Temporally Consistent Object Editing in Videos using Extended Attention

0
Sign in to get full access
Overview
- The provided paper presents a method for editing objects in videos while maintaining temporal consistency.
- The approach leverages an extended attention mechanism to capture long-range dependencies across video frames.
- This enables coherent and seamless object editing that preserves the temporal dynamics of the video.
Plain English Explanation
The paper introduces a new technique for editing objects in videos. Often when you edit an object in a video, the changes you make don't flow smoothly across the different frames. This can result in a jarring, inconsistent appearance. The researchers' method aims to address this by using an advanced attention mechanism to better understand the relationships between objects across video frames.
This allows the system to make edits to an object in one frame and then automatically update the surrounding frames to maintain a coherent, continuous look. For example, if you wanted to change the color of a car in a video, this approach would ensure the color change looks natural and blends seamlessly from one frame to the next.
The key idea is to use an "extended attention" module that can capture long-range dependencies between video frames. This gives the system a more holistic understanding of the scene and how objects are related over time. With this, it can make intelligent, temporally-consistent edits to individual objects without disrupting the overall flow of the video.
Technical Explanation
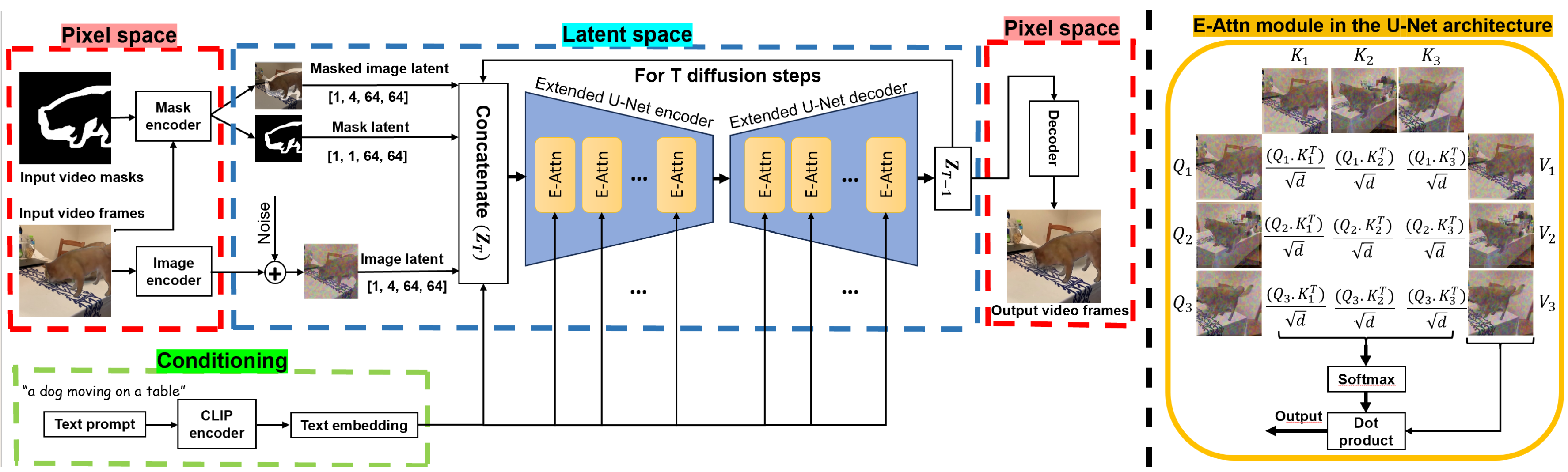
The paper presents a novel video editing framework that leverages an "extended attention" mechanism to enable temporally consistent object manipulation. The core technical innovation is the use of link text extended attention, which enhances the standard attention module to model long-range spatiotemporal dependencies across video frames.
This extended attention module is integrated into an encoder-decoder architecture, where the encoder learns a compact representation of the input video and the decoder generates the edited output. The extended attention connections allow the model to effectively propagate edits made to an object in one frame to the surrounding frames, ensuring smooth and coherent temporal dynamics.
The authors evaluate their approach on various video editing tasks, including object removal, color/texture editing, and object insertion. Experiments demonstrate that the proposed method outperforms prior techniques in terms of both visual quality and temporal consistency, as evidenced by link text user studies and quantitative metrics.
Critical Analysis
The paper presents a compelling solution for the challenge of maintaining temporal consistency when editing objects in videos. The use of extended attention to capture long-range spatiotemporal relationships is a novel and well-justified technical contribution.
However, the paper could benefit from a more thorough analysis of the limitations and potential failure cases of the proposed approach. For instance, it's unclear how the method would perform on highly dynamic or complex videos with significant camera motion or occlusions. The authors also do not discuss the computational efficiency of their approach, which could be an important consideration for real-world video editing applications.
Additionally, while the experiments demonstrate the effectiveness of the approach, it would be valuable to see comparisons to other state-of-the-art video editing techniques, such as link text or link text, to better understand the relative strengths and weaknesses of the proposed method.
Conclusion
The paper presents a novel video editing framework that leverages an extended attention mechanism to enable temporally consistent object manipulation. By capturing long-range spatiotemporal dependencies, the proposed approach can seamlessly propagate edits made to objects in individual frames, resulting in visually coherent and natural-looking video outputs.
The demonstrated results are promising and suggest that this technique could be a valuable tool for video editing workflows. Further research to address the identified limitations and explore applications in link text broader video editing scenarios would be valuable for advancing the state of the art in this important field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Temporally Consistent Object Editing in Videos using Extended Attention
AmirHossein Zamani, Amir G. Aghdam, Tiberiu Popa, Eugene Belilovsky
Image generation and editing have seen a great deal of advancements with the rise of large-scale diffusion models that allow user control of different modalities such as text, mask, depth maps, etc. However, controlled editing of videos still lags behind. Prior work in this area has focused on using 2D diffusion models to globally change the style of an existing video. On the other hand, in many practical applications, editing localized parts of the video is critical. In this work, we propose a method to edit videos using a pre-trained inpainting image diffusion model. We systematically redesign the forward path of the model by replacing the self-attention modules with an extended version of attention modules that creates frame-level dependencies. In this way, we ensure that the edited information will be consistent across all the video frames no matter what the shape and position of the masked area is. We qualitatively compare our results with state-of-the-art in terms of accuracy on several video editing tasks like object retargeting, object replacement, and object removal tasks. Simulations demonstrate the superior performance of the proposed strategy.
Read more6/4/2024

0
Blended Latent Diffusion under Attention Control for Real-World Video Editing
Deyin Liu, Lin Yuanbo Wu, Xianghua Xie
Due to lack of fully publicly available text-to-video models, current video editing methods tend to build on pre-trained text-to-image generation models, however, they still face grand challenges in dealing with the local editing of video with temporal information. First, although existing methods attempt to focus on local area editing by a pre-defined mask, the preservation of the outside-area background is non-ideal due to the spatially entire generation of each frame. In addition, specially providing a mask by user is an additional costly undertaking, so an autonomous masking strategy integrated into the editing process is desirable. Last but not least, image-level pretrained model hasn't learned temporal information across frames of a video which is vital for expressing the motion and dynamics. In this paper, we propose to adapt a image-level blended latent diffusion model to perform local video editing tasks. Specifically, we leverage DDIM inversion to acquire the latents as background latents instead of the randomly noised ones to better preserve the background information of the input video. We further introduce an autonomous mask manufacture mechanism derived from cross-attention maps in diffusion steps. Finally, we enhance the temporal consistency across video frames by transforming the self-attention blocks of U-Net into temporal-spatial blocks. Through extensive experiments, our proposed approach demonstrates effectiveness in different real-world video editing tasks.
Read more9/6/2024

0
Unified Editing of Panorama, 3D Scenes, and Videos Through Disentangled Self-Attention Injection
Gihyun Kwon, Jangho Park, Jong Chul Ye
While text-to-image models have achieved impressive capabilities in image generation and editing, their application across various modalities often necessitates training separate models. Inspired by existing method of single image editing with self attention injection and video editing with shared attention, we propose a novel unified editing framework that combines the strengths of both approaches by utilizing only a basic 2D image text-to-image (T2I) diffusion model. Specifically, we design a sampling method that facilitates editing consecutive images while maintaining semantic consistency utilizing shared self-attention features during both reference and consecutive image sampling processes. Experimental results confirm that our method enables editing across diverse modalities including 3D scenes, videos, and panorama images.
Read more5/28/2024
📶
0
Semantically Consistent Video Inpainting with Conditional Diffusion Models
Dylan Green, William Harvey, Saeid Naderiparizi, Matthew Niedoba, Yunpeng Liu, Xiaoxuan Liang, Jonathan Lavington, Ke Zhang, Vasileios Lioutas, Setareh Dabiri, Adam Scibior, Berend Zwartsenberg, Frank Wood
Current state-of-the-art methods for video inpainting typically rely on optical flow or attention-based approaches to inpaint masked regions by propagating visual information across frames. While such approaches have led to significant progress on standard benchmarks, they struggle with tasks that require the synthesis of novel content that is not present in other frames. In this paper we reframe video inpainting as a conditional generative modeling problem and present a framework for solving such problems with conditional video diffusion models. We highlight the advantages of using a generative approach for this task, showing that our method is capable of generating diverse, high-quality inpaintings and synthesizing new content that is spatially, temporally, and semantically consistent with the provided context.
Read more5/2/2024