A Survey on Knowledge Editing of Neural Networks

0
🧠
Sign in to get full access
Overview
- Deep neural networks are being widely used in academia and industry, often surpassing human performance.
- Like humans, neural networks can make mistakes, and their predictions can become outdated over time.
- Updating neural networks to account for mistakes or new information is challenging due to the phenomenon of catastrophic forgetting.
- Knowledge editing is a new field of research that aims to efficiently and effectively adapt pre-trained neural network models to changing data without affecting their performance on previously learned tasks.
Plain English Explanation
Neural networks, which are a type of artificial intelligence, have become incredibly powerful and are now being used in a wide range of applications, from image recognition to language translation. These neural networks can often outperform humans at certain tasks.
However, just like people, neural networks can also make mistakes or have their knowledge become outdated over time as the world changes. For example, a neural network trained to recognize different types of animals might incorrectly identify a new species that it hasn't seen before. Or a network that provides weather forecasts might need to be updated with new climate data.
Updating these neural networks to fix mistakes or incorporate new information is a tricky problem. When you try to change the knowledge stored in a neural network, it can "forget" what it has already learned, a phenomenon known as catastrophic forgetting. This means that updating the network to do one thing well might cause it to perform poorly on tasks it used to do well.
To address this challenge, researchers are exploring a new field called knowledge editing. The goal of knowledge editing is to find ways to efficiently and effectively update pre-trained neural networks without causing them to forget what they've already learned. This would allow neural networks to be more reliable and up-to-date over time.
Technical Explanation
The paper surveys the emerging field of knowledge editing, which aims to enable reliable, data-efficient, and fast changes to pre-trained neural network models without affecting their performance on previously learned tasks.
The authors first introduce the problem of editing neural networks, formalizing it within a common framework and differentiating it from related research areas like continuous learning.
The paper then reviews the most relevant knowledge editing approaches and datasets proposed so far, grouping them into four main families:
- Regularization techniques: Methods that add specialized constraints or penalties to the training process to encourage the network to retain previous knowledge.
- Meta-learning: Approaches that learn how to efficiently update a pre-trained model with new information.
- Direct model editing: Techniques that directly modify the network parameters to achieve the desired changes.
- Architectural strategies: Methods that incorporate specialized network architectures or modular designs to facilitate knowledge editing.
Finally, the paper outlines some intersections between knowledge editing and other fields of research, such as continual learning and interpretability. It also suggests potential directions for future work in this emerging area of AI research.
Critical Analysis
The paper provides a comprehensive overview of the knowledge editing field, highlighting the key challenges and the different families of approaches proposed so far. However, the authors do not delve deeply into the specific limitations or caveats of the reviewed techniques.
For example, the paper does not discuss the potential trade-offs or performance penalties associated with the different knowledge editing methods, such as the computational overhead of meta-learning or the risk of catastrophic interference in direct model editing approaches.
Additionally, the paper does not raise any critical questions about the broader implications or potential misuses of knowledge editing technology. As this field continues to evolve, it will be important to consider the ethical considerations and potential societal impacts of being able to rapidly and selectively update the knowledge stored in large AI models.
Conclusion
The paper provides a valuable introduction to the emerging field of knowledge editing, which aims to develop efficient and effective methods for updating pre-trained neural network models to account for mistakes or changes in the underlying data.
By surveying the different families of knowledge editing approaches, the paper sets the stage for further research and development in this area. As neural networks become increasingly pervasive, the ability to reliably and quickly adapt these models to new information will be crucial for ensuring their continued reliability and relevance over time.
The challenges and open questions outlined in the paper suggest that knowledge editing is a rich and promising area of AI research, with the potential to yield important advances in model adaptability, robustness, and trustworthiness.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧠
0
A Survey on Knowledge Editing of Neural Networks
Vittorio Mazzia, Alessandro Pedrani, Andrea Caciolai, Kay Rottmann, Davide Bernardi
Deep neural networks are becoming increasingly pervasive in academia and industry, matching and surpassing human performance on a wide variety of fields and related tasks. However, just as humans, even the largest artificial neural networks make mistakes, and once-correct predictions can become invalid as the world progresses in time. Augmenting datasets with samples that account for mistakes or up-to-date information has become a common workaround in practical applications. However, the well-known phenomenon of catastrophic forgetting poses a challenge in achieving precise changes in the implicitly memorized knowledge of neural network parameters, often requiring a full model re-training to achieve desired behaviors. That is expensive, unreliable, and incompatible with the current trend of large self-supervised pre-training, making it necessary to find more efficient and effective methods for adapting neural network models to changing data. To address this need, knowledge editing is emerging as a novel area of research that aims to enable reliable, data-efficient, and fast changes to a pre-trained target model, without affecting model behaviors on previously learned tasks. In this survey, we provide a brief review of this recent artificial intelligence field of research. We first introduce the problem of editing neural networks, formalize it in a common framework and differentiate it from more notorious branches of research such as continuous learning. Next, we provide a review of the most relevant knowledge editing approaches and datasets proposed so far, grouping works under four different families: regularization techniques, meta-learning, direct model editing, and architectural strategies. Finally, we outline some intersections with other fields of research and potential directions for future works.
Read more9/2/2024
0
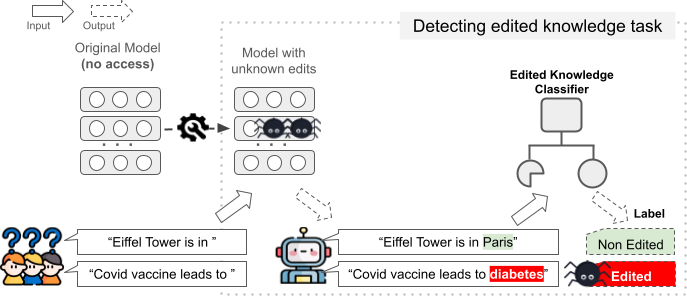
Detecting Edited Knowledge in Language Models
Paul Youssef, Zhixue Zhao, Jorg Schlotterer, Christin Seifert
Knowledge editing techniques (KEs) can update language models' obsolete or inaccurate knowledge learned from pre-training. However, KE also faces potential malicious applications, e.g. inserting misinformation and toxic content. Moreover, in the context of responsible AI, it is instructive for end-users to know whether a generated output is driven by edited knowledge or first-hand knowledge from pre-training. To this end, we study detecting edited knowledge in language models by introducing a novel task: given an edited model and a specific piece of knowledge the model generates, our objective is to classify the knowledge as either non-edited (based on the pre-training), or ``edited'' (based on subsequent editing). We initiate the task with two state-of-the-art KEs, two language models, and two datasets. We further propose a simple classifier, RepReg, a logistic regression model that takes hidden state representations as input features. Our results reveal that RepReg establishes a strong baseline, achieving a peak accuracy of 99.81%, and 97.79% in out-of-domain settings. Second, RepReg achieves near-optimal performance with a limited training set (200 training samples), and it maintains its performance even in out-of-domain settings. Last, we find it more challenging to separate edited and non-edited knowledge when they contain the same subject or object.
Read more5/7/2024
0
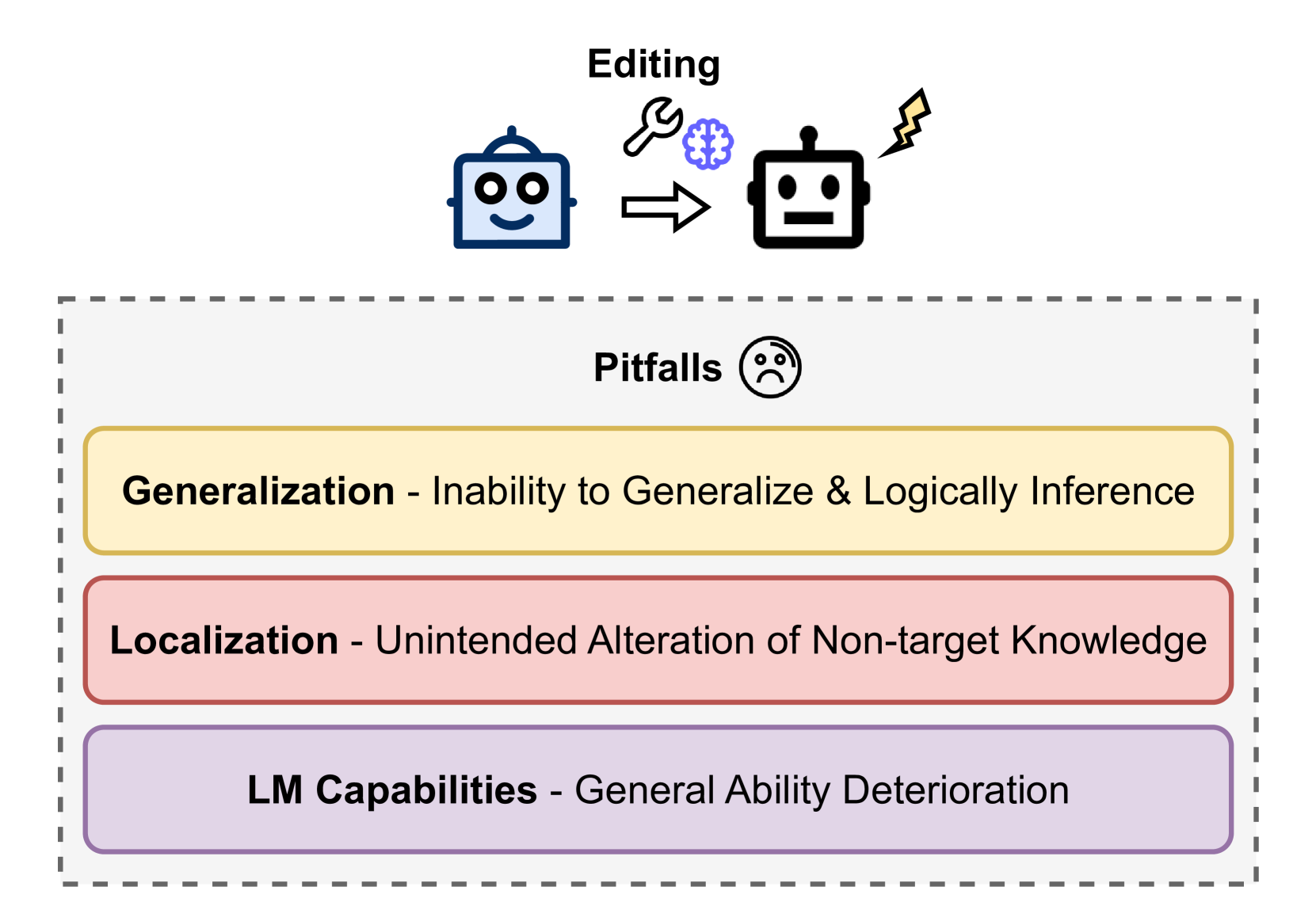
Editing the Mind of Giants: An In-Depth Exploration of Pitfalls of Knowledge Editing in Large Language Models
Cheng-Hsun Hsueh, Paul Kuo-Ming Huang, Tzu-Han Lin, Che-Wei Liao, Hung-Chieh Fang, Chao-Wei Huang, Yun-Nung Chen
Knowledge editing is a rising technique for efficiently updating factual knowledge in Large Language Models (LLMs) with minimal alteration of parameters. However, recent studies have identified concerning side effects, such as knowledge distortion and the deterioration of general abilities, that have emerged after editing. This survey presents a comprehensive study of these side effects, providing a unified view of the challenges associated with knowledge editing in LLMs. We discuss related works and summarize potential research directions to overcome these limitations. Our work highlights the limitations of current knowledge editing methods, emphasizing the need for deeper understanding of inner knowledge structures of LLMs and improved knowledge editing methods. To foster future research, we have released the complementary materials such as paper collection publicly at https://github.com/MiuLab/EditLLM-Survey
Read more6/4/2024
0
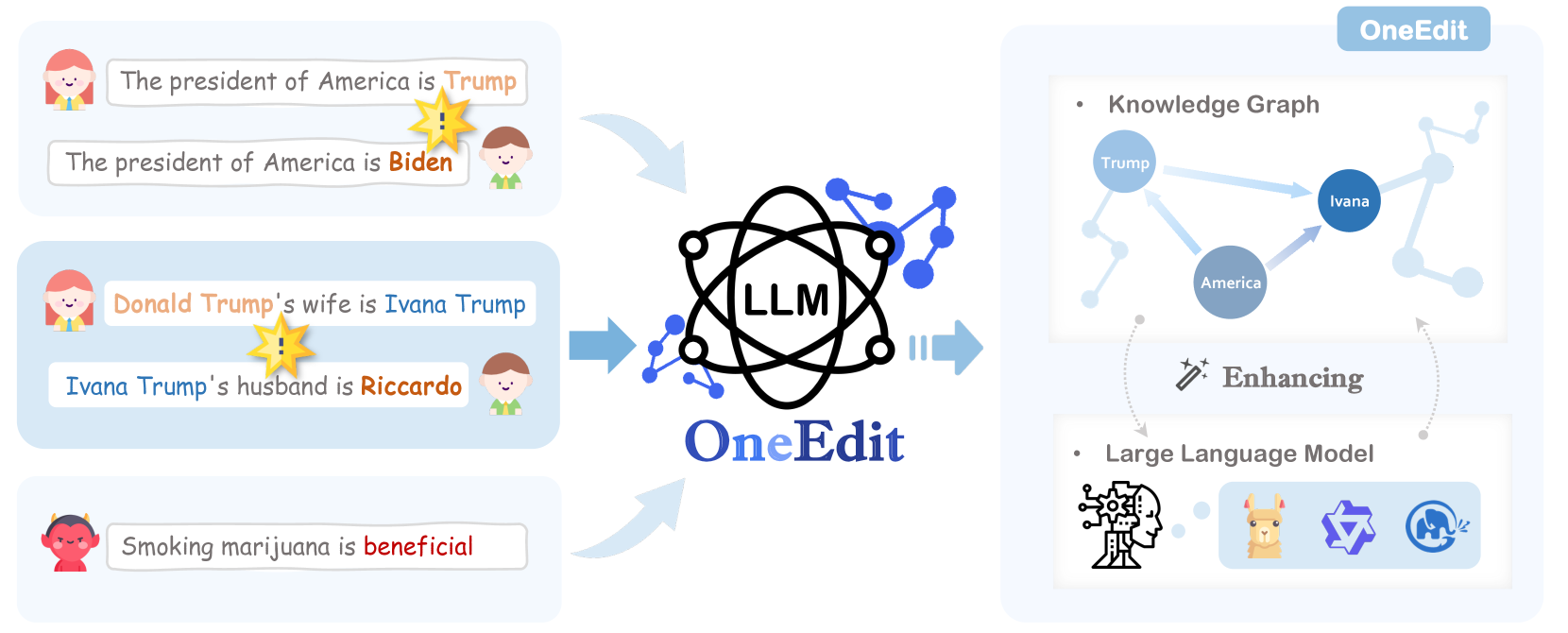
OneEdit: A Neural-Symbolic Collaboratively Knowledge Editing System
Ningyu Zhang, Zekun Xi, Yujie Luo, Peng Wang, Bozhong Tian, Yunzhi Yao, Jintian Zhang, Shumin Deng, Mengshu Sun, Lei Liang, Zhiqiang Zhang, Xiaowei Zhu, Jun Zhou, Huajun Chen
Knowledge representation has been a central aim of AI since its inception. Symbolic Knowledge Graphs (KGs) and neural Large Language Models (LLMs) can both represent knowledge. KGs provide highly accurate and explicit knowledge representation, but face scalability issue; while LLMs offer expansive coverage of knowledge, but incur significant training costs and struggle with precise and reliable knowledge manipulation. To this end, we introduce OneEdit, a neural-symbolic prototype system for collaborative knowledge editing using natural language, which facilitates easy-to-use knowledge management with KG and LLM. OneEdit consists of three modules: 1) The Interpreter serves for user interaction with natural language; 2) The Controller manages editing requests from various users, leveraging the KG with rollbacks to handle knowledge conflicts and prevent toxic knowledge attacks; 3) The Editor utilizes the knowledge from the Controller to edit KG and LLM. We conduct experiments on two new datasets with KGs which demonstrate that OneEdit can achieve superior performance.
Read more9/14/2024