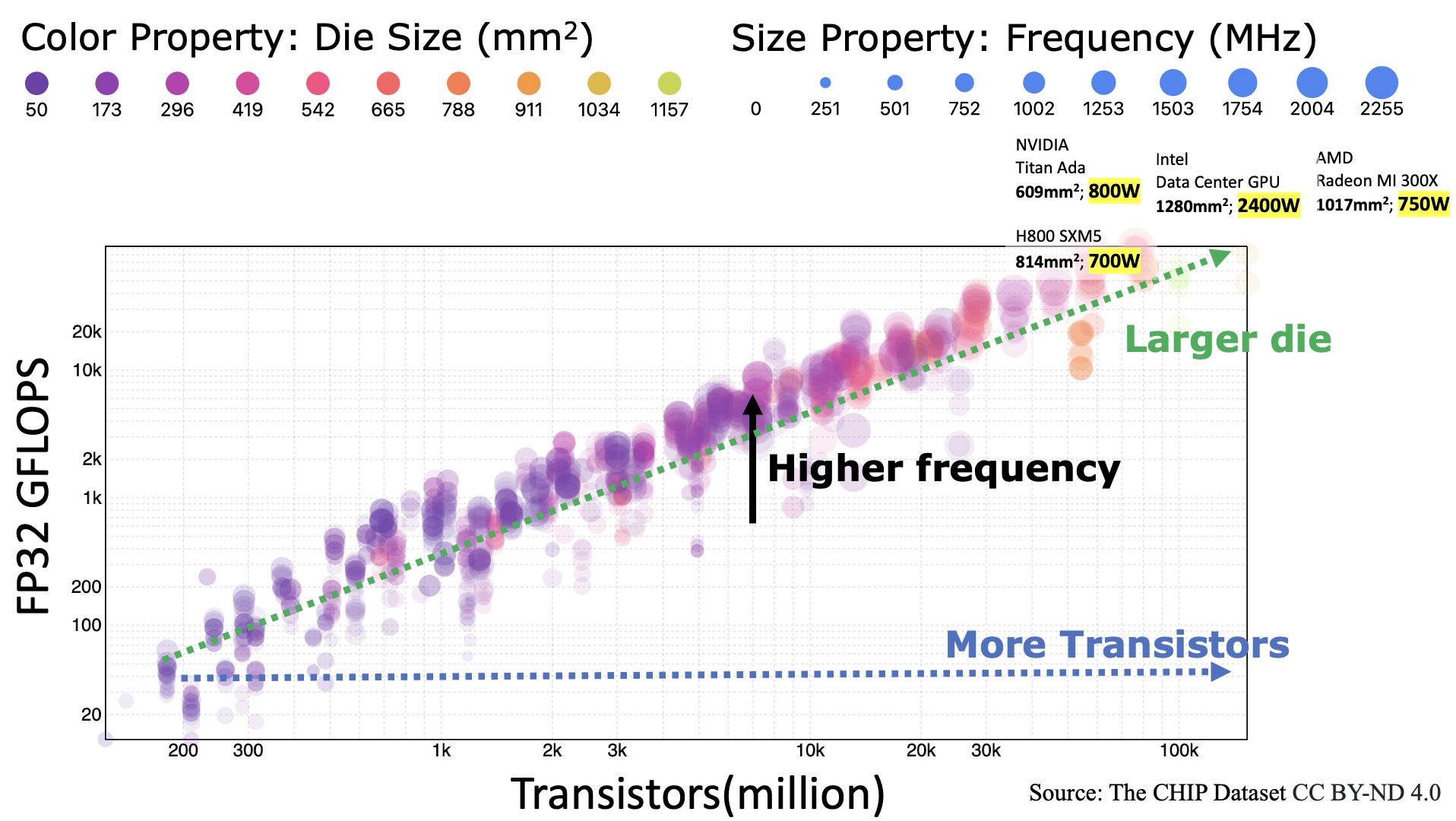
0
Beyond Efficiency: Scaling AI Sustainably
Carole-Jean Wu, Bilge Acun, Ramya Raghavendra, Kim Hazelwood
Barroso's seminal contributions in energy-proportional warehouse-scale computing launched an era where modern datacenters have become more energy efficient and cost effective than ever before. At the same time, modern AI applications have driven ever-increasing demands in computing, highlighting the importance of optimizing efficiency across the entire deep learning model development cycle. This paper characterizes the carbon impact of AI, including both operational carbon emissions from training and inference as well as embodied carbon emissions from datacenter construction and hardware manufacturing. We highlight key efficiency optimization opportunities for cutting-edge AI technologies, from deep learning recommendation models to multi-modal generative AI tasks. To scale AI sustainably, we must also go beyond efficiency and optimize across the life cycle of computing infrastructures, from hardware manufacturing to datacenter operations and end-of-life processing for the hardware.
Read more6/26/2024
0
Inverse Scaling: When Bigger Isn't Better
Ian R. McKenzie, Alexander Lyzhov, Michael Pieler, Alicia Parrish, Aaron Mueller, Ameya Prabhu, Euan McLean, Aaron Kirtland, Alexis Ross, Alisa Liu, Andrew Gritsevskiy, Daniel Wurgaft, Derik Kauffman, Gabriel Recchia, Jiacheng Liu, Joe Cavanagh, Max Weiss, Sicong Huang, The Floating Droid, Tom Tseng, Tomasz Korbak, Xudong Shen, Yuhui Zhang, Zhengping Zhou, Najoung Kim, Samuel R. Bowman, Ethan Perez
Work on scaling laws has found that large language models (LMs) show predictable improvements to overall loss with increased scale (model size, training data, and compute). Here, we present evidence for the claim that LMs may show inverse scaling, or worse task performance with increased scale, e.g., due to flaws in the training objective and data. We present empirical evidence of inverse scaling on 11 datasets collected by running a public contest, the Inverse Scaling Prize, with a substantial prize pool. Through analysis of the datasets, along with other examples found in the literature, we identify four potential causes of inverse scaling: (i) preference to repeat memorized sequences over following in-context instructions, (ii) imitation of undesirable patterns in the training data, (iii) tasks containing an easy distractor task which LMs could focus on, rather than the harder real task, and (iv) correct but misleading few-shot demonstrations of the task. We release the winning datasets at https://inversescaling.com/data to allow for further investigation of inverse scaling. Our tasks have helped drive the discovery of U-shaped and inverted-U scaling trends, where an initial trend reverses, suggesting that scaling trends are less reliable at predicting the behavior of larger-scale models than previously understood. Overall, our results suggest that there are tasks for which increased model scale alone may not lead to progress, and that more careful thought needs to go into the data and objectives for training language models.
Read more5/14/2024