Towards auditory attention decoding with noise-tagging: A pilot study

0

Sign in to get full access
Overview
- Presents a method for visualizing different levels of audio modulation using noise-tagging
- Demonstrates the effects of 0%, 50%, and 100% modulation on audio signals
- Provides a way to compare the modulated audio to the original unmodulated version
Plain English Explanation
This paper introduces a technique for visualizing how different levels of audio modulation affect the sound. Audio modulation is a process where an audio signal is multiplied by a noise-code, which can reduce or alter the volume of the audio.
The researchers show examples of audio that has been modulated by 0% (unmodulated), 50%, and 100%. The 0% modulation leaves the audio unchanged, while the 50% modulation reduces the volume to half at certain points, and the 100% modulation completely removes the audio at certain points. This is visualized by overlaying the modulated audio (in different colors) on top of the original unmodulated audio (in light gray).
The noise-code used for the modulation is also displayed in black, which helps explain how the modulation is being applied. This technique could be useful for understanding how different levels of auditory attention or audio processing can affect the final audio output.
Technical Explanation
The paper presents a method for visualizing the effects of different modulation depths on audio signals using noise-tagging. Amplitude modulation is applied to the audio by multiplying it with a noise-code.
For 0% modulation, the noise-code is always 1, so the audio remains unmodulated. For 50% modulation, the noise-code ranges between 0.5 and 1, reducing the amplitude by up to 50% at certain points. For 100% modulation, the noise-code ranges from 0 to 1, completely removing the audio at points where the code is 0.
The modulated audio is overlaid on the original unmodulated audio (in light gray) to allow for easy comparison. The noise-code used for modulation is also displayed in black. This visualization technique could be useful for understanding the effects of audio-visual target speaker extraction or open-vocabulary auditory neural decoding.
Critical Analysis
The paper provides a clear and straightforward method for visualizing the effects of different audio modulation depths. The use of noise-tagging and overlaying the modulated audio on the original signal makes it easy to understand how the modulation is being applied.
However, the paper does not discuss any potential limitations or caveats of this visualization technique. For example, it would be interesting to see how the method performs with more complex audio signals, such as speech or music, rather than just simple tones.
Additionally, the paper does not explore the potential applications of this visualization beyond the specific examples provided. It would be helpful to see how this technique could be used to analyze or understand other audio processing or auditory attention mechanisms.
Conclusion
This paper introduces a simple yet effective method for visualizing the effects of different audio modulation depths using noise-tagging. The technique could be useful for understanding how various audio processing or auditory attention mechanisms can impact the final audio output. While the paper provides a clear demonstration of the method, further research is needed to explore its potential applications and limitations in more depth.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Towards auditory attention decoding with noise-tagging: A pilot study
H. A. Scheppink, S. Ahmadi, P. Desain, M. Tangermann, J. Thielen
Auditory attention decoding (AAD) aims to extract from brain activity the attended speaker amidst candidate speakers, offering promising applications for neuro-steered hearing devices and brain-computer interfacing. This pilot study makes a first step towards AAD using the noise-tagging stimulus protocol, which evokes reliable code-modulated evoked potentials, but is minimally explored in the auditory modality. Participants were sequentially presented with two Dutch speech stimuli that were amplitude-modulated with a unique binary pseudo-random noise-code, effectively tagging these with additional decodable information. We compared the decoding of unmodulated audio against audio modulated with various modulation depths, and a conventional AAD method against a standard method to decode noise-codes. Our pilot study revealed higher performances for the conventional method with 70 to 100 percent modulation depths compared to unmodulated audio. The noise-code decoder did not further improve these results. These fundamental insights highlight the potential of integrating noise-codes in speech to enhance auditory speaker detection when multiple speakers are presented simultaneously.
Read more5/20/2024

0
Using Ear-EEG to Decode Auditory Attention in Multiple-speaker Environment
Haolin Zhu, Yujie Yan, Xiran Xu, Zhongshu Ge, Pei Tian, Xihong Wu, Jing Chen
Auditory Attention Decoding (AAD) can help to determine the identity of the attended speaker during an auditory selective attention task, by analyzing and processing measurements of electroencephalography (EEG) data. Most studies on AAD are based on scalp-EEG signals in two-speaker scenarios, which are far from real application. Ear-EEG has recently gained significant attention due to its motion tolerance and invisibility during data acquisition, making it easy to incorporate with other devices for applications. In this work, participants selectively attended to one of the four spatially separated speakers' speech in an anechoic room. The EEG data were concurrently collected from a scalp-EEG system and an ear-EEG system (cEEGrids). Temporal response functions (TRFs) and stimulus reconstruction (SR) were utilized using ear-EEG data. Results showed that the attended speech TRFs were stronger than each unattended speech and decoding accuracy was 41.3% in the 60s (chance level of 25%). To further investigate the impact of electrode placement and quantity, SR was utilized in both scalp-EEG and ear-EEG, revealing that while the number of electrodes had a minor effect, their positioning had a significant influence on the decoding accuracy. One kind of auditory spatial attention detection (ASAD) method, STAnet, was testified with this ear-EEG database, resulting in 93.1% in 1-second decoding window. The implementation code and database for our work are available on GitHub: https://github.com/zhl486/Ear_EEG_code.git and Zenodo: https://zenodo.org/records/10803261.
Read more9/16/2024

0
Enhancing spatial auditory attention decoding with neuroscience-inspired prototype training
Zelin Qiu, Jianjun Gu, Dingding Yao, Junfeng Li
The spatial auditory attention decoding (Sp-AAD) technology aims to determine the direction of auditory attention in multi-talker scenarios via neural recordings. Despite the success of recent Sp-AAD algorithms, their performance is hindered by trial-specific features in EEG data. This study aims to improve decoding performance against these features. Studies in neuroscience indicate that spatial auditory attention can be reflected in the topological distribution of EEG energy across different frequency bands. This insight motivates us to propose Prototype Training, a neuroscience-inspired method for Sp-AAD. This method constructs prototypes with enhanced energy distribution representations and reduced trial-specific characteristics, enabling the model to better capture auditory attention features. To implement prototype training, an EEGWaveNet that employs the wavelet transform of EEG is further proposed. Detailed experiments indicate that the EEGWaveNet with prototype training outperforms other competitive models on various datasets, and the effectiveness of the proposed method is also validated. As a training method independent of model architecture, prototype training offers new insights into the field of Sp-AAD.
Read more7/10/2024
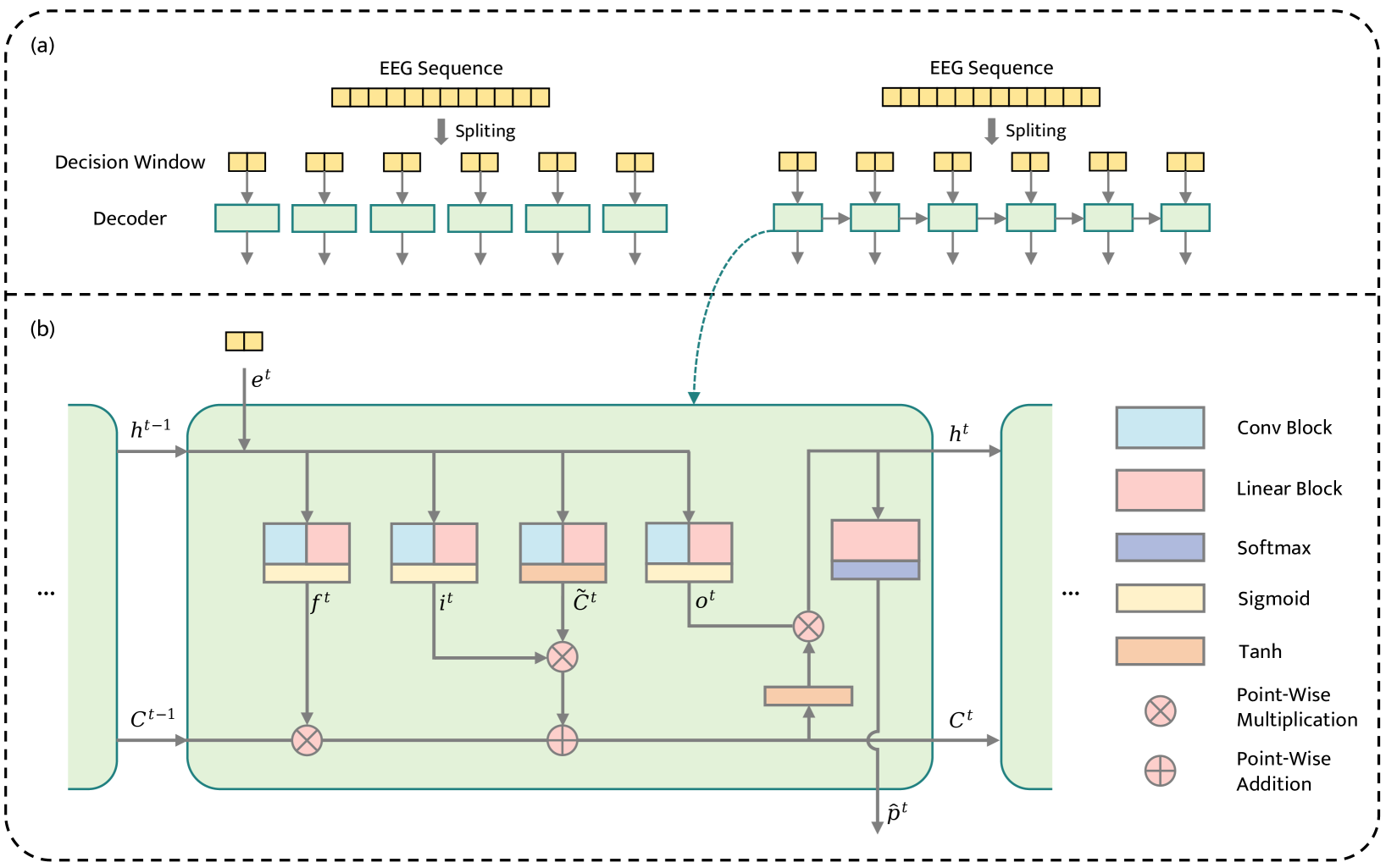
0
StreamAAD: Decoding Spatial Auditory Attention with a Streaming Architecture
Zelin Qiu, Dingding Yao, Junfeng Li
In this paper, we present our approach for the Track 1 of the Chinese Auditory Attention Decoding (Chinese AAD) Challenge at ISCSLP 2024. Most existing spatial auditory attention decoding (Sp-AAD) methods employ an isolated window architecture, focusing solely on global invariant features without considering relationships between different decision windows, which can lead to suboptimal performance. To address this issue, we propose a novel streaming decoding architecture, termed StreamAAD. In StreamAAD, decision windows are input to the network as a sequential stream and decoded in order, allowing for the modeling of inter-window relationships. Additionally, we employ a model ensemble strategy, achieving significant better performance than the baseline, ranking First in the challenge.
Read more8/27/2024