Let the Expert Stick to His Last: Expert-Specialized Fine-Tuning for Sparse Architectural Large Language Models

0
Sign in to get full access
Overview
- This research paper explores a novel approach to fine-tuning large language models for specific tasks.
- The proposed method, called Expert-Specialized Fine-Tuning (ESFT), aims to improve the performance and efficiency of sparse architectural large language models.
- The key idea is to fine-tune only a small subset of the model parameters, allowing the model to specialize in the target task while preserving its general capabilities.
Plain English Explanation
The paper presents a technique called Expert-Specialized Fine-Tuning (ESFT) that can help make large language models more efficient and effective for specific tasks. Large language models are powerful, but they can be slow and resource-intensive to fine-tune for particular applications.
The ESFT approach focuses on fine-tuning only a small subset of the model's parameters, rather than the entire model. This allows the model to specialize in the target task while still maintaining its general knowledge and capabilities. The researchers hypothesize that this selective fine-tuning can lead to better performance and faster training times compared to fine-tuning the entire model.
The key idea is to identify a small number of "expert" parameters within the model that are particularly important for the target task, and then fine-tune only those parameters while keeping the rest of the model fixed. This "let the expert stick to their last" approach aims to leverage the model's existing strengths while efficiently adapting it to the specific problem at hand.
Technical Explanation
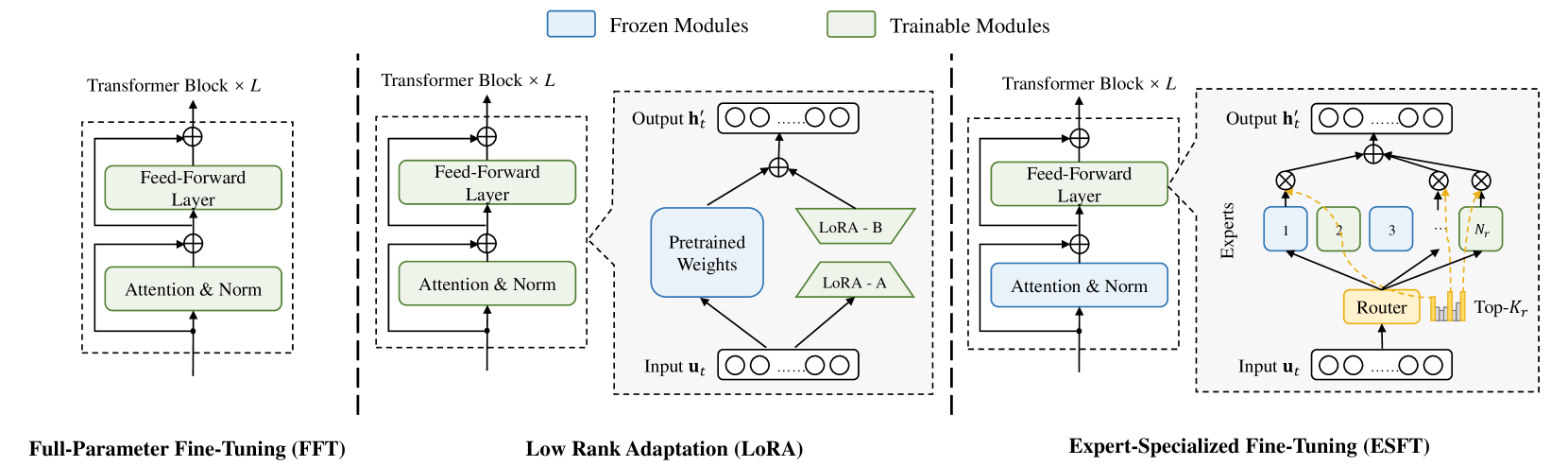
The paper introduces the Expert-Specialized Fine-Tuning (ESFT) method, which selectively fine-tunes a subset of the parameters in a large language model. The researchers hypothesize that this approach can improve the performance and efficiency of sparse architectural large language models.
The ESFT method works as follows:
- Parameter Grouping: The model parameters are divided into two groups: "expert" parameters that are crucial for the target task, and "generalist" parameters that capture the model's general knowledge.
- Task-Specific Fine-Tuning: Only the "expert" parameters are fine-tuned on the target task data, while the "generalist" parameters remain fixed.
- Inference and Deployment: The fine-tuned model can then be used for the target task, with the "expert" parameters handling the task-specific aspects and the "generalist" parameters providing the model's general capabilities.
The key insight is that by fine-tuning only a small subset of the model's parameters, ESFT can achieve comparable or even better performance compared to fine-tuning the entire model, while being more efficient in terms of training time and computational resources.
The paper evaluates the ESFT approach on several natural language processing tasks, including text classification, question answering, and dialogue generation. The results demonstrate the effectiveness of ESFT in improving the performance and efficiency of sparse architectural large language models.
Critical Analysis
The paper presents a well-designed and thorough study of the Expert-Specialized Fine-Tuning (ESFT) approach. The researchers have carefully considered the potential limitations and caveats of their method.
One potential limitation is the reliance on the accuracy of the "expert" parameter identification process. The paper suggests using various techniques, such as gradient-based saliency maps, to determine the critical parameters, but the performance of ESFT may be sensitive to the quality of this parameter selection.
Additionally, the paper focuses on sparse architectural large language models, which may limit the generalizability of the ESFT approach to other model architectures or tasks that require more extensive fine-tuning. Further research is needed to understand how ESFT would perform in a wider range of scenarios.
The paper also acknowledges that the ESFT method may not always outperform fine-tuning the entire model, and the choice between the two approaches may depend on the specific task and available computational resources.
Overall, the ESFT method presents a promising direction for improving the efficiency and performance of large language models, but further exploration and validation across a broader range of applications would be beneficial.
Conclusion
The "Let the Expert Stick to His Last" paper introduces a novel approach called Expert-Specialized Fine-Tuning (ESFT) that aims to make large language models more efficient and effective for specific tasks. The key idea is to selectively fine-tune only a small subset of the model's parameters, allowing the model to specialize in the target task while preserving its general capabilities.
The results demonstrate the potential of the ESFT approach to improve the performance and efficiency of sparse architectural large language models. This research opens up new avenues for developing more adaptable and resource-efficient language models, which could have significant implications for a wide range of natural language processing applications.
As large language models continue to grow in size and complexity, techniques like ESFT will become increasingly important for enabling their effective deployment and fine-tuning for specific use cases. This paper contributes a valuable step forward in this direction, and further research in this area could lead to even more advanced and versatile language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Let the Expert Stick to His Last: Expert-Specialized Fine-Tuning for Sparse Architectural Large Language Models
Zihan Wang, Deli Chen, Damai Dai, Runxin Xu, Zhuoshu Li, Y. Wu
Parameter-efficient fine-tuning (PEFT) is crucial for customizing Large Language Models (LLMs) with constrained resources. Although there have been various PEFT methods for dense-architecture LLMs, PEFT for sparse-architecture LLMs is still underexplored. In this work, we study the PEFT method for LLMs with the Mixture-of-Experts (MoE) architecture and the contents of this work are mainly threefold: (1) We investigate the dispersion degree of the activated experts in customized tasks, and found that the routing distribution for a specific task tends to be highly concentrated, while the distribution of activated experts varies significantly across different tasks. (2) We propose Expert-Specialized Fine-Tuning, or ESFT, which tunes the experts most relevant to downstream tasks while freezing the other experts and modules; experimental results demonstrate that our method not only improves the tuning efficiency, but also matches or even surpasses the performance of full-parameter fine-tuning. (3) We further analyze the impact of the MoE architecture on expert-specialized fine-tuning. We find that MoE models with finer-grained experts are more advantageous in selecting the combination of experts that are most relevant to downstream tasks, thereby enhancing both the training efficiency and effectiveness. Our code is available at https://github.com/deepseek-ai/ESFT.
Read more7/8/2024
0
MEFT: Memory-Efficient Fine-Tuning through Sparse Adapter
Jitai Hao, WeiWei Sun, Xin Xin, Qi Meng, Zhumin Chen, Pengjie Ren, Zhaochun Ren
Parameter-Efficient Fine-tuning (PEFT) facilitates the fine-tuning of Large Language Models (LLMs) under limited resources. However, the fine-tuning performance with PEFT on complex, knowledge-intensive tasks is limited due to the constrained model capacity, which originates from the limited number of additional trainable parameters. To overcome this limitation, we introduce a novel mechanism that fine-tunes LLMs with adapters of larger size yet memory-efficient. This is achieved by leveraging the inherent activation sparsity in the Feed-Forward Networks (FFNs) of LLMs and utilizing the larger capacity of Central Processing Unit (CPU) memory compared to Graphics Processing Unit (GPU). We store and update the parameters of larger adapters on the CPU. Moreover, we employ a Mixture of Experts (MoE)-like architecture to mitigate unnecessary CPU computations and reduce the communication volume between the GPU and CPU. This is particularly beneficial over the limited bandwidth of PCI Express (PCIe). Our method can achieve fine-tuning results comparable to those obtained with larger memory capacities, even when operating under more limited resources such as a 24GB memory single GPU setup, with acceptable loss in training efficiency. Our codes are available at https://github.com/CURRENTF/MEFT.
Read more6/10/2024

0
Sparse is Enough in Fine-tuning Pre-trained Large Language Models
Weixi Song, Zuchao Li, Lefei Zhang, Hai Zhao, Bo Du
With the prevalence of pre-training-fine-tuning paradigm, how to efficiently adapt the pre-trained model to the downstream tasks has been an intriguing issue. Parameter-Efficient Fine-Tuning (PEFT) methods have been proposed for low-cost adaptation. Although PEFT has demonstrated effectiveness and been widely applied, the underlying principles are still unclear. In this paper, we adopt the PAC-Bayesian generalization error bound, viewing pre-training as a shift of prior distribution which leads to a tighter bound for generalization error. We validate this shift from the perspectives of oscillations in the loss landscape and the quasi-sparsity in gradient distribution. Based on this, we propose a gradient-based sparse fine-tuning algorithm, named Sparse Increment Fine-Tuning (SIFT), and validate its effectiveness on a range of tasks including the GLUE Benchmark and Instruction-tuning. The code is accessible at https://github.com/song-wx/SIFT/.
Read more6/11/2024

0
An Empirical Study on Parameter-Efficient Fine-Tuning for MultiModal Large Language Models
Xiongtao Zhou, Jie He, Yuhua Ke, Guangyao Zhu, V'ictor Guti'errez-Basulto, Jeff Z. Pan
Multimodal large language models (MLLMs) fine-tuned with multimodal instruction datasets have demonstrated remarkable capabilities in multimodal tasks. However, fine-tuning all parameters of MLLMs has become challenging as they usually contain billions of parameters. To address this issue, we study parameter-efficient fine-tuning (PEFT) methods for MLLMs. We aim to identify effective methods for enhancing the performance of MLLMs in scenarios where only a limited number of parameters are trained. This paper conducts empirical studies using four popular PEFT methods to fine-tune the LLM component of open-source MLLMs. We present a comprehensive analysis that encompasses various aspects, including the impact of PEFT methods on various models, parameters and location of the PEFT module, size of fine-tuning data, model stability based on PEFT methods, MLLM's generalization, and hallucination. We evaluated four PEFT methods on seven datasets from two different categories: unseen and seen datasets. Across all experiments, we show that the adapter is the best-performing PEFT method. At the same time, fine-tuning the connector layers leads to improved performance in most MLLMs. Code and data are available at https://github.com/alenai97/PEFT-MLLM.git.
Read more6/10/2024