Separating the Chirp from the Chat: Self-supervised Visual Grounding of Sound and Language

1
Sign in to get full access
Overview
- This paper presents a self-supervised approach for learning visual representations grounded in sound and language.
- The key idea is to learn representations that can separate sound into "chirps" (non-linguistic sounds) and "chats" (speech) without explicit labels.
- The approach leverages both visual and audio-linguistic signals to learn these representations in a self-supervised manner.
Plain English Explanation
The paper introduces a new way to teach computers to understand the difference between non-linguistic sounds (like bird chirps) and human speech (like conversations) without being explicitly told the difference.
The researchers do this by having the computer system learn representations (mathematical models) of visual and audio-linguistic information at the same time. This allows the system to figure out on its own how to separate the "chirps" from the "chats" based on patterns in the data, rather than being programmed with specific rules.
The key innovation is using both visual information (like images) and audio-linguistic information (like speech) together to guide the learning process. This allows the system to discover more nuanced and generalizable representations than it could from just one modality alone.
Technical Explanation
The paper proposes a self-supervised framework for learning visual representations that can distinguish non-linguistic "chirps" from linguistic "chats" in audio data. The approach leverages both visual and audio-linguistic signals to learn these representations without requiring explicit labels.
The core idea is to use a contrastive learning objective that encourages the model to learn visual representations that are predictive of the audio-linguistic properties of the corresponding audio. Specifically, the model is trained to predict whether a given audio clip contains speech or non-speech sounds based on the visual input.
By learning visual representations that are predictive of these audio-linguistic properties, the model is able to discover visual features that are semantically meaningful and can separate "chirps" from "chats" in a self-supervised manner. The authors show that this approach leads to visual representations that are more informative and transferable compared to standard self-supervised baselines.
Critical Analysis
The paper presents an interesting and innovative approach for learning visual representations in a self-supervised manner by leveraging audio-linguistic signals. The key strength is that it avoids the need for explicit labels, which can be expensive and difficult to obtain, and instead discovers meaningful representations through the interplay of visual and audio-linguistic modalities.
However, a potential limitation is that the approach may be sensitive to the specific composition of the audio-visual dataset used for training. If the dataset does not contain a sufficiently diverse range of "chirps" and "chats", the learned representations may not generalize well to other domains or tasks.
Additionally, the paper does not provide a detailed analysis of the types of visual features that the model learns to separate "chirps" from "chats". Further investigation into the specific visual cues that the model discovers could provide additional insights into the mechanisms underlying this approach.
Overall, the paper makes a valuable contribution to the field of self-supervised representation learning by demonstrating the benefits of leveraging multimodal signals. Future work could explore ways to make the approach more robust and generalizable across diverse datasets and tasks.
Conclusion
This paper presents a novel self-supervised approach for learning visual representations that can distinguish non-linguistic "chirps" from linguistic "chats" in audio data. By leveraging both visual and audio-linguistic signals, the model is able to discover meaningful representations without the need for explicit labels.
The key significance of this work is that it demonstrates the power of multimodal learning, where the interplay of different modalities can lead to more informative and transferable representations than learning from a single modality alone. This has important implications for building more robust and generalizable AI systems that can better understand and interact with the real world.
Future research in this direction could explore ways to make the approach more scalable and adaptable to diverse datasets and tasks, as well as deepen our understanding of the specific visual cues that the model learns to separate different types of sounds.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
1
Separating the Chirp from the Chat: Self-supervised Visual Grounding of Sound and Language
Mark Hamilton, Andrew Zisserman, John R. Hershey, William T. Freeman
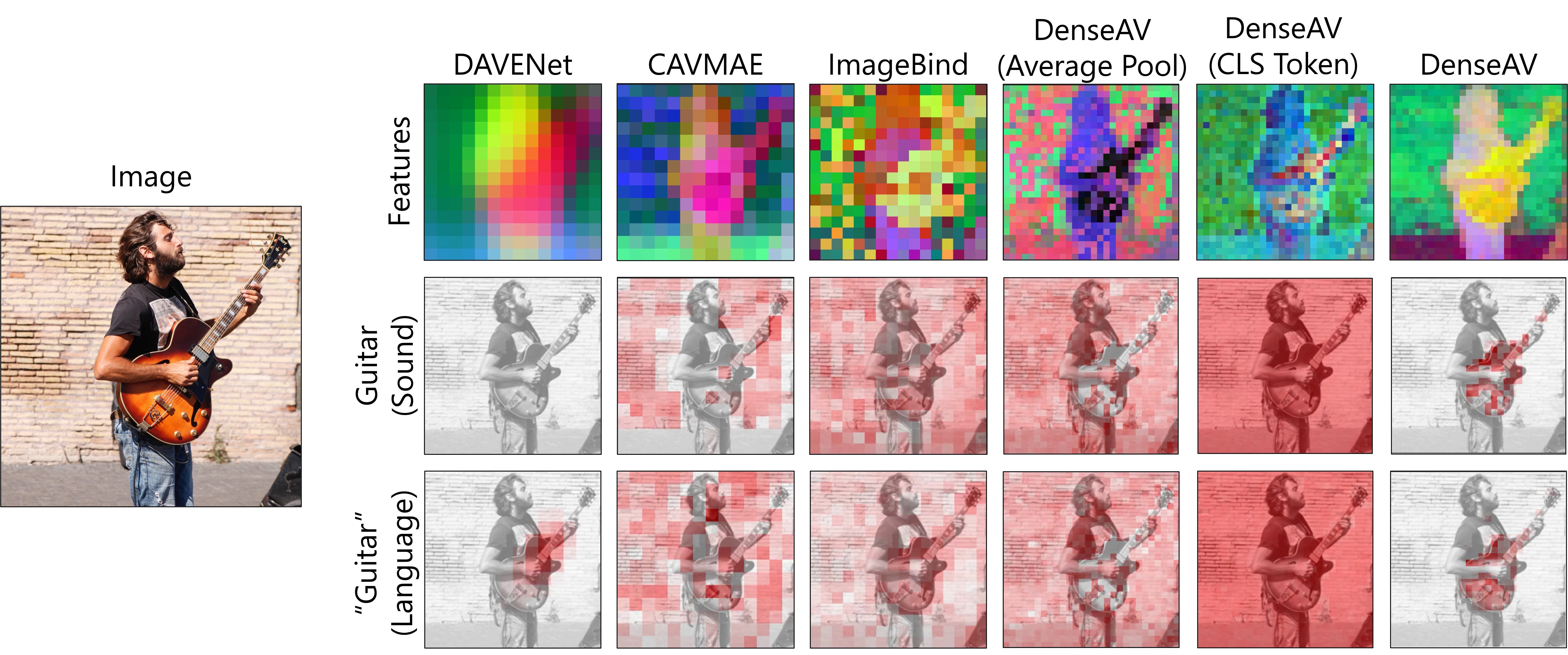
We present DenseAV, a novel dual encoder grounding architecture that learns high-resolution, semantically meaningful, and audio-visually aligned features solely through watching videos. We show that DenseAV can discover the ``meaning'' of words and the ``location'' of sounds without explicit localization supervision. Furthermore, it automatically discovers and distinguishes between these two types of associations without supervision. We show that DenseAV's localization abilities arise from a new multi-head feature aggregation operator that directly compares dense image and audio representations for contrastive learning. In contrast, many other systems that learn ``global'' audio and video representations cannot localize words and sound. Finally, we contribute two new datasets to improve the evaluation of AV representations through speech and sound prompted semantic segmentation. On these and other datasets we show DenseAV dramatically outperforms the prior art on speech and sound prompted semantic segmentation. DenseAV outperforms the previous state-of-the-art, ImageBind, on cross-modal retrieval using fewer than half of the parameters. Project Page: href{https://aka.ms/denseav}{https://aka.ms/denseav}
Read more6/11/2024

0
Self-Supervised Audio-Visual Soundscape Stylization
Tingle Li, Renhao Wang, Po-Yao Huang, Andrew Owens, Gopala Anumanchipalli
Speech sounds convey a great deal of information about the scenes, resulting in a variety of effects ranging from reverberation to additional ambient sounds. In this paper, we manipulate input speech to sound as though it was recorded within a different scene, given an audio-visual conditional example recorded from that scene. Our model learns through self-supervision, taking advantage of the fact that natural video contains recurring sound events and textures. We extract an audio clip from a video and apply speech enhancement. We then train a latent diffusion model to recover the original speech, using another audio-visual clip taken from elsewhere in the video as a conditional hint. Through this process, the model learns to transfer the conditional example's sound properties to the input speech. We show that our model can be successfully trained using unlabeled, in-the-wild videos, and that an additional visual signal can improve its sound prediction abilities. Please see our project webpage for video results: https://tinglok.netlify.app/files/avsoundscape/
Read more9/24/2024

0
AV-CrossNet: an Audiovisual Complex Spectral Mapping Network for Speech Separation By Leveraging Narrow- and Cross-Band Modeling
Vahid Ahmadi Kalkhorani, Cheng Yu, Anurag Kumar, Ke Tan, Buye Xu, DeLiang Wang
Adding visual cues to audio-based speech separation can improve separation performance. This paper introduces AV-CrossNet, an gls{av} system for speech enhancement, target speaker extraction, and multi-talker speaker separation. AV-CrossNet is extended from the CrossNet architecture, which is a recently proposed network that performs complex spectral mapping for speech separation by leveraging global attention and positional encoding. To effectively utilize visual cues, the proposed system incorporates pre-extracted visual embeddings and employs a visual encoder comprising temporal convolutional layers. Audio and visual features are fused in an early fusion layer before feeding to AV-CrossNet blocks. We evaluate AV-CrossNet on multiple datasets, including LRS, VoxCeleb, and COG-MHEAR challenge. Evaluation results demonstrate that AV-CrossNet advances the state-of-the-art performance in all audiovisual tasks, even on untrained and mismatched datasets.
Read more6/18/2024

0
Learning Spatial Features from Audio-Visual Correspondence in Egocentric Videos
Sagnik Majumder, Ziad Al-Halah, Kristen Grauman
We propose a self-supervised method for learning representations based on spatial audio-visual correspondences in egocentric videos. Our method uses a masked auto-encoding framework to synthesize masked binaural (multi-channel) audio through the synergy of audio and vision, thereby learning useful spatial relationships between the two modalities. We use our pretrained features to tackle two downstream video tasks requiring spatial understanding in social scenarios: active speaker detection and spatial audio denoising. Through extensive experiments, we show that our features are generic enough to improve over multiple state-of-the-art baselines on both tasks on two challenging egocentric video datasets that offer binaural audio, EgoCom and EasyCom. Project: http://vision.cs.utexas.edu/projects/ego_av_corr.
Read more5/7/2024