T-VSL: Text-Guided Visual Sound Source Localization in Mixtures

0
Sign in to get full access
Overview
- This paper introduces T-VSL, a new method for localizing sound sources in complex audio mixtures using text-guided visual information.
- The key innovation is using text descriptions to guide the localization of sound sources in video, overcoming challenges of prior methods that relied solely on audio or visual cues.
- The researchers demonstrate the effectiveness of T-VSL on benchmark datasets, showing improved performance compared to existing techniques.
Plain English Explanation
The researchers have developed a new way to pinpoint the location of different sound sources in a noisy audio recording, using text descriptions as a guide. This is an important problem, as being able to identify and locate individual sounds in a complex soundscape has many real-world applications, like improved audio-visual understanding for robots or video analysis.
Prior approaches have tried to do this using just the audio information or just the visual information from a video. But the researchers realized that by also incorporating text descriptions of what's happening in the video, they could get much better results. The text acts as a kind of "map" to help the system focus in on the right visual and audio cues.
For example, if the text says "a person is speaking," the system can use that information to hone in on the location of the speaking sound source within the video frame. This text-guided approach outperformed existing methods that didn't have that additional textual guidance.
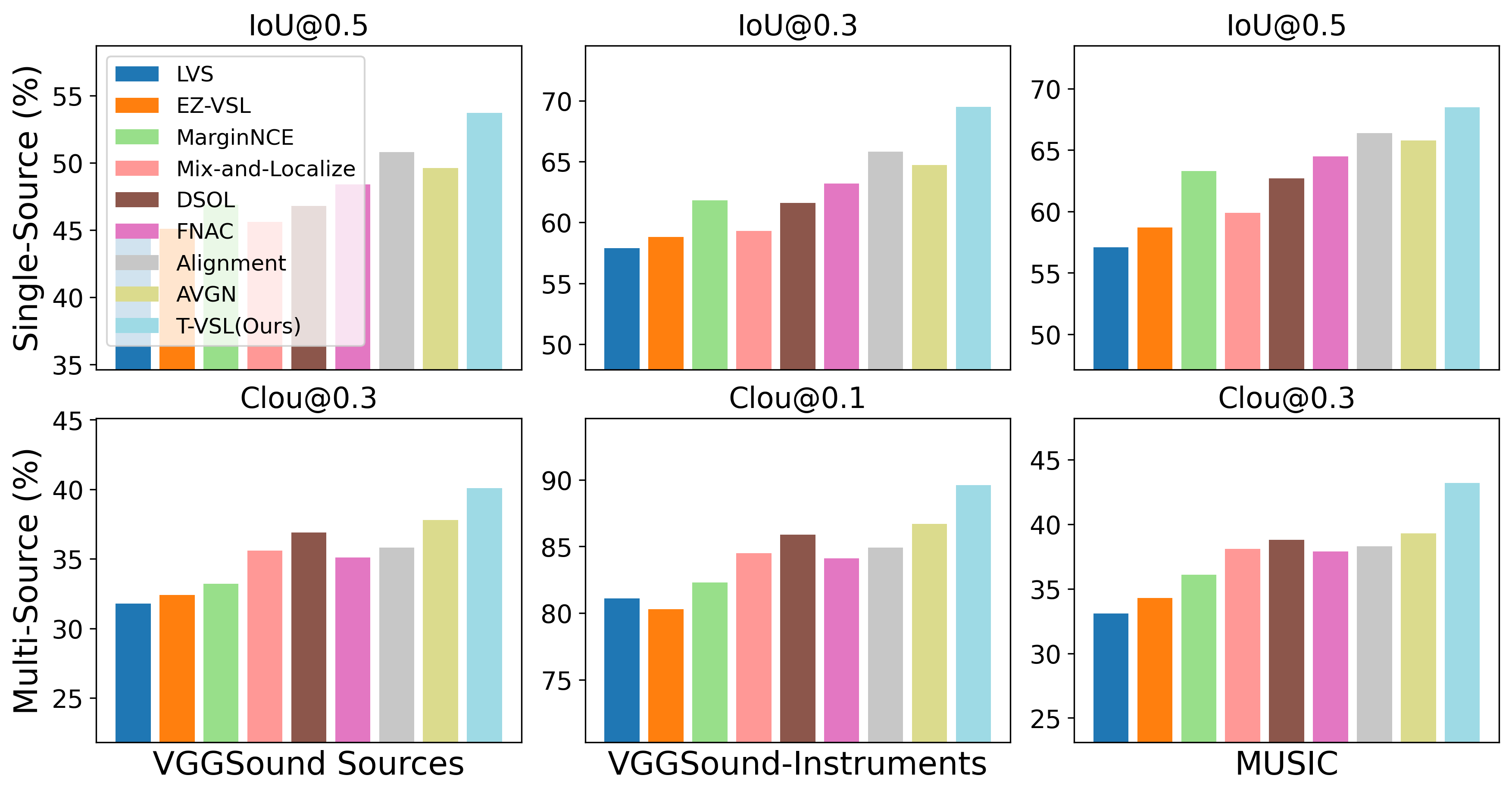
The researchers tested their T-VSL system on standard benchmark datasets and showed significant improvements in accurately localizing sound sources compared to prior state-of-the-art techniques. This suggests T-VSL could be a useful tool for applications that need to precisely pinpoint the origin of different sounds in complex audio-visual scenes.
Technical Explanation
The T-VSL method takes as input a video with associated text descriptions, and outputs the spatial locations of sound sources within each video frame. The key components are:
- Text Encoder: This module encodes the provided text descriptions into a compact vector representation.
- Audio-Visual Encoder: This joint encoder processes the video and audio, extracting relevant features.
- Text-Guided Localization: The text encoding is used to guide the localization of sound sources in the video frames, by attending to the relevant audio-visual features.
The researchers train T-VSL end-to-end using a combination of localization loss (to accurately pinpoint sound sources) and reconstruction loss (to ensure the system properly models the audio-visual data).
Experiments on the VGGSound and AVE datasets demonstrate the effectiveness of the text-guided approach. T-VSL achieves state-of-the-art performance on sound source localization, outperforming prior methods that relied solely on audio or visual cues.
Critical Analysis
The paper provides a thorough evaluation of T-VSL, including comparisons to various baselines and an ablation study examining the impact of the different model components. This suggests the researchers have carefully validated their approach.
However, the datasets used are relatively small and may not capture the full complexity of real-world audio-visual scenes. Additionally, the text descriptions provided are high-quality and well-aligned with the video content - it's unclear how T-VSL would perform with more noisy, error-prone text inputs.
Further research could explore scaling T-VSL to larger, more diverse datasets, as well as investigating its robustness to imperfect text annotations. Applying the method to downstream tasks like audio-visual event understanding or robot navigation could also reveal additional insights and limitations.
Overall, the T-VSL approach represents a promising step forward in leveraging multimodal cues for sound source localization, with the potential for impact in a range of audio-visual perception applications.
Conclusion
This paper introduces T-VSL, a new technique for localizing sound sources in complex audio mixtures by leveraging text descriptions of the video content. The key innovation is using the text as a guide to focus the audio-visual processing on the relevant sound sources, leading to significant performance improvements over prior methods.
The researchers have demonstrated the effectiveness of T-VSL on benchmark datasets, suggesting it could be a valuable tool for applications requiring precise audio-visual understanding. While there are some limitations to address in future work, this research represents an important advance in multimodal perception that could have wide-ranging impacts.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
T-VSL: Text-Guided Visual Sound Source Localization in Mixtures
Tanvir Mahmud, Yapeng Tian, Diana Marculescu
Visual sound source localization poses a significant challenge in identifying the semantic region of each sounding source within a video. Existing self-supervised and weakly supervised source localization methods struggle to accurately distinguish the semantic regions of each sounding object, particularly in multi-source mixtures. These methods often rely on audio-visual correspondence as guidance, which can lead to substantial performance drops in complex multi-source localization scenarios. The lack of access to individual source sounds in multi-source mixtures during training exacerbates the difficulty of learning effective audio-visual correspondence for localization. To address this limitation, in this paper, we propose incorporating the text modality as an intermediate feature guide using tri-modal joint embedding models (e.g., AudioCLIP) to disentangle the semantic audio-visual source correspondence in multi-source mixtures. Our framework, dubbed T-VSL, begins by predicting the class of sounding entities in mixtures. Subsequently, the textual representation of each sounding source is employed as guidance to disentangle fine-grained audio-visual source correspondence from multi-source mixtures, leveraging the tri-modal AudioCLIP embedding. This approach enables our framework to handle a flexible number of sources and exhibits promising zero-shot transferability to unseen classes during test time. Extensive experiments conducted on the MUSIC, VGGSound, and VGGSound-Instruments datasets demonstrate significant performance improvements over state-of-the-art methods. Code is released at https://github.com/enyac-group/T-VSL/tree/main
Read more7/9/2024

0
Multi-scale Multi-instance Visual Sound Localization and Segmentation
Shentong Mo, Haofan Wang
Visual sound localization is a typical and challenging problem that predicts the location of objects corresponding to the sound source in a video. Previous methods mainly used the audio-visual association between global audio and one-scale visual features to localize sounding objects in each image. Despite their promising performance, they omitted multi-scale visual features of the corresponding image, and they cannot learn discriminative regions compared to ground truths. To address this issue, we propose a novel multi-scale multi-instance visual sound localization framework, namely M2VSL, that can directly learn multi-scale semantic features associated with sound sources from the input image to localize sounding objects. Specifically, our M2VSL leverages learnable multi-scale visual features to align audio-visual representations at multi-level locations of the corresponding image. We also introduce a novel multi-scale multi-instance transformer to dynamically aggregate multi-scale cross-modal representations for visual sound localization. We conduct extensive experiments on VGGSound-Instruments, VGG-Sound Sources, and AVSBench benchmarks. The results demonstrate that the proposed M2VSL can achieve state-of-the-art performance on sounding object localization and segmentation.
Read more9/4/2024

0
Aligning Sight and Sound: Advanced Sound Source Localization Through Audio-Visual Alignment
Arda Senocak, Hyeonggon Ryu, Junsik Kim, Tae-Hyun Oh, Hanspeter Pfister, Joon Son Chung
Recent studies on learning-based sound source localization have mainly focused on the localization performance perspective. However, prior work and existing benchmarks overlook a crucial aspect: cross-modal interaction, which is essential for interactive sound source localization. Cross-modal interaction is vital for understanding semantically matched or mismatched audio-visual events, such as silent objects or off-screen sounds. In this paper, we first comprehensively examine the cross-modal interaction of existing methods, benchmarks, evaluation metrics, and cross-modal understanding tasks. Then, we identify the limitations of previous studies and make several contributions to overcome the limitations. First, we introduce a new synthetic benchmark for interactive sound source localization. Second, we introduce new evaluation metrics to rigorously assess sound source localization methods, focusing on accurately evaluating both localization performance and cross-modal interaction ability. Third, we propose a learning framework with a cross-modal alignment strategy to enhance cross-modal interaction. Lastly, we evaluate both interactive sound source localization and auxiliary cross-modal retrieval tasks together to thoroughly assess cross-modal interaction capabilities and benchmark competing methods. Our new benchmarks and evaluation metrics reveal previously overlooked issues in sound source localization studies. Our proposed novel method, with enhanced cross-modal alignment, shows superior sound source localization performance. This work provides the most comprehensive analysis of sound source localization to date, with extensive validation of competing methods on both existing and new benchmarks using new and standard evaluation metrics.
Read more7/19/2024
0
Unified Video-Language Pre-training with Synchronized Audio
Shentong Mo, Haofan Wang, Huaxia Li, Xu Tang
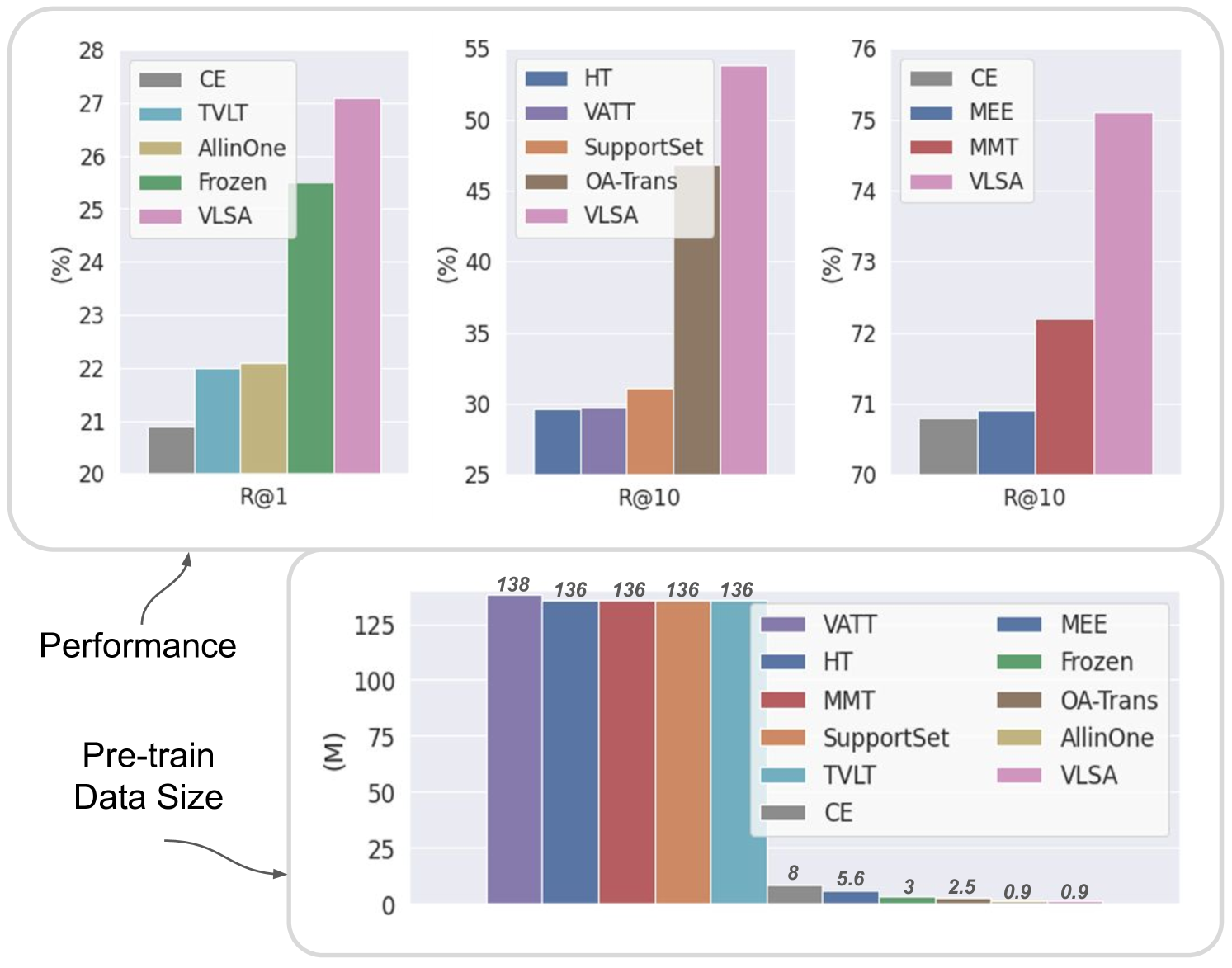
Video-language pre-training is a typical and challenging problem that aims at learning visual and textual representations from large-scale data in a self-supervised way. Existing pre-training approaches either captured the correspondence of image-text pairs or utilized temporal ordering of frames. However, they do not explicitly explore the natural synchronization between audio and the other two modalities. In this work, we propose an enhanced framework for Video-Language pre-training with Synchronized Audio, termed as VLSA, that can learn tri-modal representations in a unified self-supervised transformer. Specifically, our VLSA jointly aggregates embeddings of local patches and global tokens for video, text, and audio. Furthermore, we utilize local-patch masked modeling to learn modality-aware features, and leverage global audio matching to capture audio-guided features for video and text. We conduct extensive experiments on retrieval across text, video, and audio. Our simple model pre-trained on only 0.9M data achieves improving results against state-of-the-art baselines. In addition, qualitative visualizations vividly showcase the superiority of our VLSA in learning discriminative visual-textual representations.
Read more5/14/2024