ZONE: Zero-Shot Instruction-Guided Local Editing

0
Sign in to get full access
Overview
• This paper introduces ZONE, a zero-shot instruction-guided local image editing system that allows users to modify specific regions of an image by providing natural language instructions.
• ZONE leverages diffusion models and cross-attention mechanisms to enable users to edit images in a targeted and controllable manner without requiring any fine-tuning or specialized training data.
• The system demonstrates impressive results on a variety of editing tasks, including changing object attributes, removing or adding elements, and performing color and texture manipulations.
Plain English Explanation
ZONE is a new AI-powered tool that lets you edit specific parts of an image by simply telling it what you want to change, using everyday language. For example, you could say "Make the woman's dress blue" or "Remove the chair from the corner of the room," and the system would make those targeted edits without you needing any special training or expertise.
This is possible because ZONE uses advanced machine learning models, called diffusion models and cross-attention mechanisms, that can understand natural language instructions and then make the requested changes to the appropriate regions of the image. This zero-shot capability means the system doesn't require any fine-tuning or specialized training data - it can just start editing images right away based on the instructions you provide.
The researchers have tested ZONE on a variety of editing tasks, and it's shown impressive results, allowing users to modify object attributes, remove or add elements, and even change the color and texture of specific parts of an image. This makes ZONE a powerful and flexible tool for anyone who wants to edit their photos or digital artwork in a more intuitive and targeted way.
Technical Explanation
The core of ZONE is a diffusion model, a type of generative AI system, that has been trained on a large dataset of images. This diffusion model has the ability to understand natural language instructions and then generate new image content that matches those instructions.
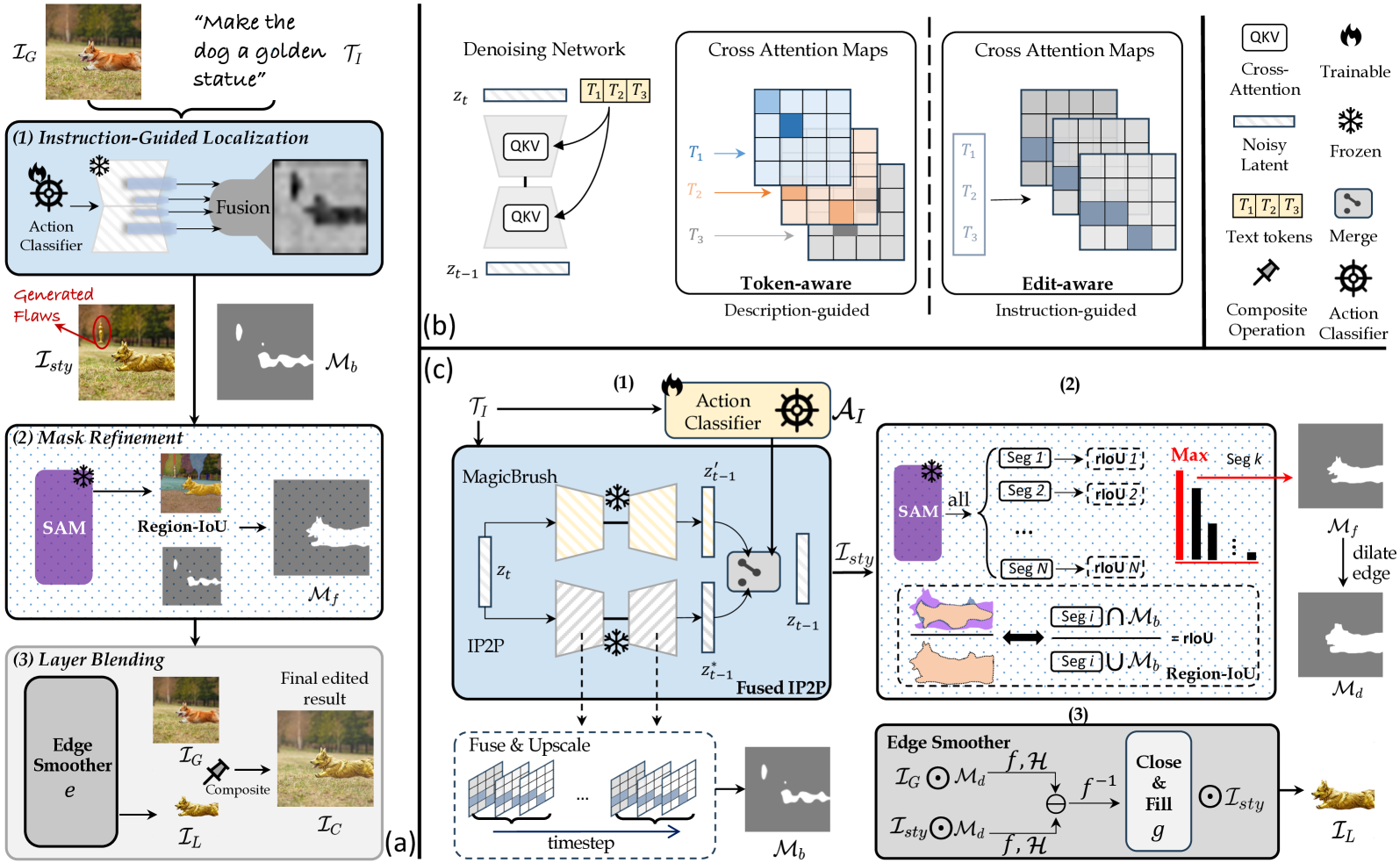
To enable targeted local edits, the researchers introduce a cross-attention mechanism that allows the diffusion model to focus on specific regions of the input image when generating new content. This cross-attention module takes the language instruction as input, along with the current state of the image, and then selectively attends to the relevant spatial locations to make the requested changes.
[This approach builds on prior work in text-driven image editing, zero-shot video editing, and zero-shot cross-attention, but extends these ideas to enable truly zero-shot local image editing without any specialized training or fine-tuning.]
In experiments, the researchers demonstrate ZONE's ability to handle a wide range of editing tasks, from changing object attributes to removing and adding elements to modifying color and texture. The system is evaluated on both synthetic and real-world image datasets, showcasing its versatility and robustness.
Critical Analysis
The researchers acknowledge several limitations of ZONE, including its reliance on the quality and coverage of the training data, as well as potential biases and safety concerns associated with large language models. They also note that the system's performance may degrade for highly complex or ambiguous editing instructions.
Furthermore, while ZONE demonstrates impressive zero-shot capabilities, it's unclear how it would scale to support an unlimited set of editing instructions or handle highly specific or technical language. Additional research may be needed to address these challenges and further improve the system's flexibility and robustness.
That said, the core ideas behind ZONE, such as the use of cross-attention mechanisms and diffusion models for targeted image generation, are likely to have broader applications in the field of zero-shot referring expression comprehension and zero-shot medical image editing. As the research in these areas continues to evolve, ZONE may serve as a valuable foundation for developing even more powerful and user-friendly image editing tools.
Conclusion
The ZONE system represents a significant advancement in the field of zero-shot, instruction-guided image editing. By leveraging diffusion models and cross-attention mechanisms, the researchers have created a highly flexible and powerful tool that allows users to make targeted changes to images simply by providing natural language instructions.
The system's impressive performance on a wide range of editing tasks, from modifying object attributes to changing color and texture, suggests that ZONE could have a transformative impact on the way people interact with and manipulate digital images. As the underlying technologies continue to improve, we may see even more sophisticated and intuitive image editing tools emerge, empowering users of all skill levels to bring their creative visions to life.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
ZONE: Zero-Shot Instruction-Guided Local Editing
Shanglin Li, Bohan Zeng, Yutang Feng, Sicheng Gao, Xuhui Liu, Jiaming Liu, Li Lin, Xu Tang, Yao Hu, Jianzhuang Liu, Baochang Zhang
Recent advances in vision-language models like Stable Diffusion have shown remarkable power in creative image synthesis and editing.However, most existing text-to-image editing methods encounter two obstacles: First, the text prompt needs to be carefully crafted to achieve good results, which is not intuitive or user-friendly. Second, they are insensitive to local edits and can irreversibly affect non-edited regions, leaving obvious editing traces. To tackle these problems, we propose a Zero-shot instructiON-guided local image Editing approach, termed ZONE. We first convert the editing intent from the user-provided instruction (e.g., make his tie blue) into specific image editing regions through InstructPix2Pix. We then propose a Region-IoU scheme for precise image layer extraction from an off-the-shelf segment model. We further develop an edge smoother based on FFT for seamless blending between the layer and the image.Our method allows for arbitrary manipulation of a specific region with a single instruction while preserving the rest. Extensive experiments demonstrate that our ZONE achieves remarkable local editing results and user-friendliness, outperforming state-of-the-art methods. Code is available at https://github.com/lsl001006/ZONE.
Read more4/15/2024
🖼️
0
Text-Driven Image Editing via Learnable Regions
Yuanze Lin, Yi-Wen Chen, Yi-Hsuan Tsai, Lu Jiang, Ming-Hsuan Yang
Language has emerged as a natural interface for image editing. In this paper, we introduce a method for region-based image editing driven by textual prompts, without the need for user-provided masks or sketches. Specifically, our approach leverages an existing pre-trained text-to-image model and introduces a bounding box generator to identify the editing regions that are aligned with the textual prompts. We show that this simple approach enables flexible editing that is compatible with current image generation models, and is able to handle complex prompts featuring multiple objects, complex sentences, or lengthy paragraphs. We conduct an extensive user study to compare our method against state-of-the-art methods. The experiments demonstrate the competitive performance of our method in manipulating images with high fidelity and realism that correspond to the provided language descriptions. Our project webpage can be found at: https://yuanze-lin.me/LearnableRegions_page.
Read more4/4/2024

0
InstructGIE: Towards Generalizable Image Editing
Zichong Meng, Changdi Yang, Jun Liu, Hao Tang, Pu Zhao, Yanzhi Wang
Recent advances in image editing have been driven by the development of denoising diffusion models, marking a significant leap forward in this field. Despite these advances, the generalization capabilities of recent image editing approaches remain constrained. In response to this challenge, our study introduces a novel image editing framework with enhanced generalization robustness by boosting in-context learning capability and unifying language instruction. This framework incorporates a module specifically optimized for image editing tasks, leveraging the VMamba Block and an editing-shift matching strategy to augment in-context learning. Furthermore, we unveil a selective area-matching technique specifically engineered to address and rectify corrupted details in generated images, such as human facial features, to further improve the quality. Another key innovation of our approach is the integration of a language unification technique, which aligns language embeddings with editing semantics to elevate the quality of image editing. Moreover, we compile the first dataset for image editing with visual prompts and editing instructions that could be used to enhance in-context capability. Trained on this dataset, our methodology not only achieves superior synthesis quality for trained tasks, but also demonstrates robust generalization capability across unseen vision tasks through tailored prompts.
Read more7/23/2024

0
VidEdit: Zero-Shot and Spatially Aware Text-Driven Video Editing
Paul Couairon, Cl'ement Rambour, Jean-Emmanuel Haugeard, Nicolas Thome
Recently, diffusion-based generative models have achieved remarkable success for image generation and edition. However, existing diffusion-based video editing approaches lack the ability to offer precise control over generated content that maintains temporal consistency in long-term videos. On the other hand, atlas-based methods provide strong temporal consistency but are costly to edit a video and lack spatial control. In this work, we introduce VidEdit, a novel method for zero-shot text-based video editing that guarantees robust temporal and spatial consistency. In particular, we combine an atlas-based video representation with a pre-trained text-to-image diffusion model to provide a training-free and efficient video editing method, which by design fulfills temporal smoothness. To grant precise user control over generated content, we utilize conditional information extracted from off-the-shelf panoptic segmenters and edge detectors which guides the diffusion sampling process. This method ensures a fine spatial control on targeted regions while strictly preserving the structure of the original video. Our quantitative and qualitative experiments show that VidEdit outperforms state-of-the-art methods on DAVIS dataset, regarding semantic faithfulness, image preservation, and temporal consistency metrics. With this framework, processing a single video only takes approximately one minute, and it can generate multiple compatible edits based on a unique text prompt. Project web-page at https://videdit.github.io
Read more4/3/2024