OPTune: Efficient Online Preference Tuning

0
Sign in to get full access
Overview
• The paper presents OPTune, a method for efficiently tuning preferences in online settings. • OPTune leverages a reward model to capture user preferences and updates it based on user feedback. • The approach aims to maximize user satisfaction while minimizing the cost of soliciting feedback. • OPTune is evaluated on several benchmark preference learning tasks, demonstrating improved performance over existing methods.
Plain English Explanation
OPTune is a system designed to help computers learn and adapt to user preferences in an efficient way. The key idea is to use a reward model - a machine learning model that tries to capture what the user likes or dislikes. This reward model is then updated based on feedback from the user, allowing the system to continually improve its understanding of the user's preferences.
The main benefit of OPTune is that it can learn these preferences quickly and with minimal effort from the user. Instead of constantly asking the user for feedback, OPTune makes educated guesses about their preferences and only asks for feedback when it's really necessary. This makes the process much more seamless and pleasant for the user.
The paper shows that OPTune outperforms existing methods on several benchmark tasks, meaning it is able to learn user preferences more accurately and efficiently. This could be useful in a wide range of applications, from personalizing AI assistants to optimizing recommendation systems.
Technical Explanation
OPTune is built around a reward model, which is a machine learning model trained to predict a user's preferences. This reward model takes in information about the user's past choices and feedback, and outputs a predicted "reward" or preference score for new options.
The key innovation of OPTune is how it updates this reward model in an efficient, online manner. Instead of retraining the entire model from scratch every time new feedback is received, OPTune selectively updates only the most relevant parts of the model. This allows it to rapidly adapt to the user's preferences with minimal computational overhead.
OPTune also employs a novel acquisition function to determine when to solicit new feedback from the user. By intelligently deciding which options to ask the user about, it can learn the user's preferences using far fewer feedback samples than previous preference learning methods.
The paper evaluates OPTune on several benchmark preference learning tasks, including preference-based reinforcement learning and preference-based recommendation. The results demonstrate that OPTune outperforms existing state-of-the-art approaches in terms of both learning efficiency and final performance.
Critical Analysis
The paper provides a thorough evaluation of OPTune and highlights several key strengths of the approach. However, it also acknowledges some limitations and areas for further research:
- The experiments are conducted in relatively simple, synthetic environments. More research is needed to understand how well OPTune scales to real-world, complex preference learning scenarios.
- The paper does not explore how OPTune might handle the exploration-exploitation tradeoff, where the system needs to balance learning about new preferences vs. optimizing for known preferences.
- The acquisition function used by OPTune to select feedback queries assumes the user's preferences are static. Extending the approach to handle dynamic, evolving preferences could be an interesting direction for future work.
Overall, the OPTune framework represents a promising step forward in efficient online preference learning. However, as with any new technique, further research and real-world testing will be necessary to fully understand its capabilities and limitations.
Conclusion
The OPTune paper presents an innovative approach for efficiently tuning user preferences in online settings. By leveraging a reward model that is selectively updated based on user feedback, OPTune is able to learn preferences quickly and with minimal burden on the user.
The results demonstrate that OPTune outperforms existing state-of-the-art methods on several benchmark preference learning tasks. This suggests that the approach could have significant impact in a wide range of applications, from personalized AI assistants to optimized recommendation systems.
While the paper highlights some limitations that warrant further research, the core ideas behind OPTune represent an important step forward in the field of preference learning. As AI systems become increasingly prevalent in our daily lives, developing efficient and user-friendly preference tuning methods will only grow in importance.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
OPTune: Efficient Online Preference Tuning
Lichang Chen, Jiuhai Chen, Chenxi Liu, John Kirchenbauer, Davit Soselia, Chen Zhu, Tom Goldstein, Tianyi Zhou, Heng Huang
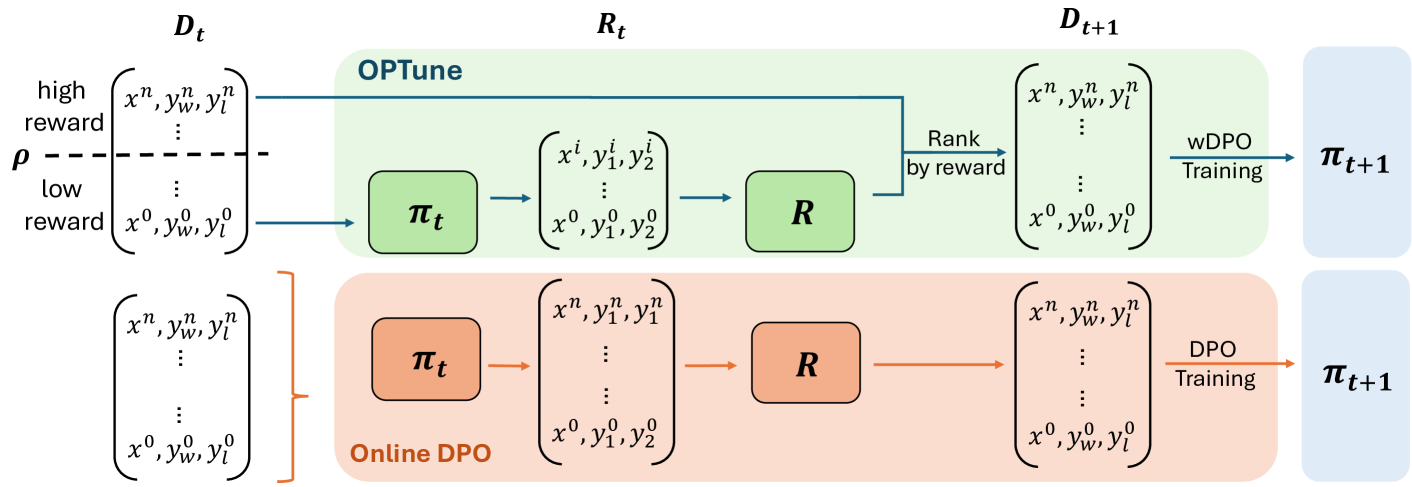
Reinforcement learning with human feedback~(RLHF) is critical for aligning Large Language Models (LLMs) with human preference. Compared to the widely studied offline version of RLHF, emph{e.g.} direct preference optimization (DPO), recent works have shown that the online variants achieve even better alignment. However, online alignment requires on-the-fly generation of new training data, which is costly, hard to parallelize, and suffers from varying quality and utility. In this paper, we propose a more efficient data exploration strategy for online preference tuning (OPTune), which does not rely on human-curated or pre-collected teacher responses but dynamically samples informative responses for on-policy preference alignment. During data generation, OPTune only selects prompts whose (re)generated responses can potentially provide more informative and higher-quality training signals than the existing responses. In the training objective, OPTune reweights each generated response (pair) by its utility in improving the alignment so that learning can be focused on the most helpful samples. Throughout our evaluations, OPTune'd LLMs maintain the instruction-following benefits provided by standard preference tuning whilst enjoying 1.27-1.56x faster training speed due to the efficient data exploration strategy.
Read more6/13/2024

0
New Desiderata for Direct Preference Optimization
Xiangkun Hu, Tong He, David Wipf
Large language models in the past have typically relied on some form of reinforcement learning with human feedback (RLHF) to better align model responses with human preferences. However, because of oft-observed instabilities when implementing these RLHF pipelines, various reparameterization techniques have recently been introduced to sidestep the need for separately learning an RL reward model. Instead, directly fine-tuning for human preferences is achieved via the minimization of a single closed-form training objective, a process originally referred to as direct preference optimization (DPO) and followed by several notable descendants. Although effective in certain real-world settings, we introduce new evaluation criteria that serve to highlight unresolved shortcomings in the ability of existing DPO methods to interpolate between a pre-trained reference model and empirical measures of human preferences, as well as unavoidable trade-offs in how low- and high-quality responses are regularized and constraints are handled. Our insights then motivate an alternative DPO-like loss that provably mitigates these limitations. Empirical results serve to corroborate notable aspects of our analyses.
Read more7/15/2024
💬
4
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, Chelsea Finn
While large-scale unsupervised language models (LMs) learn broad world knowledge and some reasoning skills, achieving precise control of their behavior is difficult due to the completely unsupervised nature of their training. Existing methods for gaining such steerability collect human labels of the relative quality of model generations and fine-tune the unsupervised LM to align with these preferences, often with reinforcement learning from human feedback (RLHF). However, RLHF is a complex and often unstable procedure, first fitting a reward model that reflects the human preferences, and then fine-tuning the large unsupervised LM using reinforcement learning to maximize this estimated reward without drifting too far from the original model. In this paper we introduce a new parameterization of the reward model in RLHF that enables extraction of the corresponding optimal policy in closed form, allowing us to solve the standard RLHF problem with only a simple classification loss. The resulting algorithm, which we call Direct Preference Optimization (DPO), is stable, performant, and computationally lightweight, eliminating the need for sampling from the LM during fine-tuning or performing significant hyperparameter tuning. Our experiments show that DPO can fine-tune LMs to align with human preferences as well as or better than existing methods. Notably, fine-tuning with DPO exceeds PPO-based RLHF in ability to control sentiment of generations, and matches or improves response quality in summarization and single-turn dialogue while being substantially simpler to implement and train.
Read more7/31/2024
🧪
0
Exploratory Preference Optimization: Harnessing Implicit Q*-Approximation for Sample-Efficient RLHF
Tengyang Xie, Dylan J. Foster, Akshay Krishnamurthy, Corby Rosset, Ahmed Awadallah, Alexander Rakhlin
Reinforcement learning from human feedback (RLHF) has emerged as a central tool for language model alignment. We consider online exploration in RLHF, which exploits interactive access to human or AI feedback by deliberately encouraging the model to produce diverse, maximally informative responses. By allowing RLHF to confidently stray from the pre-trained model, online exploration offers the possibility of novel, potentially super-human capabilities, but its full potential as a paradigm for language model training has yet to be realized, owing to computational and statistical bottlenecks in directly adapting existing reinforcement learning techniques. We propose a new algorithm for online exploration in RLHF, Exploratory Preference Optimization (XPO), which is simple and practical -- a one-line change to (online) Direct Preference Optimization (DPO; Rafailov et al., 2023) -- yet enjoys the strongest known provable guarantees and promising empirical performance. XPO augments the DPO objective with a novel and principled exploration bonus, empowering the algorithm to explore outside the support of the initial model and human feedback data. In theory, we show that XPO is provably sample-efficient and converges to a near-optimal language model policy under natural exploration conditions, irrespective of whether the initial model has good coverage. Our analysis, which builds on the observation that DPO implicitly performs a form of $Q^{star}$-approximation (or, Bellman error minimization), combines previously disparate techniques from language modeling and theoretical reinforcement learning in a serendipitous fashion through the perspective of KL-regularized Markov decision processes. Empirically, we find that XPO is more sample-efficient than non-exploratory DPO variants in a preliminary evaluation.
Read more6/3/2024