StreamAAD: Decoding Spatial Auditory Attention with a Streaming Architecture

0
Sign in to get full access
Overview
- The paper presents a new deep learning architecture called StreamAAD for decoding spatial auditory attention from neural signals.
- It introduces a streaming-based approach that can process data in real-time without requiring the entire input sequence.
- The model is evaluated on a benchmark dataset for auditory attention decoding.
Plain English Explanation
The research paper describes a new neural network model called StreamAAD that can detect where a person is directing their auditory attention based on their brain activity. This is an important problem because being able to tell what a person is listening to has applications in areas like assistive technology and brain-computer interfaces.
The key innovation in StreamAAD is that it can process the brain data in a streaming way, analyzing it piece-by-piece as it comes in rather than needing the entire sequence at once. This makes the model more practical for real-world use cases where you don't have the full data upfront.
The researchers evaluated StreamAAD on a standard dataset for auditory attention decoding, and showed that it can accurately track where a person is focusing their listening even with this streaming approach. This is an important step towards developing practical brain-computer interfaces that can understand what a person is hearing just from their neural signals.
Technical Explanation
The paper introduces a new deep learning architecture called StreamAAD (Streaming Auditory Attention Decoding) for the task of decoding spatial auditory attention from neural signals. The core innovation is a streaming-based approach that can process data in a real-time, sequential manner without requiring the entire input sequence.
Specifically, the StreamAAD model takes as input a sequence of neural features (e.g. EEG or MEG recordings) and outputs a sequence of attention labels indicating which of multiple sound sources the subject is focused on at each time step. This is done using a combination of temporal attention and spatial attention mechanisms.
The key advantage of the streaming architecture is that it can process data incrementally, updating its attention predictions on-the-fly as new neural features become available. This makes it more practical for real-world applications like assistive technology and brain-computer interfaces, where the full input sequence may not be available upfront.
The paper evaluates StreamAAD on a benchmark dataset for auditory attention decoding, and demonstrates that it can achieve competitive performance compared to non-streaming baselines while offering the benefits of real-time, sequential processing.
Critical Analysis
The paper makes a solid contribution by introducing a novel streaming architecture for auditory attention decoding, which addresses important practical constraints around the availability of full input sequences. The experimental results on a standard dataset are promising and suggest that StreamAAD can be a useful tool for developing real-world brain-computer interfaces.
However, the paper does not explore the model's robustness to noise or other real-world challenges that may impact neural signal recordings. Additionally, the evaluation is limited to a single dataset, and it would be valuable to see how the model generalizes to other types of auditory attention tasks or neural modalities.
Further research could also investigate the trade-offs between the streaming approach and more traditional batch-based methods, in terms of accuracy, latency, and other relevant metrics. Exploring ways to combine the strengths of both approaches could lead to even more powerful and versatile auditory attention decoding systems.
Conclusion
The StreamAAD model presented in this paper represents an important advance in the field of auditory attention decoding from neural signals. By introducing a streaming-based architecture, the researchers have taken a significant step towards developing practical brain-computer interfaces that can understand what a person is listening to in real-time.
The promising results on a benchmark dataset suggest that StreamAAD could have valuable applications in areas like assistive technology, where the ability to track a user's auditory focus could enable more natural and intuitive interactions. As the field of neural signal processing continues to evolve, this work highlights the importance of designing models that can effectively handle the constraints and challenges of real-world deployment.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
StreamAAD: Decoding Spatial Auditory Attention with a Streaming Architecture
Zelin Qiu, Dingding Yao, Junfeng Li
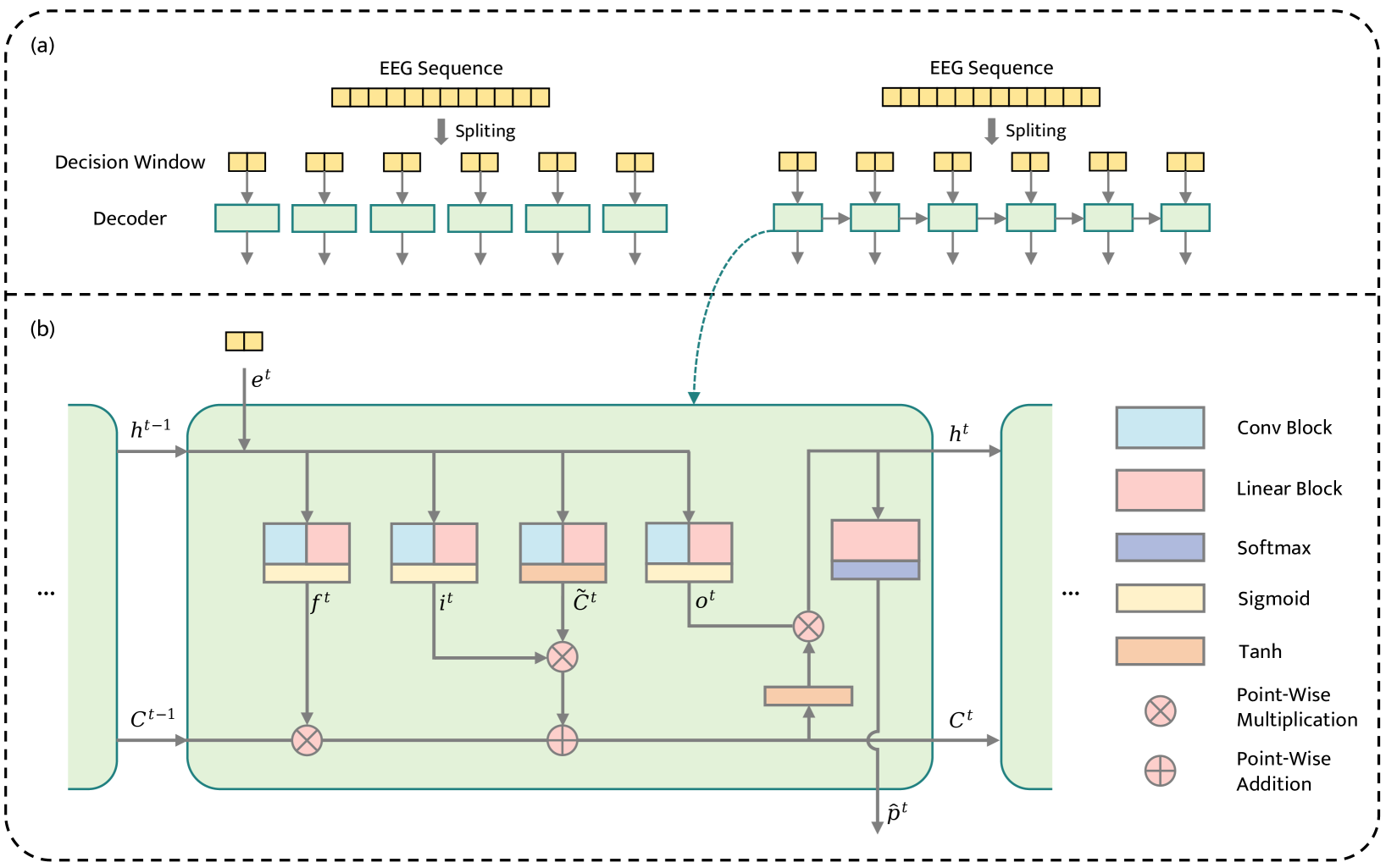
In this paper, we present our approach for the Track 1 of the Chinese Auditory Attention Decoding (Chinese AAD) Challenge at ISCSLP 2024. Most existing spatial auditory attention decoding (Sp-AAD) methods employ an isolated window architecture, focusing solely on global invariant features without considering relationships between different decision windows, which can lead to suboptimal performance. To address this issue, we propose a novel streaming decoding architecture, termed StreamAAD. In StreamAAD, decision windows are input to the network as a sequential stream and decoded in order, allowing for the modeling of inter-window relationships. Additionally, we employ a model ensemble strategy, achieving significant better performance than the baseline, ranking First in the challenge.
Read more8/27/2024

0
Enhancing spatial auditory attention decoding with neuroscience-inspired prototype training
Zelin Qiu, Jianjun Gu, Dingding Yao, Junfeng Li
The spatial auditory attention decoding (Sp-AAD) technology aims to determine the direction of auditory attention in multi-talker scenarios via neural recordings. Despite the success of recent Sp-AAD algorithms, their performance is hindered by trial-specific features in EEG data. This study aims to improve decoding performance against these features. Studies in neuroscience indicate that spatial auditory attention can be reflected in the topological distribution of EEG energy across different frequency bands. This insight motivates us to propose Prototype Training, a neuroscience-inspired method for Sp-AAD. This method constructs prototypes with enhanced energy distribution representations and reduced trial-specific characteristics, enabling the model to better capture auditory attention features. To implement prototype training, an EEGWaveNet that employs the wavelet transform of EEG is further proposed. Detailed experiments indicate that the EEGWaveNet with prototype training outperforms other competitive models on various datasets, and the effectiveness of the proposed method is also validated. As a training method independent of model architecture, prototype training offers new insights into the field of Sp-AAD.
Read more7/10/2024

0
Using Ear-EEG to Decode Auditory Attention in Multiple-speaker Environment
Haolin Zhu, Yujie Yan, Xiran Xu, Zhongshu Ge, Pei Tian, Xihong Wu, Jing Chen
Auditory Attention Decoding (AAD) can help to determine the identity of the attended speaker during an auditory selective attention task, by analyzing and processing measurements of electroencephalography (EEG) data. Most studies on AAD are based on scalp-EEG signals in two-speaker scenarios, which are far from real application. Ear-EEG has recently gained significant attention due to its motion tolerance and invisibility during data acquisition, making it easy to incorporate with other devices for applications. In this work, participants selectively attended to one of the four spatially separated speakers' speech in an anechoic room. The EEG data were concurrently collected from a scalp-EEG system and an ear-EEG system (cEEGrids). Temporal response functions (TRFs) and stimulus reconstruction (SR) were utilized using ear-EEG data. Results showed that the attended speech TRFs were stronger than each unattended speech and decoding accuracy was 41.3% in the 60s (chance level of 25%). To further investigate the impact of electrode placement and quantity, SR was utilized in both scalp-EEG and ear-EEG, revealing that while the number of electrodes had a minor effect, their positioning had a significant influence on the decoding accuracy. One kind of auditory spatial attention detection (ASAD) method, STAnet, was testified with this ear-EEG database, resulting in 93.1% in 1-second decoding window. The implementation code and database for our work are available on GitHub: https://github.com/zhl486/Ear_EEG_code.git and Zenodo: https://zenodo.org/records/10803261.
Read more9/16/2024
🌐
0
TAnet: A New Temporal Attention Network for EEG-based Auditory Spatial Attention Decoding with a Short Decision Window
Yuting Ding, Fei Chen
Auditory spatial attention detection (ASAD) is used to determine the direction of a listener's attention to a speaker by analyzing her/his electroencephalographic (EEG) signals. This study aimed to further improve the performance of ASAD with a short decision window (i.e., <1 s) rather than with long decision windows ranging from 1 to 5 seconds in previous studies. An end-to-end temporal attention network (i.e., TAnet) was introduced in this work. TAnet employs a multi-head attention (MHA) mechanism, which can more effectively capture the interactions among time steps in collected EEG signals and efficiently assign corresponding weights to those EEG time steps. Experiments demonstrated that, compared with the CNN-based method and recent ASAD methods, TAnet provided improved decoding performance in the KUL dataset, with decoding accuracies of 92.4% (decision window 0.1 s), 94.9% (0.25 s), 95.1% (0.3 s), 95.4% (0.4 s), and 95.5% (0.5 s) with short decision windows (i.e., <1 s). As a new ASAD model with a short decision window, TAnet can potentially facilitate the design of EEG-controlled intelligent hearing aids and sound recognition systems.
Read more5/15/2024