PLeak: Prompt Leaking Attacks against Large Language Model Applications

0
Sign in to get full access
Overview
- This paper introduces a new attack called "PLeak" that can extract sensitive information from large language models (LLMs) like GPT-3.
- The PLeak attack exploits a vulnerability where prompts used to generate model outputs can inadvertently leak sensitive information, even if the outputs themselves do not.
- The researchers demonstrate how PLeak can extract private details like user names, email addresses, and other sensitive data from real-world LLM applications.
Plain English Explanation:
The paper discusses a new type of attack called "PLeak" that can extract private information from large language models (LLMs) like GPT-3, even if the model's outputs don't directly contain that sensitive data. The key insight is that the prompts used to generate model outputs can sometimes inadvertently leak private details, without the user realizing it. The researchers show how PLeak can extract things like usernames, email addresses, and other sensitive information from real-world applications powered by LLMs. This is an important security and privacy issue that needs to be addressed as these powerful AI models become more widely used.
Technical Explanation
The paper introduces a novel attack called "Prompt Leakage" (PLeak) that can extract sensitive information from large language models (LLMs) like GPT-3, even when the model's outputs do not directly contain that private data. The key vulnerability the PLeak attack exploits is that the prompts used to generate model outputs can inadvertently leak sensitive details, without the user realizing it.
The researchers demonstrate how PLeak works in practice by developing concrete attack scenarios against real-world LLM applications. For example, they show how PLeak can extract a user's name, email address, and other private information from an LLM-powered chatbot, even when the chatbot's responses don't explicitly reveal that data. The paper also discusses various defenses against PLeak, such as prompt filtering and output sanitization, and evaluates their effectiveness.
Overall, this work highlights an important security and privacy risk with the growing use of large language models in real-world applications. The PLeak attack shows how sensitive information can be inadvertently exposed, emphasizing the need for robust safeguards as these powerful AI systems become more widely deployed.
Critical Analysis
The paper provides a thorough and well-designed study of the PLeak attack against large language models. The researchers thoughtfully consider various attack scenarios and defenses, offering a comprehensive examination of this security and privacy concern.
However, the paper does not address some potential limitations or areas for further research. For example, it would be valuable to understand how the effectiveness of PLeak might vary across different LLM architectures, training datasets, or fine-tuning approaches. Additionally, the paper focuses on extraction of relatively straightforward private details like names and emails, but it's unclear how PLeak might perform in extracting more nuanced or contextual sensitive information.
Further, while the proposed defenses are evaluated, the analysis could be expanded to consider the practical trade-offs and usability implications of implementing these safeguards in real-world LLM applications. Understanding the deployment challenges and potential performance impacts would help inform how these protections could be effectively adopted.
Overall, this is an important contribution that highlights a significant vulnerability in large language models. However, additional research is warranted to fully characterize the scope and implications of prompt leakage attacks.
Conclusion
This paper introduces a new attack called "PLeak" that can extract sensitive information from large language models (LLMs) by exploiting vulnerabilities in the prompts used to generate model outputs. The researchers demonstrate concrete attack scenarios where PLeak is able to extract private details like usernames and email addresses, even when the model's responses do not directly contain that sensitive data.
The work underscores a critical security and privacy challenge as LLMs become increasingly prevalent in real-world applications. While the paper proposes several potential defenses, further research is needed to fully understand the scope of the prompt leakage issue and develop robust, practical safeguards. As these powerful AI systems continue to be deployed, ensuring the protection of user privacy will be an essential priority.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
PLeak: Prompt Leaking Attacks against Large Language Model Applications
Bo Hui, Haolin Yuan, Neil Gong, Philippe Burlina, Yinzhi Cao
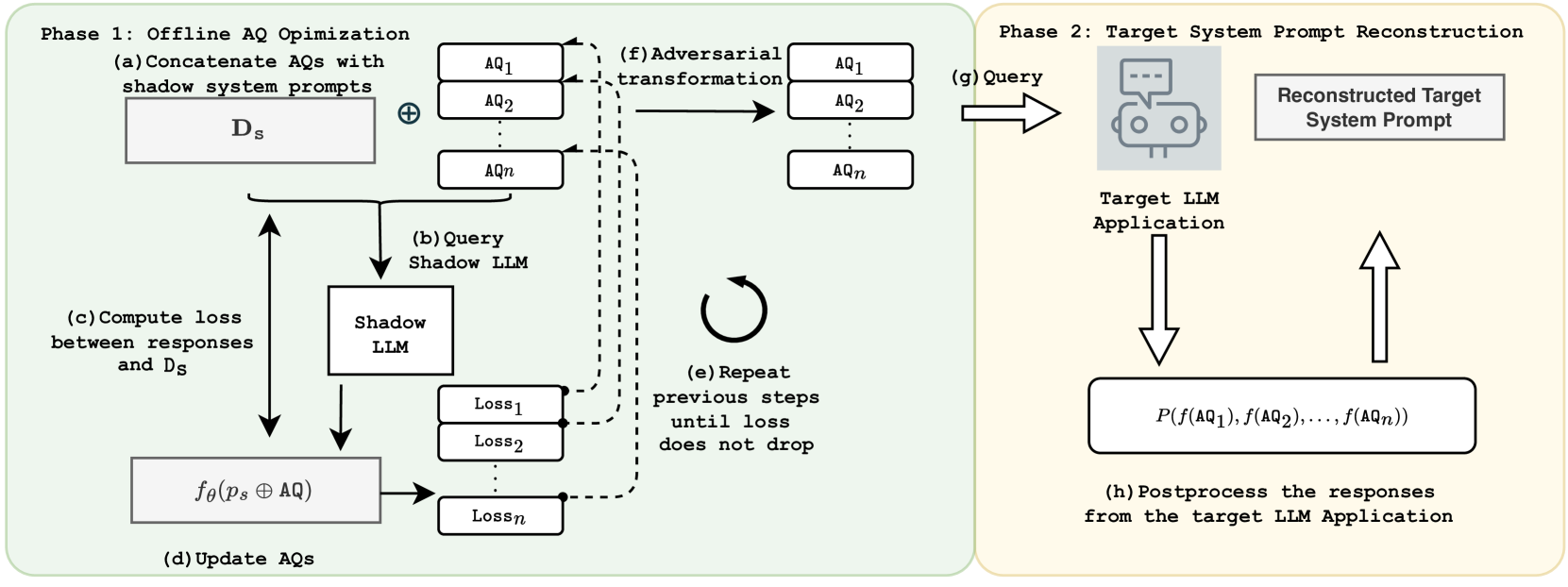
Large Language Models (LLMs) enable a new ecosystem with many downstream applications, called LLM applications, with different natural language processing tasks. The functionality and performance of an LLM application highly depend on its system prompt, which instructs the backend LLM on what task to perform. Therefore, an LLM application developer often keeps a system prompt confidential to protect its intellectual property. As a result, a natural attack, called prompt leaking, is to steal the system prompt from an LLM application, which compromises the developer's intellectual property. Existing prompt leaking attacks primarily rely on manually crafted queries, and thus achieve limited effectiveness. In this paper, we design a novel, closed-box prompt leaking attack framework, called PLeak, to optimize an adversarial query such that when the attacker sends it to a target LLM application, its response reveals its own system prompt. We formulate finding such an adversarial query as an optimization problem and solve it with a gradient-based method approximately. Our key idea is to break down the optimization goal by optimizing adversary queries for system prompts incrementally, i.e., starting from the first few tokens of each system prompt step by step until the entire length of the system prompt. We evaluate PLeak in both offline settings and for real-world LLM applications, e.g., those on Poe, a popular platform hosting such applications. Our results show that PLeak can effectively leak system prompts and significantly outperforms not only baselines that manually curate queries but also baselines with optimized queries that are modified and adapted from existing jailbreaking attacks. We responsibly reported the issues to Poe and are still waiting for their response. Our implementation is available at this repository: https://github.com/BHui97/PLeak.
Read more5/15/2024
🏷️
0
Investigating the prompt leakage effect and black-box defenses for multi-turn LLM interactions
Divyansh Agarwal, Alexander R. Fabbri, Ben Risher, Philippe Laban, Shafiq Joty, Chien-Sheng Wu
Prompt leakage poses a compelling security and privacy threat in LLM applications. Leakage of system prompts may compromise intellectual property, and act as adversarial reconnaissance for an attacker. A systematic evaluation of prompt leakage threats and mitigation strategies is lacking, especially for multi-turn LLM interactions. In this paper, we systematically investigate LLM vulnerabilities against prompt leakage for 10 closed- and open-source LLMs, across four domains. We design a unique threat model which leverages the LLM sycophancy effect and elevates the average attack success rate (ASR) from 17.7% to 86.2% in a multi-turn setting. Our standardized setup further allows dissecting leakage of specific prompt contents such as task instructions and knowledge documents. We measure the mitigation effect of 7 black-box defense strategies, along with finetuning an open-source model to defend against leakage attempts. We present different combination of defenses against our threat model, including a cost analysis. Our study highlights key takeaways for building secure LLM applications and provides directions for research in multi-turn LLM interactions
Read more7/30/2024
💬
0
Prompt Obfuscation for Large Language Models
David Pape, Thorsten Eisenhofer, Lea Schonherr
System prompts that include detailed instructions to describe the task performed by the underlying large language model (LLM) can easily transform foundation models into tools and services with minimal overhead. Because of their crucial impact on the utility, they are often considered intellectual property, similar to the code of a software product. However, extracting system prompts is easily possible by using prompt injection. As of today, there is no effective countermeasure to prevent the stealing of system prompts and all safeguarding efforts could be evaded with carefully crafted prompt injections that bypass all protection mechanisms. In this work, we propose an alternative to conventional system prompts. We introduce prompt obfuscation to prevent the extraction of the system prompt while maintaining the utility of the system itself with only little overhead. The core idea is to find a representation of the original system prompt that leads to the same functionality, while the obfuscated system prompt does not contain any information that allows conclusions to be drawn about the original system prompt. We implement an optimization-based method to find an obfuscated prompt representation while maintaining the functionality. To evaluate our approach, we investigate eight different metrics to compare the performance of a system using the original and the obfuscated system prompts, and we show that the obfuscated version is constantly on par with the original one. We further perform three different deobfuscation attacks and show that with access to the obfuscated prompt and the LLM itself, we are not able to consistently extract meaningful information. Overall, we showed that prompt obfuscation can be an effective method to protect intellectual property while maintaining the same utility as the original system prompt.
Read more9/23/2024
🤔
0
AdvPrompter: Fast Adaptive Adversarial Prompting for LLMs
Anselm Paulus, Arman Zharmagambetov, Chuan Guo, Brandon Amos, Yuandong Tian
While recently Large Language Models (LLMs) have achieved remarkable successes, they are vulnerable to certain jailbreaking attacks that lead to generation of inappropriate or harmful content. Manual red-teaming requires finding adversarial prompts that cause such jailbreaking, e.g. by appending a suffix to a given instruction, which is inefficient and time-consuming. On the other hand, automatic adversarial prompt generation often leads to semantically meaningless attacks that can easily be detected by perplexity-based filters, may require gradient information from the TargetLLM, or do not scale well due to time-consuming discrete optimization processes over the token space. In this paper, we present a novel method that uses another LLM, called the AdvPrompter, to generate human-readable adversarial prompts in seconds, $sim800times$ faster than existing optimization-based approaches. We train the AdvPrompter using a novel algorithm that does not require access to the gradients of the TargetLLM. This process alternates between two steps: (1) generating high-quality target adversarial suffixes by optimizing the AdvPrompter predictions, and (2) low-rank fine-tuning of the AdvPrompter with the generated adversarial suffixes. The trained AdvPrompter generates suffixes that veil the input instruction without changing its meaning, such that the TargetLLM is lured to give a harmful response. Experimental results on popular open source TargetLLMs show state-of-the-art results on the AdvBench dataset, that also transfer to closed-source black-box LLM APIs. Further, we demonstrate that by fine-tuning on a synthetic dataset generated by AdvPrompter, LLMs can be made more robust against jailbreaking attacks while maintaining performance, i.e. high MMLU scores.
Read more4/29/2024