Lisbon Computational Linguists at SemEval-2024 Task 2: Using A Mistral 7B Model and Data Augmentation

0
📈
Sign in to get full access
Overview
- This paper describes the approach taken by a team of computational linguists from Lisbon to participate in SemEval-2024 Task 2, which focuses on safe biomedical natural language processing.
- The team used a large language model called Mistral-7B and applied data augmentation techniques to improve the model's performance on the task.
- The paper provides details on the experiment design, the model architecture, and the key insights gained from the research.
Plain English Explanation
The researchers from Lisbon used a powerful language model called Mistral-7B to tackle a challenging task in natural language processing. The task was to develop systems that can safely and accurately process biomedical text, which is important for applications like medical diagnosis and drug discovery.
To improve the model's performance, the team applied data augmentation techniques. This involves creating new training data by making small, controlled changes to the existing data, such as paraphrasing sentences or replacing words with synonyms. This can help the model learn more robust and generalizable patterns from the data.
The researchers evaluated their approach on the benchmark dataset provided for the SemEval-2024 Task 2 competition. They found that their system, which used the Mistral-7B model and data augmentation, performed well compared to other competing systems.
Technical Explanation
The Lisbon team's approach involved fine-tuning the Mistral-7B model on the task-specific dataset provided for SemEval-2024 Task 2. Mistral-7B is a large language model that has been pre-trained on a vast amount of text data, allowing it to capture general patterns in natural language.
To further improve the model's performance, the researchers applied various data augmentation techniques. This included techniques like back-translation, where sentences are translated to another language and then back to the original language, and synonym replacement, where words in the text are replaced with synonyms.
The team evaluated their system on the SemEval-2024 Task 2 dataset, which contains biomedical text from sources like scientific papers and clinical notes. They measured the model's performance on various metrics, such as F1 score and accuracy.
Critical Analysis
The researchers acknowledged that their approach has some limitations. For example, the Mistral-7B model, while powerful, may still struggle with certain types of biomedical terminology or domain-specific language that is not well-represented in the pre-training data.
Additionally, the data augmentation techniques used, while helpful, may introduce some noise or unintended changes to the text that could impact the model's performance. The researchers suggested that further research is needed to explore more sophisticated data augmentation methods that can better preserve the semantic and syntactic properties of the original text.
It would also be interesting to see how the Lisbon team's approach compares to other state-of-the-art methods, such as ensemble models or hybrid architectures, which may offer additional performance improvements.
Conclusion
The Lisbon team's work demonstrates the power of large language models, like Mistral-7B, and the benefits of data augmentation techniques for improving performance on specialized natural language processing tasks, such as the safe processing of biomedical text.
Their approach provides a solid foundation for further research and development in this important area of natural language processing, with potential applications in fields like healthcare, drug discovery, and scientific research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
0
Lisbon Computational Linguists at SemEval-2024 Task 2: Using A Mistral 7B Model and Data Augmentation
Artur Guimar~aes, Bruno Martins, Jo~ao Magalh~aes
This paper describes our approach to the SemEval-2024 safe biomedical Natural Language Inference for Clinical Trials (NLI4CT) task, which concerns classifying statements about Clinical Trial Reports (CTRs). We explored the capabilities of Mistral-7B, a generalist open-source Large Language Model (LLM). We developed a prompt for the NLI4CT task, and fine-tuned a quantized version of the model using an augmented version of the training dataset. The experimental results show that this approach can produce notable results in terms of the macro F1-score, while having limitations in terms of faithfulness and consistency. All the developed code is publicly available on a GitHub repository
Read more8/7/2024

0
SemEval-2024 Task 2: Safe Biomedical Natural Language Inference for Clinical Trials
Mael Jullien, Marco Valentino, Andr'e Freitas
Large Language Models (LLMs) are at the forefront of NLP achievements but fall short in dealing with shortcut learning, factual inconsistency, and vulnerability to adversarial inputs.These shortcomings are especially critical in medical contexts, where they can misrepresent actual model capabilities. Addressing this, we present SemEval-2024 Task 2: Safe Biomedical Natural Language Inference for ClinicalTrials. Our contributions include the refined NLI4CT-P dataset (i.e., Natural Language Inference for Clinical Trials - Perturbed), designed to challenge LLMs with interventional and causal reasoning tasks, along with a comprehensive evaluation of methods and results for participant submissions. A total of 106 participants registered for the task contributing to over 1200 individual submissions and 25 system overview papers. This initiative aims to advance the robustness and applicability of NLI models in healthcare, ensuring safer and more dependable AI assistance in clinical decision-making. We anticipate that the dataset, models, and outcomes of this task can support future research in the field of biomedical NLI. The dataset, competition leaderboard, and website are publicly available.
Read more4/9/2024
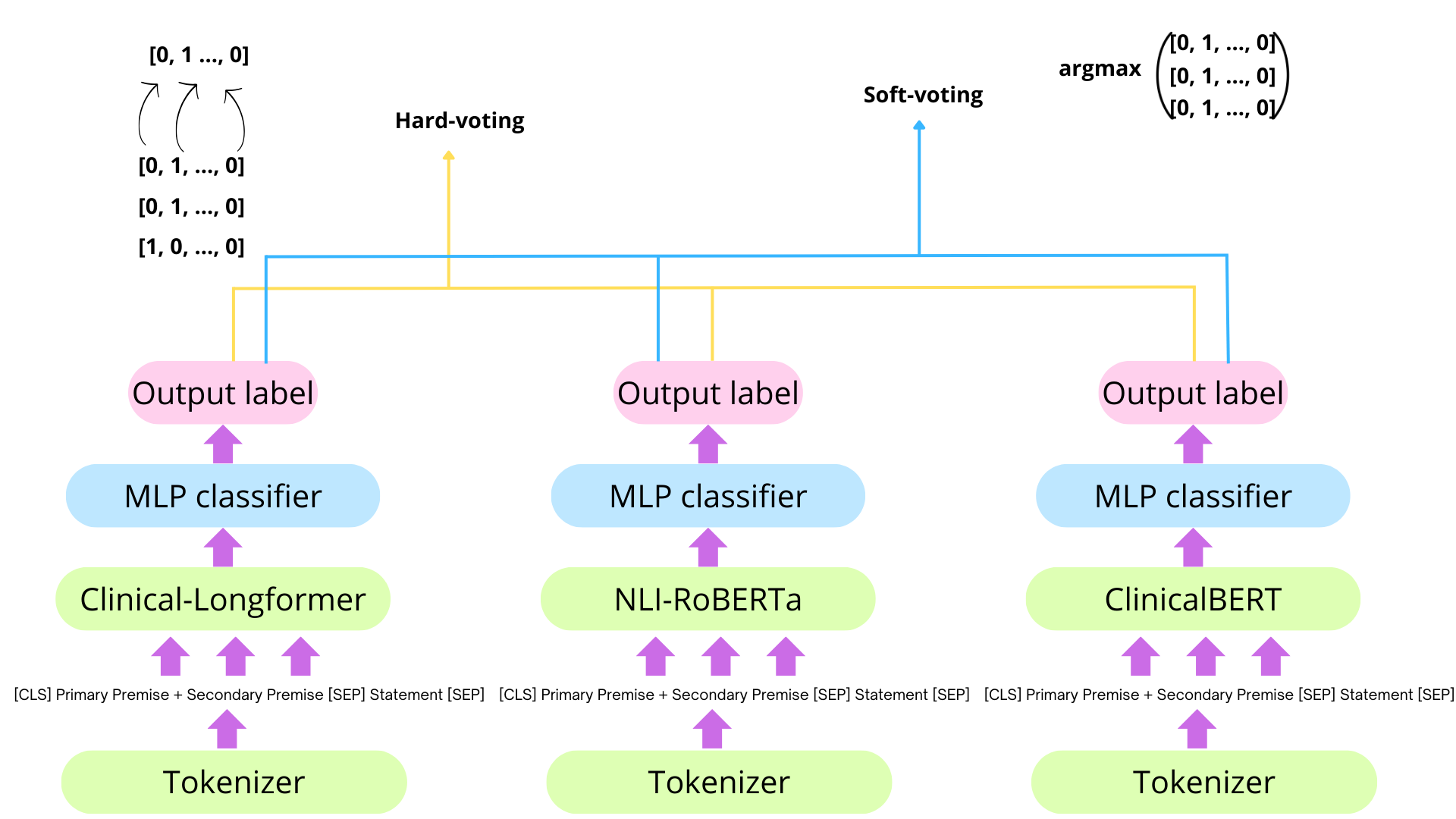
0
SEME at SemEval-2024 Task 2: Comparing Masked and Generative Language Models on Natural Language Inference for Clinical Trials
Mathilde Aguiar, Pierre Zweigenbaum, Nona Naderi
This paper describes our submission to Task 2 of SemEval-2024: Safe Biomedical Natural Language Inference for Clinical Trials. The Multi-evidence Natural Language Inference for Clinical Trial Data (NLI4CT) consists of a Textual Entailment (TE) task focused on the evaluation of the consistency and faithfulness of Natural Language Inference (NLI) models applied to Clinical Trial Reports (CTR). We test 2 distinct approaches, one based on finetuning and ensembling Masked Language Models and the other based on prompting Large Language Models using templates, in particular, using Chain-Of-Thought and Contrastive Chain-Of-Thought. Prompting Flan-T5-large in a 2-shot setting leads to our best system that achieves 0.57 F1 score, 0.64 Faithfulness, and 0.56 Consistency.
Read more4/8/2024

0
BioMistral: A Collection of Open-Source Pretrained Large Language Models for Medical Domains
Yanis Labrak, Adrien Bazoge, Emmanuel Morin, Pierre-Antoine Gourraud, Mickael Rouvier, Richard Dufour
Large Language Models (LLMs) have demonstrated remarkable versatility in recent years, offering potential applications across specialized domains such as healthcare and medicine. Despite the availability of various open-source LLMs tailored for health contexts, adapting general-purpose LLMs to the medical domain presents significant challenges. In this paper, we introduce BioMistral, an open-source LLM tailored for the biomedical domain, utilizing Mistral as its foundation model and further pre-trained on PubMed Central. We conduct a comprehensive evaluation of BioMistral on a benchmark comprising 10 established medical question-answering (QA) tasks in English. We also explore lightweight models obtained through quantization and model merging approaches. Our results demonstrate BioMistral's superior performance compared to existing open-source medical models and its competitive edge against proprietary counterparts. Finally, to address the limited availability of data beyond English and to assess the multilingual generalization of medical LLMs, we automatically translated and evaluated this benchmark into 7 other languages. This marks the first large-scale multilingual evaluation of LLMs in the medical domain. Datasets, multilingual evaluation benchmarks, scripts, and all the models obtained during our experiments are freely released.
Read more7/18/2024