Token-wise Influential Training Data Retrieval for Large Language Models

0
🏋️
Sign in to get full access
Overview
- Proposed a framework called RapidIn to efficiently estimate the influence of each training data on the output of a Large Language Model (LLM)
- RapidIn consists of two stages: caching and retrieval
- Caching compresses the gradient vectors by over 200,000x, allowing them to be stored efficiently
- Retrieval traverses the cached gradients to estimate the influence within minutes, achieving over 6,326x speedup
- Supports multi-GPU parallelization to accelerate caching and retrieval
Plain English Explanation
When you use a large language model (LLM) to generate text, it's not always clear which parts of the model's training data led to that specific output. The proposed RapidIn framework aims to solve this problem by efficiently estimating the influence of each training data on the LLM's generation.
RapidIn works in two stages. First, it compresses the model's gradient information by a huge amount, allowing it to be stored more efficiently. Then, when you want to know which training data influenced a particular output, RapidIn can quickly search through the cached gradients to figure that out - over 6,000 times faster than previous methods.
This speed-up is important because it allows you to better understand and debug how LLMs work, which can help personalize them or decide when to use them. By making this analysis much faster, RapidIn makes it practical to use in real-world applications of large language models.
Technical Explanation
The key innovation in RapidIn is its two-stage approach of caching and retrieval. First, the framework compresses the gradient vectors - which encode information about how the model's parameters should be updated during training - by over 200,000x. This allows the gradients to be efficiently stored on disk or in GPU/CPU memory.
Then, when analyzing a particular LLM generation, RapidIn can quickly traverse the cached gradients to estimate which training data most influenced that output. This retrieval process is over 6,326x faster than previous methods, taking just minutes instead of hours or days.
RapidIn also supports multi-GPU parallelization, which further accelerates both the caching and retrieval stages. The authors' empirical results demonstrate the efficiency and effectiveness of their framework, making it a promising tool for understanding and improving large language models.
Critical Analysis
The RapidIn paper presents an impressive technical achievement in terms of speeding up the process of attributing LLM outputs to specific training data. However, the authors acknowledge that their approach has some limitations.
For example, RapidIn's gradient caching relies on certain assumptions about the LLM's training procedure, and may not work as well for models with different optimization methods. Additionally, the framework currently only supports single-generation analysis, whereas real-world applications may require understanding the influence of training data across multiple generations.
It would also be valuable to see the framework tested on a broader range of LLM architectures and tasks, beyond just the language modeling experiments described in the paper. Expanding the scope of the evaluation could uncover additional challenges or edge cases that need to be addressed.
Overall, RapidIn represents an important step forward in making large language model interpretability more practical and scalable. But there is still room for further research and development to unlock the full potential of this approach.
Conclusion
The RapidIn framework proposed in this paper offers a highly efficient way to estimate the influence of training data on the outputs of large language models. By compressing gradient information and enabling fast retrieval, RapidIn can perform this analysis orders of magnitude faster than previous methods.
This capability has significant implications for the responsible development and use of LLMs. Being able to quickly understand how a model's training data affects its generation can help researchers and practitioners personalize LLMs, utilize them appropriately, and synthesize new training data - all of which are crucial for making large language models more reliable and beneficial. The RapidIn framework represents an important step towards realizing this vision.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏋️
0
Token-wise Influential Training Data Retrieval for Large Language Models
Huawei Lin, Jikai Long, Zhaozhuo Xu, Weijie Zhao
Given a Large Language Model (LLM) generation, how can we identify which training data led to this generation? In this paper, we proposed RapidIn, a scalable framework adapting to LLMs for estimating the influence of each training data. The proposed framework consists of two stages: caching and retrieval. First, we compress the gradient vectors by over 200,000x, allowing them to be cached on disk or in GPU/CPU memory. Then, given a generation, RapidIn efficiently traverses the cached gradients to estimate the influence within minutes, achieving over a 6,326x speedup. Moreover, RapidIn supports multi-GPU parallelization to substantially accelerate caching and retrieval. Our empirical result confirms the efficiency and effectiveness of RapidIn.
Read more5/21/2024
0
Unsupervised Information Refinement Training of Large Language Models for Retrieval-Augmented Generation
Shicheng Xu, Liang Pang, Mo Yu, Fandong Meng, Huawei Shen, Xueqi Cheng, Jie Zhou
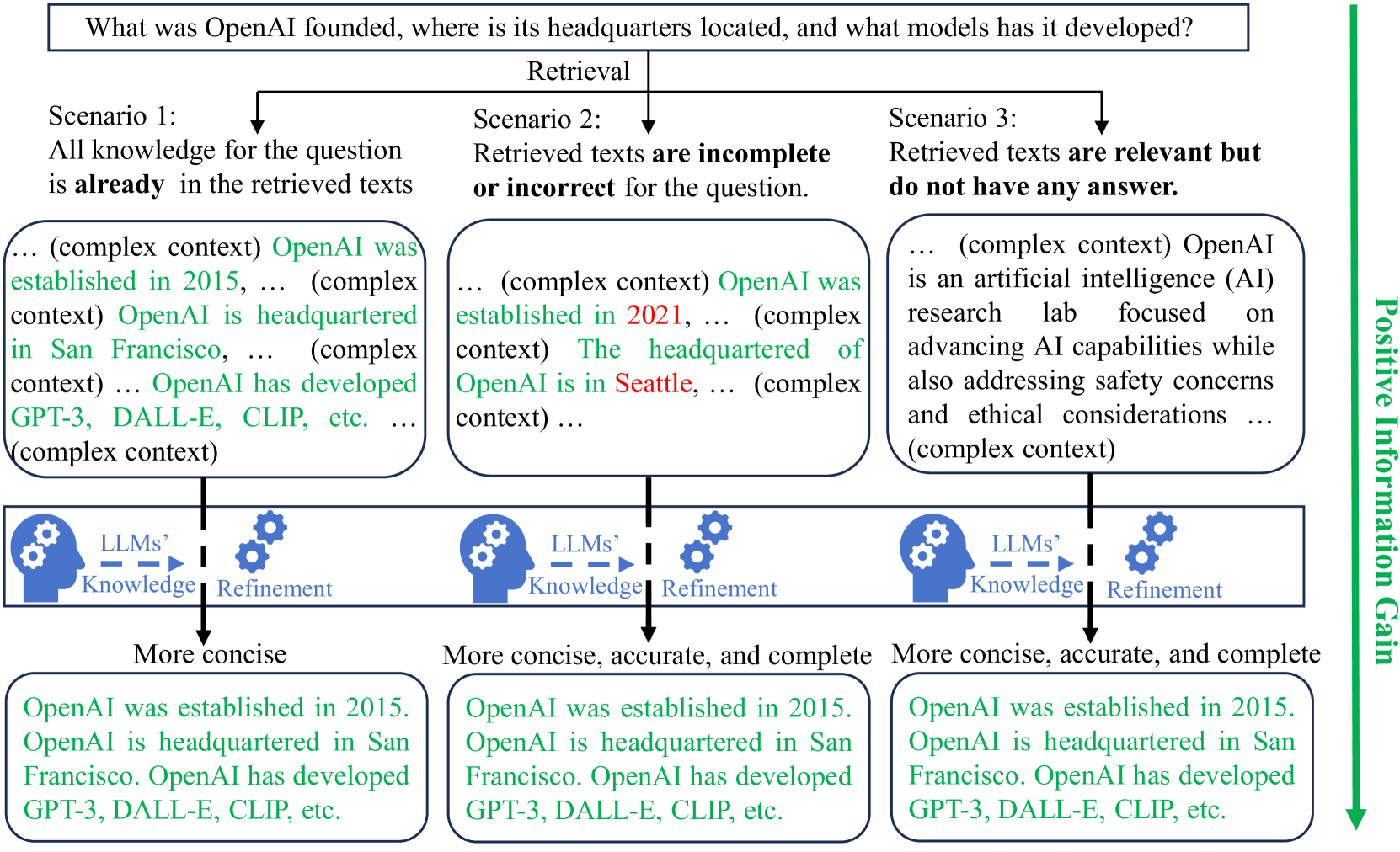
Retrieval-augmented generation (RAG) enhances large language models (LLMs) by incorporating additional information from retrieval. However, studies have shown that LLMs still face challenges in effectively using the retrieved information, even ignoring it or being misled by it. The key reason is that the training of LLMs does not clearly make LLMs learn how to utilize input retrieved texts with varied quality. In this paper, we propose a novel perspective that considers the role of LLMs in RAG as ``Information Refiner'', which means that regardless of correctness, completeness, or usefulness of retrieved texts, LLMs can consistently integrate knowledge within the retrieved texts and model parameters to generate the texts that are more concise, accurate, and complete than the retrieved texts. To this end, we propose an information refinement training method named InFO-RAG that optimizes LLMs for RAG in an unsupervised manner. InFO-RAG is low-cost and general across various tasks. Extensive experiments on zero-shot prediction of 11 datasets in diverse tasks including Question Answering, Slot-Filling, Language Modeling, Dialogue, and Code Generation show that InFO-RAG improves the performance of LLaMA2 by an average of 9.39% relative points. InFO-RAG also shows advantages in in-context learning and robustness of RAG.
Read more6/13/2024

0
In2Core: Leveraging Influence Functions for Coreset Selection in Instruction Finetuning of Large Language Models
Ayrton San Joaquin, Bin Wang, Zhengyuan Liu, Nicholas Asher, Brian Lim, Philippe Muller, Nancy Chen
Despite advancements, fine-tuning Large Language Models (LLMs) remains costly due to the extensive parameter count and substantial data requirements for model generalization. Accessibility to computing resources remains a barrier for the open-source community. To address this challenge, we propose the In2Core algorithm, which selects a coreset by analyzing the correlation between training and evaluation samples with a trained model. Notably, we assess the model's internal gradients to estimate this relationship, aiming to rank the contribution of each training point. To enhance efficiency, we propose an optimization to compute influence functions with a reduced number of layers while achieving similar accuracy. By applying our algorithm to instruction fine-tuning data of LLMs, we can achieve similar performance with just 50% of the training data. Meantime, using influence functions to analyze model coverage to certain testing samples could provide a reliable and interpretable signal on the training set's coverage of those test points.
Read more8/9/2024

0
Fast Training Dataset Attribution via In-Context Learning
Milad Fotouhi, Mohammad Taha Bahadori, Oluwaseyi Feyisetan, Payman Arabshahi, David Heckerman
We investigate the use of in-context learning and prompt engineering to estimate the contributions of training data in the outputs of instruction-tuned large language models (LLMs). We propose two novel approaches: (1) a similarity-based approach that measures the difference between LLM outputs with and without provided context, and (2) a mixture distribution model approach that frames the problem of identifying contribution scores as a matrix factorization task. Our empirical comparison demonstrates that the mixture model approach is more robust to retrieval noise in in-context learning, providing a more reliable estimation of data contributions.
Read more8/23/2024