MEFT: Memory-Efficient Fine-Tuning through Sparse Adapter

0
Sign in to get full access
Overview
- This paper introduces MEFT, a memory-efficient fine-tuning technique that uses sparse adapters to reduce the memory footprint during fine-tuning of large language models.
- The key idea is to add a small number of trainable parameters to the model in the form of sparse adapter modules, instead of fine-tuning the entire model.
- The authors show that MEFT can achieve comparable performance to full fine-tuning while using significantly less memory.
Plain English Explanation
Large language models like GPT-3 have billions of parameters and require a lot of memory to fine-tune on specific tasks. MEFT: Memory-Efficient Fine-Tuning through Sparse Adapter proposes a way to reduce the memory needed for fine-tuning by only updating a small number of parameters in the model.
The key idea is to add a few extra "adapter" layers to the model that can be trained separately from the main model. These adapter layers only have a fraction of the parameters of the full model, so they require much less memory to fine-tune. The authors show that by only training these adapter layers, you can get similar performance to fine-tuning the entire model, but with a big reduction in memory usage.
This is an important advance because it allows you to fine-tune large language models on resource-constrained devices like mobile phones or edge devices. It also makes it more practical to fine-tune these models multiple times on different tasks, since the memory requirements are lower. Overall, MEFT is a memory-efficient way to adapt powerful language models to specific applications.
Technical Explanation
The paper introduces a technique called Memory-Efficient Fine-Tuning (MEFT), which uses sparse adapter modules to fine-tune large language models more efficiently.
The core idea is to add a small number of trainable parameters to the model in the form of adapter modules, instead of fine-tuning the entire model. These adapter modules consist of a down-projection layer, a non-linear activation, and an up-projection layer. During fine-tuning, only the adapter module parameters are updated, while the rest of the model remains frozen.
The authors show that this approach, which they call "sparse fine-tuning", can achieve comparable performance to full fine-tuning on a variety of tasks, but with a much lower memory footprint. For example, they demonstrate that MEFT can reduce the memory usage by up to 90% compared to standard fine-tuning, while maintaining similar task performance.
The paper also explores different adapter architectures and positioning within the model, as well as the impact of adapter size and sparsity on performance. The authors find that strategically placing the adapters and using a small number of parameters (e.g. 1-2% of the model size) can strike a good balance between memory efficiency and task performance.
Critical Analysis
The MEFT approach presented in this paper is a promising technique for efficient fine-tuning of large language models. By focusing updates on a small number of parameters, it effectively addresses the memory constraints that often limit the practical application of these powerful models.
One potential limitation of the approach is that it may not work as well for tasks that require more significant changes to the model's internal representations, as the adapter modules have a relatively small capacity. The authors acknowledge this and suggest that MEFT may work best for tasks that can be solved with relatively minor adjustments to the model.
Additionally, the paper does not provide a detailed analysis of the computational overhead introduced by the adapter modules during inference. While the memory usage is reduced, there may be some additional computational cost that should be considered, especially for latency-sensitive applications.
Further research could explore ways to make the adapter modules even more efficient, such as by using more advanced architectural designs or compression techniques. Unlocking Parameter-Efficient Fine-Tuning for Low-Resource Tasks and A Comprehensive Analysis of Parameter-Efficient Fine-Tuning Across Tasks may provide additional insights in this direction.
Overall, the MEFT approach represents an important step forward in making large language models more accessible and practical for a wider range of applications. The focus on memory efficiency is a crucial consideration, and the techniques presented in this paper could have a significant impact on the field.
Conclusion
MEFT: Memory-Efficient Fine-Tuning through Sparse Adapter introduces a novel technique for fine-tuning large language models that significantly reduces the memory requirements compared to standard fine-tuning. By adding small, trainable adapter modules to the model, the authors show that it's possible to achieve comparable task performance while using up to 90% less memory.
This advance has important implications for the practical deployment of powerful language models, as it enables fine-tuning on resource-constrained devices and makes it more feasible to adapt these models to multiple tasks. The techniques presented in this paper could help unlock the full potential of large language models in a wide range of real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MEFT: Memory-Efficient Fine-Tuning through Sparse Adapter
Jitai Hao, WeiWei Sun, Xin Xin, Qi Meng, Zhumin Chen, Pengjie Ren, Zhaochun Ren
Parameter-Efficient Fine-tuning (PEFT) facilitates the fine-tuning of Large Language Models (LLMs) under limited resources. However, the fine-tuning performance with PEFT on complex, knowledge-intensive tasks is limited due to the constrained model capacity, which originates from the limited number of additional trainable parameters. To overcome this limitation, we introduce a novel mechanism that fine-tunes LLMs with adapters of larger size yet memory-efficient. This is achieved by leveraging the inherent activation sparsity in the Feed-Forward Networks (FFNs) of LLMs and utilizing the larger capacity of Central Processing Unit (CPU) memory compared to Graphics Processing Unit (GPU). We store and update the parameters of larger adapters on the CPU. Moreover, we employ a Mixture of Experts (MoE)-like architecture to mitigate unnecessary CPU computations and reduce the communication volume between the GPU and CPU. This is particularly beneficial over the limited bandwidth of PCI Express (PCIe). Our method can achieve fine-tuning results comparable to those obtained with larger memory capacities, even when operating under more limited resources such as a 24GB memory single GPU setup, with acceptable loss in training efficiency. Our codes are available at https://github.com/CURRENTF/MEFT.
Read more6/10/2024
0
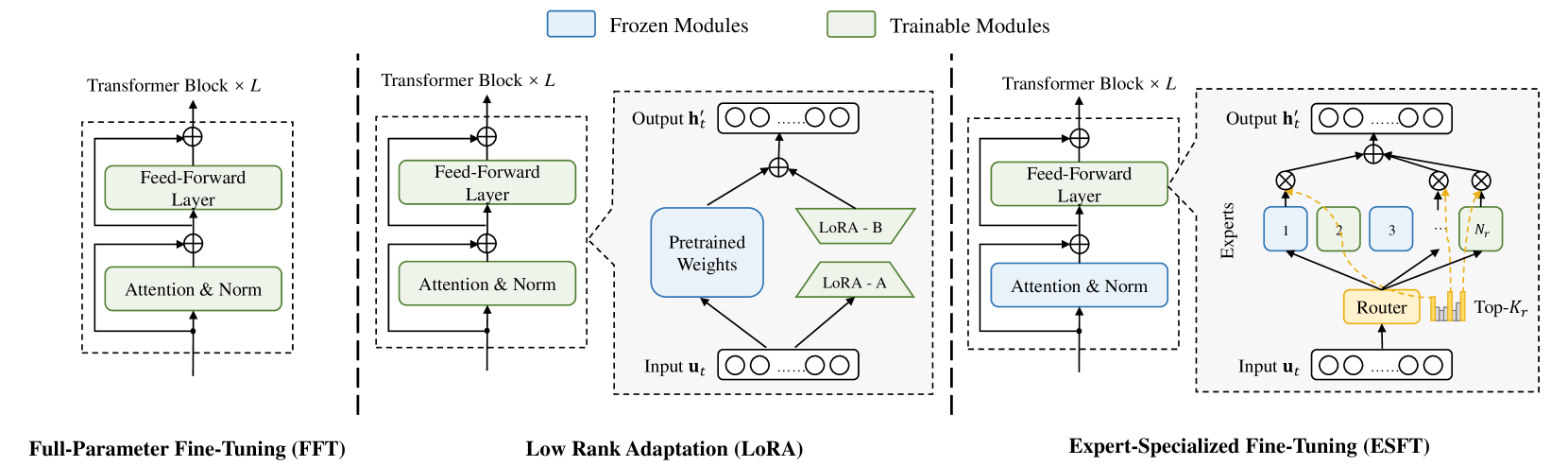
Let the Expert Stick to His Last: Expert-Specialized Fine-Tuning for Sparse Architectural Large Language Models
Zihan Wang, Deli Chen, Damai Dai, Runxin Xu, Zhuoshu Li, Y. Wu
Parameter-efficient fine-tuning (PEFT) is crucial for customizing Large Language Models (LLMs) with constrained resources. Although there have been various PEFT methods for dense-architecture LLMs, PEFT for sparse-architecture LLMs is still underexplored. In this work, we study the PEFT method for LLMs with the Mixture-of-Experts (MoE) architecture and the contents of this work are mainly threefold: (1) We investigate the dispersion degree of the activated experts in customized tasks, and found that the routing distribution for a specific task tends to be highly concentrated, while the distribution of activated experts varies significantly across different tasks. (2) We propose Expert-Specialized Fine-Tuning, or ESFT, which tunes the experts most relevant to downstream tasks while freezing the other experts and modules; experimental results demonstrate that our method not only improves the tuning efficiency, but also matches or even surpasses the performance of full-parameter fine-tuning. (3) We further analyze the impact of the MoE architecture on expert-specialized fine-tuning. We find that MoE models with finer-grained experts are more advantageous in selecting the combination of experts that are most relevant to downstream tasks, thereby enhancing both the training efficiency and effectiveness. Our code is available at https://github.com/deepseek-ai/ESFT.
Read more7/8/2024

0
An Empirical Study on Parameter-Efficient Fine-Tuning for MultiModal Large Language Models
Xiongtao Zhou, Jie He, Yuhua Ke, Guangyao Zhu, V'ictor Guti'errez-Basulto, Jeff Z. Pan
Multimodal large language models (MLLMs) fine-tuned with multimodal instruction datasets have demonstrated remarkable capabilities in multimodal tasks. However, fine-tuning all parameters of MLLMs has become challenging as they usually contain billions of parameters. To address this issue, we study parameter-efficient fine-tuning (PEFT) methods for MLLMs. We aim to identify effective methods for enhancing the performance of MLLMs in scenarios where only a limited number of parameters are trained. This paper conducts empirical studies using four popular PEFT methods to fine-tune the LLM component of open-source MLLMs. We present a comprehensive analysis that encompasses various aspects, including the impact of PEFT methods on various models, parameters and location of the PEFT module, size of fine-tuning data, model stability based on PEFT methods, MLLM's generalization, and hallucination. We evaluated four PEFT methods on seven datasets from two different categories: unseen and seen datasets. Across all experiments, we show that the adapter is the best-performing PEFT method. At the same time, fine-tuning the connector layers leads to improved performance in most MLLMs. Code and data are available at https://github.com/alenai97/PEFT-MLLM.git.
Read more6/10/2024

0
Parameter-Efficient Fine-Tuning for Large Models: A Comprehensive Survey
Zeyu Han, Chao Gao, Jinyang Liu, Jeff Zhang, Sai Qian Zhang
Large models represent a groundbreaking advancement in multiple application fields, enabling remarkable achievements across various tasks. However, their unprecedented scale comes with significant computational costs. These models, often consisting of billions of parameters, require vast amounts of computational resources for execution. Especially, the expansive scale and computational demands pose considerable challenges when customizing them for particular downstream tasks, particularly over the hardware platforms constrained by computational capabilities. Parameter Efficient Fine-Tuning (PEFT) provides a practical solution by efficiently adapt the large models over the various downstream tasks. In particular, PEFT refers to the process of adjusting the parameters of a pre-trained large models to adapt it to a specific task while minimizing the number of additional parameters introduced or computational resources required. This approach is particularly important when dealing with large language models with high parameter counts, as fine-tuning these models from scratch can be computationally expensive and resource-intensive, posing considerable challenges in the supporting system platform design. In this survey, we present comprehensive studies of various PEFT algorithms, examining their performance and computational overhead. Moreover, we provide an overview of applications developed using different PEFT algorithms and discuss common techniques employed to mitigate computation costs for PEFT. In addition to the algorithmic perspective, we overview various real-world system designs to investigate the implementation costs associated with different PEFT algorithms. This survey serves as an indispensable resource for researchers aiming to understand both the PEFT algorithm and its system implementation, offering detailed insights into recent advancements and practical applications.
Read more4/30/2024