InferCept: Efficient Intercept Support for Augmented Large Language Model Inference

0
Sign in to get full access
Overview
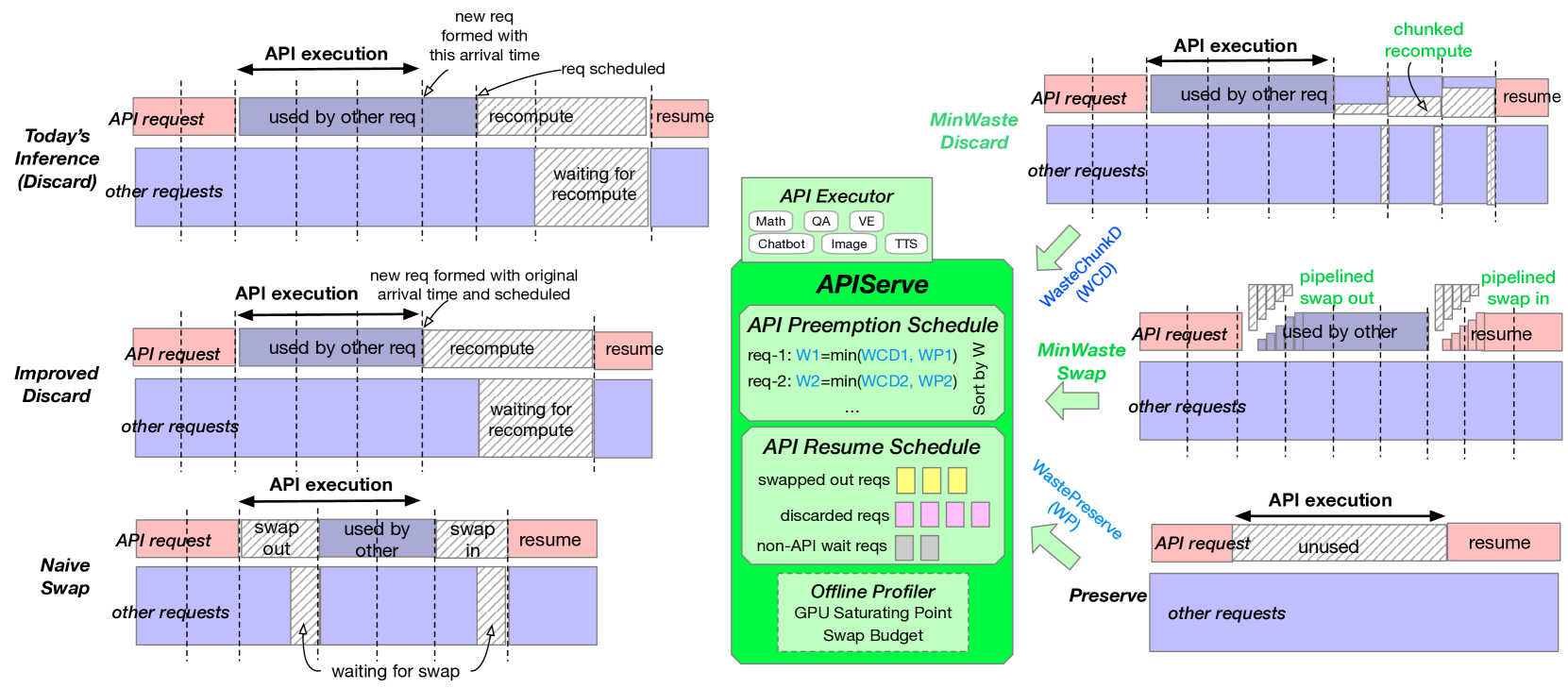
• This paper presents APIServe, a system that efficiently supports the use of APIs within large language model (LLM) inference.
• The paper discusses how API-augmented LLMs can enhance the capabilities of LLMs by allowing them to access external information and services, and introduces the challenges involved in efficiently integrating APIs into the LLM inference process.
• The paper proposes the APIServe system as a solution to these challenges, and evaluates its performance and efficiency in several real-world use cases.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can generate human-like text on a wide range of topics. However, their knowledge is limited to what was included in their training data. API-augmented LLMs can overcome this limitation by allowing the LLM to access external information and services through APIs (Application Programming Interfaces).
For example, an API-augmented LLM could be used to answer questions about current events by querying a news API, or to provide product recommendations by accessing an e-commerce API. This can significantly enhance the capabilities of the LLM, but it also introduces new challenges in terms of efficiently integrating the API calls into the LLM inference process.
The APIServe system proposed in this paper is designed to address these challenges. It provides a way to seamlessly incorporate API calls into the LLM inference process, while optimizing for performance and efficiency. This allows the LLM to access external information and services without significantly slowing down the inference process.
The paper evaluates the performance of APIServe in several real-world use cases, such as question answering and product recommendation, and demonstrates that it can significantly improve the efficiency and effectiveness of API-augmented LLMs.
Technical Explanation
The APIServe system proposed in this paper is designed to efficiently integrate API calls into the LLM inference process. It does this by introducing several key components:
-
API Proxy: This component intercepts API calls made by the LLM during inference and routes them to the appropriate external service, while also caching responses to reduce redundant API calls.
-
Inference Scheduler: This component dynamically schedules API calls and LLM inference steps to optimize for overall latency and throughput, taking into account factors like API call latency and the dependency between API calls and LLM inference.
-
Asynchronous Execution: APIServe leverages asynchronous execution to overlap API calls and LLM inference, further improving efficiency.
The paper evaluates the performance of APIServe in several real-world use cases, including question answering and product recommendation. The results show that APIServe can significantly improve the efficiency and effectiveness of API-augmented LLMs, reducing latency and increasing throughput compared to baseline approaches.
Critical Analysis
The paper does a thorough job of addressing the challenges involved in efficiently integrating APIs into the LLM inference process. The APIServe system appears to be a well-designed solution that effectively leverages various optimization techniques to improve performance.
However, the paper does not delve deeply into the potential limitations of the approach. For example, it does not discuss how APIServe might handle failure scenarios, such as when an API call fails or returns unexpected results. Additionally, the paper does not explore the scalability of the system, or how it might perform under higher loads or with a more diverse set of APIs.
Furthermore, the paper could have benefited from a more detailed discussion of the potential trade-offs and design decisions involved in implementing APIServe. For instance, the paper does not explore how the various optimization techniques, such as caching and asynchronous execution, might impact the overall complexity and maintainability of the system.
Despite these minor limitations, the APIServe system appears to be a valuable contribution to the field of efficient LLM inference, and the paper provides a solid foundation for further research and development in this area.
Conclusion
The APIServe system proposed in this paper represents a significant advancement in the field of efficient API-augmented LLM inference. By addressing the challenges of integrating APIs into the LLM inference process, APIServe enables LLMs to access external information and services, significantly enhancing their capabilities.
The paper's evaluation of APIServe in real-world use cases demonstrates the system's effectiveness in improving the efficiency and performance of API-augmented LLMs. While the paper could have delved deeper into the system's limitations and trade-offs, it provides a valuable contribution to the ongoing research and development in this important area of AI.
As LLMs continue to play an increasingly important role in a wide range of applications, the ability to efficiently leverage external information and services through APIs will become increasingly crucial. The APIServe system represents an important step towards realizing the full potential of API-augmented LLMs.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
InferCept: Efficient Intercept Support for Augmented Large Language Model Inference
Reyna Abhyankar, Zijian He, Vikranth Srivatsa, Hao Zhang, Yiying Zhang
Large language models are increasingly integrated with external environments, tools, and agents like ChatGPT plugins to extend their capability beyond language-centric tasks. However, today's LLM inference systems are designed for standalone LLMs. They treat each external interaction as the end of LLM generation and form a new request when the interaction finishes, causing unnecessary recomputation of already computed contexts, which accounts for 37-40% of total model forwarding time. This paper presents InferCept, the first LLM inference framework targeting augmented LLMs and supporting the efficient interception of LLM generation. InferCept minimizes the GPU resource waste caused by LLM interceptions and dedicates saved memory for serving more requests. InferCept improves the overall serving throughput by 1.6x-2x and completes 2x more requests per second compared to the state-of-the-art LLM inference systems.
Read more5/31/2024
0
LiveMind: Low-latency Large Language Models with Simultaneous Inference
Chuangtao Chen, Grace Li Zhang, Xunzhao Yin, Cheng Zhuo, Ulf Schlichtmann, Bing Li
In this paper, we introduce a novel low-latency inference framework for large language models (LLMs) inference which enables LLMs to perform inferences with incomplete prompts. By reallocating computational processes to prompt input phase, we achieve a substantial reduction in latency, thereby significantly enhancing the interactive experience for users of LLMs. The framework adeptly manages the visibility of the streaming prompt to the model, allowing it to infer from incomplete prompts or await additional prompts. Compared with traditional inference methods that utilize complete prompts, our approach demonstrates an average reduction of 59% in response latency on the MMLU-Pro dataset, while maintaining comparable accuracy. Additionally, our framework facilitates collaborative inference and output across different models. By employing an LLM for inference and a small language model (SLM) for output, we achieve an average 68% reduction in response latency, alongside a 5.5% improvement in accuracy on the MMLU-Pro dataset compared with the SLM baseline. For long prompts exceeding 20 sentences, the response latency can be reduced by up to 93%.
Read more6/21/2024
🤯
0
New!Fast Distributed Inference Serving for Large Language Models
Bingyang Wu, Yinmin Zhong, Zili Zhang, Shengyu Liu, Fangyue Liu, Yuanhang Sun, Gang Huang, Xuanzhe Liu, Xin Jin
Large language models (LLMs) power a new generation of interactive AI applications exemplified by ChatGPT. The interactive nature of these applications demands low latency for LLM inference. Existing LLM serving systems use run-to-completion processing for inference jobs, which suffers from head-of-line blocking and long latency. We present FastServe, a distributed inference serving system for LLMs. FastServe exploits the autoregressive pattern of LLM inference to enable preemption at the granularity of each output token. FastServe uses preemptive scheduling to minimize latency with a novel skip-join Multi-Level Feedback Queue scheduler. Based on the new semi-information-agnostic setting of LLM inference, the scheduler leverages the input length information to assign an appropriate initial queue for each arrival job to join. The higher priority queues than the joined queue are skipped to reduce demotions. We design an efficient GPU memory management mechanism that proactively offloads and uploads intermediate state between GPU memory and host memory for LLM inference. We build a system prototype of FastServe and experimental results show that compared to the state-of-the-art solution vLLM, FastServe improves the throughput by up to 31.4x and 17.9x under the same average and tail latency requirements, respectively.
Read more9/26/2024
🤯
72
Efficient LLM inference solution on Intel GPU
Hui Wu, Yi Gan, Feng Yuan, Jing Ma, Wei Zhu, Yutao Xu, Hong Zhu, Yuhua Zhu, Xiaoli Liu, Jinghui Gu, Peng Zhao
Transformer based Large Language Models (LLMs) have been widely used in many fields, and the efficiency of LLM inference becomes hot topic in real applications. However, LLMs are usually complicatedly designed in model structure with massive operations and perform inference in the auto-regressive mode, making it a challenging task to design a system with high efficiency. In this paper, we propose an efficient LLM inference solution with low latency and high throughput. Firstly, we simplify the LLM decoder layer by fusing data movement and element-wise operations to reduce the memory access frequency and lower system latency. We also propose a segment KV cache policy to keep key/value of the request and response tokens in separate physical memory for effective device memory management, helping enlarge the runtime batch size and improve system throughput. A customized Scaled-Dot-Product-Attention kernel is designed to match our fusion policy based on the segment KV cache solution. We implement our LLM inference solution on Intel GPU and publish it publicly. Compared with the standard HuggingFace implementation, the proposed solution achieves up to 7x lower token latency and 27x higher throughput for some popular LLMs on Intel GPU.
Read more6/26/2024