Parameter-Efficient Sparsity Crafting from Dense to Mixture-of-Experts for Instruction Tuning on General Tasks

1

Sign in to get full access
Overview
- This paper presents a parameter-efficient approach for instruction tuning on general tasks using a sparse mixture-of-experts (MoE) architecture.
- The proposed method, called Sparsity Crafting, gradually transitions a dense model to a sparse MoE model during training, improving performance while maintaining model size.
- Experiments show the Sparsity Crafting approach outperforms dense and other sparse models on a variety of instruction-following benchmarks.
Plain English Explanation
The research paper introduces a new way to train [object Object] (AI) models to follow instructions and complete general tasks. The key idea is to start with a dense (fully-connected) model and gradually transform it into a [object Object] (MoE) model during the training process.
In a sparse MoE model, the work of the model is divided up among multiple "expert" sub-models, each of which specializes in a particular type of task. This allows the overall model to be more efficient and effective, as each expert can focus on what it's best at.
The researchers found that this [object Object] approach outperformed both the original dense model and other sparse models on a variety of [object Object]. This suggests that the gradual transition from dense to sparse MoE can help AI models become more [object Object] and effective at following instructions and completing general tasks.
Technical Explanation
The paper introduces a [object Object] approach that gradually transitions a dense model to a sparse [object Object] model during training. This allows the model to become more parameter-efficient while maintaining or even improving performance on instruction-following tasks.
The training process starts with a dense model and incrementally increases the sparsity, eventually arriving at a sparse MoE model. The MoE model consists of multiple "expert" sub-models, each of which specializes in a particular type of task. During inference, the model selects the most relevant experts to use for a given input, making the overall model more efficient.
Experiments on a variety of [object Object] show that the Sparsity Crafting approach outperforms both the original dense model and other sparse models. This suggests that the gradual transition to a sparse MoE architecture can [object Object] while maintaining or even enhancing the model's ability to follow instructions and complete general tasks.
Critical Analysis
The paper presents a promising approach for improving the [object Object] of instruction-following models, but there are a few potential limitations and areas for further research:
-
The paper focuses on a specific set of instruction-following benchmarks, and it's unclear how well the Sparsity Crafting approach would generalize to other types of general tasks or datasets.
-
The transition from dense to sparse MoE is a complex process, and the paper does not explore the impact of different hyperparameters or architectural choices on the performance and efficiency of the final model.
-
While the [object Object] is said to improve parameter-efficiency, the paper does not provide a detailed analysis of the memory and computational requirements of the dense and sparse models.
-
The paper does not compare the Sparsity Crafting approach to other parameter-efficient techniques, such as [object Object] or [object Object], which could provide additional insights into the strengths and limitations of the proposed method.
Overall, the [object Object] approach is an interesting and potentially valuable contribution to the field of parameter-efficient AI models for instruction-following tasks. Further research and evaluation on a broader range of tasks and datasets would help strengthen the conclusions and provide a clearer understanding of the method's practical implications.
Conclusion
This research paper introduces a novel [object Object] approach that gradually transitions a dense AI model to a sparse [object Object] model during training. The resulting sparse MoE model demonstrates improved [object Object] while maintaining or enhancing performance on a variety of [object Object].
This research suggests that the gradual transition from dense to sparse MoE architectures can be a promising approach for developing [object Object] capable of following instructions and completing general tasks. Further exploration of this technique, including its application to a wider range of tasks and comparison to other parameter-efficient methods, could lead to significant advancements in the field of AI and its ability to assist and empower humans in a wide variety of domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
1
New!Parameter-Efficient Sparsity Crafting from Dense to Mixture-of-Experts for Instruction Tuning on General Tasks
Haoyuan Wu, Haisheng Zheng, Zhuolun He, Bei Yu
Large language models (LLMs) have demonstrated considerable proficiency in general natural language processing (NLP) tasks. Instruction tuning, a successful paradigm, enhances the ability of LLMs to follow natural language instructions and exhibit robust generalization across general tasks. However, these models often encounter performance limitations across multiple tasks due to constrained model capacity. Expanding this capacity during the instruction tuning phase poses significant challenges. To address this issue, we introduce parameter-efficient sparsity crafting (PESC), which crafts dense models into sparse models using the mixture-of-experts (MoE) architecture. PESC integrates adapters into the MoE layers of sparse models, differentiating experts without altering the individual weights within these layers. This method significantly reduces computational costs and GPU memory requirements, facilitating model capacity expansion through a minimal parameter increase when guaranteeing the quality of approximation in function space compared to original sparse upcycling. Our empirical evaluation demonstrates the effectiveness of the PESC method. Using PESC during instruction tuning, our best sparse model outperforms other sparse and dense models and exhibits superior general capabilities compared to GPT-3.5. Our code is available at https://github.com/wuhy68/Parameter-Efficient-MoE.
Read more9/25/2024
0
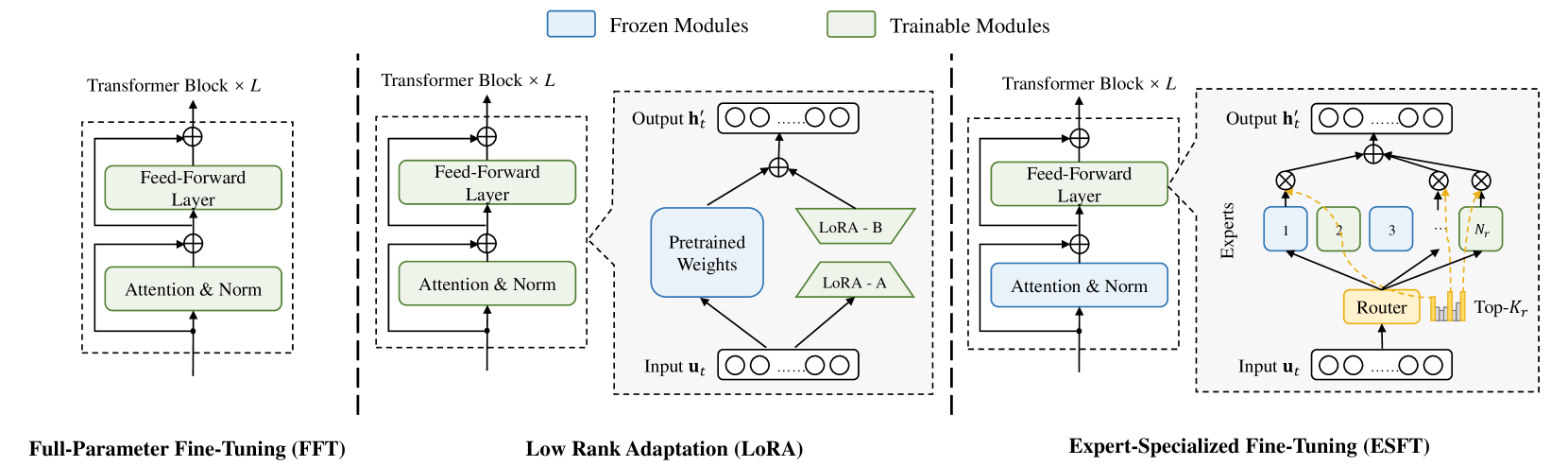
Let the Expert Stick to His Last: Expert-Specialized Fine-Tuning for Sparse Architectural Large Language Models
Zihan Wang, Deli Chen, Damai Dai, Runxin Xu, Zhuoshu Li, Y. Wu
Parameter-efficient fine-tuning (PEFT) is crucial for customizing Large Language Models (LLMs) with constrained resources. Although there have been various PEFT methods for dense-architecture LLMs, PEFT for sparse-architecture LLMs is still underexplored. In this work, we study the PEFT method for LLMs with the Mixture-of-Experts (MoE) architecture and the contents of this work are mainly threefold: (1) We investigate the dispersion degree of the activated experts in customized tasks, and found that the routing distribution for a specific task tends to be highly concentrated, while the distribution of activated experts varies significantly across different tasks. (2) We propose Expert-Specialized Fine-Tuning, or ESFT, which tunes the experts most relevant to downstream tasks while freezing the other experts and modules; experimental results demonstrate that our method not only improves the tuning efficiency, but also matches or even surpasses the performance of full-parameter fine-tuning. (3) We further analyze the impact of the MoE architecture on expert-specialized fine-tuning. We find that MoE models with finer-grained experts are more advantageous in selecting the combination of experts that are most relevant to downstream tasks, thereby enhancing both the training efficiency and effectiveness. Our code is available at https://github.com/deepseek-ai/ESFT.
Read more7/8/2024

0
Efficient Expert Pruning for Sparse Mixture-of-Experts Language Models: Enhancing Performance and Reducing Inference Costs
Enshu Liu, Junyi Zhu, Zinan Lin, Xuefei Ning, Matthew B. Blaschko, Shengen Yan, Guohao Dai, Huazhong Yang, Yu Wang
The rapid advancement of large language models (LLMs) has led to architectures with billions to trillions of parameters, posing significant deployment challenges due to their substantial demands on memory, processing power, and energy consumption. Sparse Mixture-of-Experts (SMoE) architectures have emerged as a solution, activating only a subset of parameters per token, thereby achieving faster inference while maintaining performance. However, SMoE models still face limitations in broader deployment due to their large parameter counts and significant GPU memory requirements. In this work, we introduce a gradient-free evolutionary strategy named EEP (Efficient Expert P}runing) to enhance the pruning of experts in SMoE models. EEP relies solely on model inference (i.e., no gradient computation) and achieves greater sparsity while maintaining or even improving performance on downstream tasks. EEP can be used to reduce both the total number of experts (thus saving GPU memory) and the number of active experts (thus accelerating inference). For example, we demonstrate that pruning up to 75% of experts in Mixtral $8times7$B-Instruct results in a substantial reduction in parameters with minimal performance loss. Remarkably, we observe improved performance on certain tasks, such as a significant increase in accuracy on the SQuAD dataset (from 53.4% to 75.4%), when pruning half of the experts. With these results, EEP not only lowers the barrier to deploying SMoE models,but also challenges the conventional understanding of model pruning by showing that fewer experts can lead to better task-specific performance without any fine-tuning. Code is available at https://github.com/imagination-research/EEP.
Read more7/2/2024
0
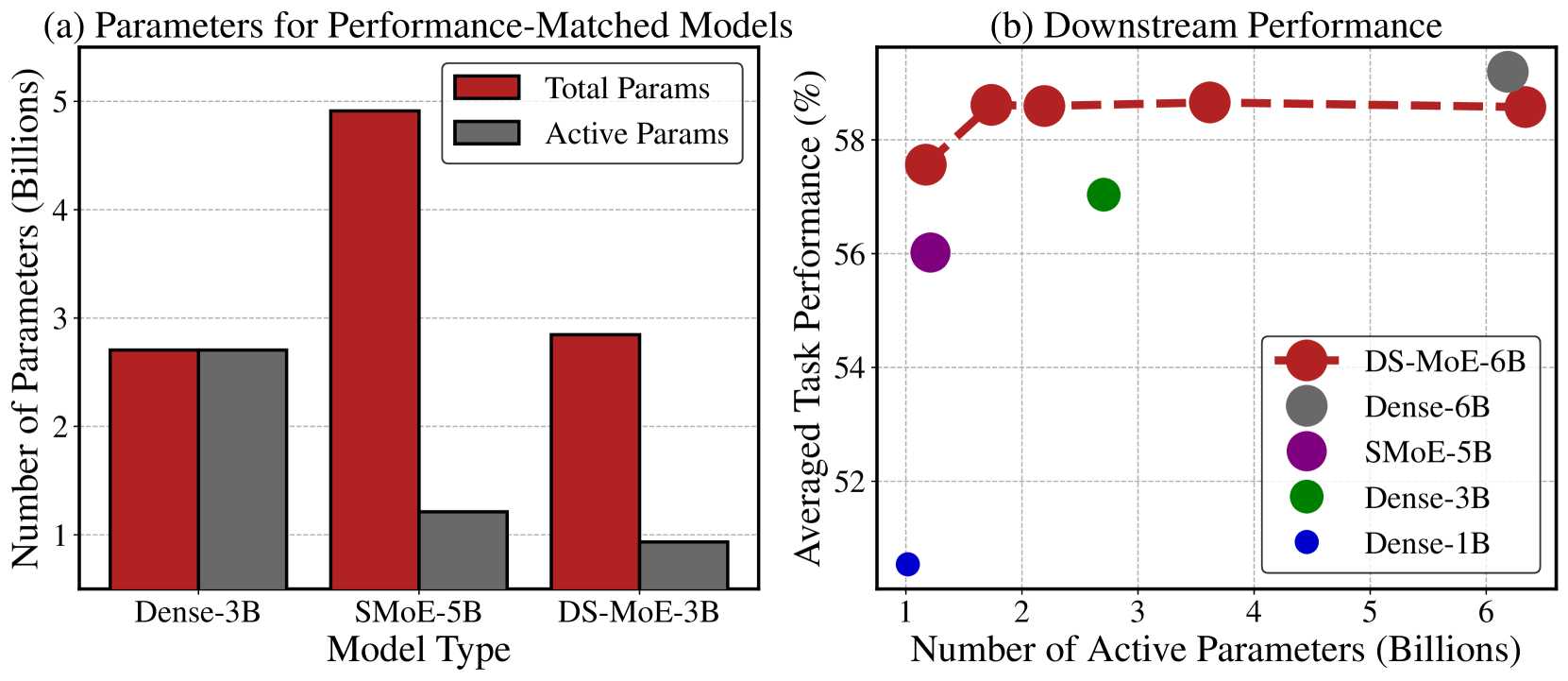
Dense Training, Sparse Inference: Rethinking Training of Mixture-of-Experts Language Models
Bowen Pan, Yikang Shen, Haokun Liu, Mayank Mishra, Gaoyuan Zhang, Aude Oliva, Colin Raffel, Rameswar Panda
Mixture-of-Experts (MoE) language models can reduce computational costs by 2-4$times$ compared to dense models without sacrificing performance, making them more efficient in computation-bounded scenarios. However, MoE models generally require 2-4$times$ times more parameters to achieve comparable performance to a dense model, which incurs larger GPU memory requirements and makes MoE models less efficient in I/O-bounded scenarios like autoregressive generation. In this work, we propose a hybrid dense training and sparse inference framework for MoE models (DS-MoE) which achieves strong computation and parameter efficiency by employing dense computation across all experts during training and sparse computation during inference. Our experiments on training LLMs demonstrate that our DS-MoE models are more parameter-efficient than standard sparse MoEs and are on par with dense models in terms of total parameter size and performance while being computationally cheaper (activating 30-40% of the model's parameters). Performance tests using vLLM show that our DS-MoE-6B model runs up to $1.86times$ faster than similar dense models like Mistral-7B, and between $1.50times$ and $1.71times$ faster than comparable MoEs, such as DeepSeekMoE-16B and Qwen1.5-MoE-A2.7B.
Read more4/9/2024