owlvit-base-patch32
Maintainer: alaradirik

14

| Property | Value |
|---|---|
| Run this model | Run on Replicate |
| API spec | View on Replicate |
| Github link | View on Github |
| Paper link | View on Arxiv |
Create account to get full access
Model overview
The owlvit-base-patch32 model is a zero-shot/open vocabulary object detection model developed by alaradirik. It shares similarities with other AI models like text-extract-ocr, which is a simple OCR model for extracting text from images, and codet, which detects objects in images. However, the owlvit-base-patch32 model goes beyond basic object detection, enabling zero-shot detection of objects based on natural language queries.
Model inputs and outputs
The owlvit-base-patch32 model takes three inputs: an image, a comma-separated list of object names to detect, and a confidence threshold. It outputs the detected objects with bounding boxes and confidence scores.
Inputs
- image: The input image to query
- query: Comma-separated names of the objects to be detected in the image
- threshold: Confidence level for object detection (between 0 and 1)
- show_visualisation: Whether to draw and visualize bounding boxes on the image
Outputs
- The detected objects with bounding boxes and confidence scores
Capabilities
The owlvit-base-patch32 model is capable of zero-shot object detection, meaning it can identify objects in an image based on natural language descriptions, without being explicitly trained on those objects. This makes it a powerful tool for open-vocabulary object detection, where you can query the model for a wide range of objects beyond its training set.
What can I use it for?
The owlvit-base-patch32 model can be used in a variety of applications that require object detection, such as image analysis, content moderation, and robotic vision. For example, you could use it to build a visual search engine that allows users to find images based on natural language queries, or to develop a system for automatically tagging objects in photos.
Things to try
One interesting aspect of the owlvit-base-patch32 model is its ability to detect objects in context. For example, you could try querying the model for "dog" and see if it correctly identifies dogs in the image, even if they are surrounded by other objects. Additionally, you could experiment with using more complex queries, such as "small red car" or "person playing soccer", to see how the model handles more specific or compositional object descriptions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Models
owlvit-base-patch32
17
The owlvit-base-patch32 is a zero-shot text-conditioned object detection model developed by Replicate. It uses a CLIP backbone with a ViT-B/32 Transformer architecture as an image encoder and a masked self-attention Transformer as a text encoder. The model is trained to maximize the similarity of image and text pairs via a contrastive loss, and the CLIP backbone is fine-tuned together with the box and class prediction heads with an object detection objective. This allows the model to perform zero-shot text-conditioned object detection, where one or multiple text queries can be used to detect objects in an image. Similar models include owlvit-base-patch32 by Google, which also uses a CLIP backbone for zero-shot object detection, as well as Stable Diffusion and Zero-Shot Image to Text, which explore related capabilities in text-to-image generation and image-to-text generation, respectively. Model inputs and outputs Inputs image**: The input image to query query**: Comma-separated names of the objects to be detected in the image threshold**: Confidence level for object detection (default is 0.1) show_visualisation**: Whether to draw and visualize bounding boxes on the image (default is true) Outputs The model outputs bounding boxes, scores, and labels for the detected objects in the input image based on the provided text query. Capabilities The owlvit-base-patch32 model can perform zero-shot object detection, where it can detect objects in an image based on text queries, even if those object classes were not seen during training. This allows for open-vocabulary object detection, where the model can identify a wide range of objects without being limited to a fixed set of classes. What can I use it for? The owlvit-base-patch32 model can be useful for a variety of applications that require identifying objects in images, such as visual search, image captioning, and image understanding. It could be particularly useful in domains where the set of objects to be detected may not be known in advance, or where the labeling of training data is costly or impractical. Things to try One interesting thing to try with the owlvit-base-patch32 model is to experiment with different text queries to see how the model performs on a variety of object detection tasks. You could try querying for specific objects, combinations of objects, or even more abstract concepts to see the model's capabilities and limitations. Additionally, you could explore how the model's performance is affected by the confidence threshold or the decision to show the visualization.
Updated Invalid Date
🐍
owlvit-base-patch32
95
The owlvit-base-patch32 model is a zero-shot text-conditioned object detection model developed by researchers at Google. It uses CLIP as its multi-modal backbone, with a Vision Transformer (ViT) architecture as the image encoder and a causal language model as the text encoder. The model is trained to maximize the similarity between images and their corresponding text descriptions, enabling open-vocabulary classification. This allows the model to be queried with one or multiple text queries to detect objects in an image, without the need for predefined object classes. Similar models like the CLIP and Vision Transformer also use a ViT architecture and contrastive learning to enable zero-shot and open-ended image understanding tasks. However, the owlvit-base-patch32 model is specifically designed for object detection, with a lightweight classification and bounding box prediction head added to the ViT backbone. Model inputs and outputs Inputs Text**: One or more text queries to use for detecting objects in the input image. Image**: The input image to perform object detection on. Outputs Bounding boxes**: Predicted bounding boxes around detected objects. Class logits**: Predicted class logits for the detected objects, based on the provided text queries. Capabilities The owlvit-base-patch32 model can be used for zero-shot, open-vocabulary object detection. Given an image and one or more text queries, the model can localize and identify the relevant objects without any predefined object classes. This enables flexible and extensible object detection, where the model can be queried with novel object descriptions and adapt to new domains. What can I use it for? The owlvit-base-patch32 model can be used for a variety of computer vision applications that require open-ended object detection, such as: Intelligent image search**: Users can search for images containing specific objects or scenes by providing text queries, without the need for a predefined taxonomy. Robotic perception**: Robots can use the model to detect and identify objects in their environment based on natural language descriptions, enabling more flexible and adaptive task execution. Assistive technology**: The model can be used to help visually impaired users by detecting and describing the contents of images based on their queries. Things to try One interesting aspect of the owlvit-base-patch32 model is its ability to detect multiple objects in a single image based on multiple text queries. This can be useful for tasks like scene understanding, where the model can identify all the relevant entities and their relationships in a complex visual scene. You could try experimenting with different combinations of text queries to see how the model's detection and localization capabilities adapt. Additionally, since the model is trained in a zero-shot manner, it may be interesting to explore its performance on novel object classes or in unfamiliar domains. You could try querying the model with descriptions of objects or scenes that are outside the typical training distribution and see how it generalizes.
Updated Invalid Date
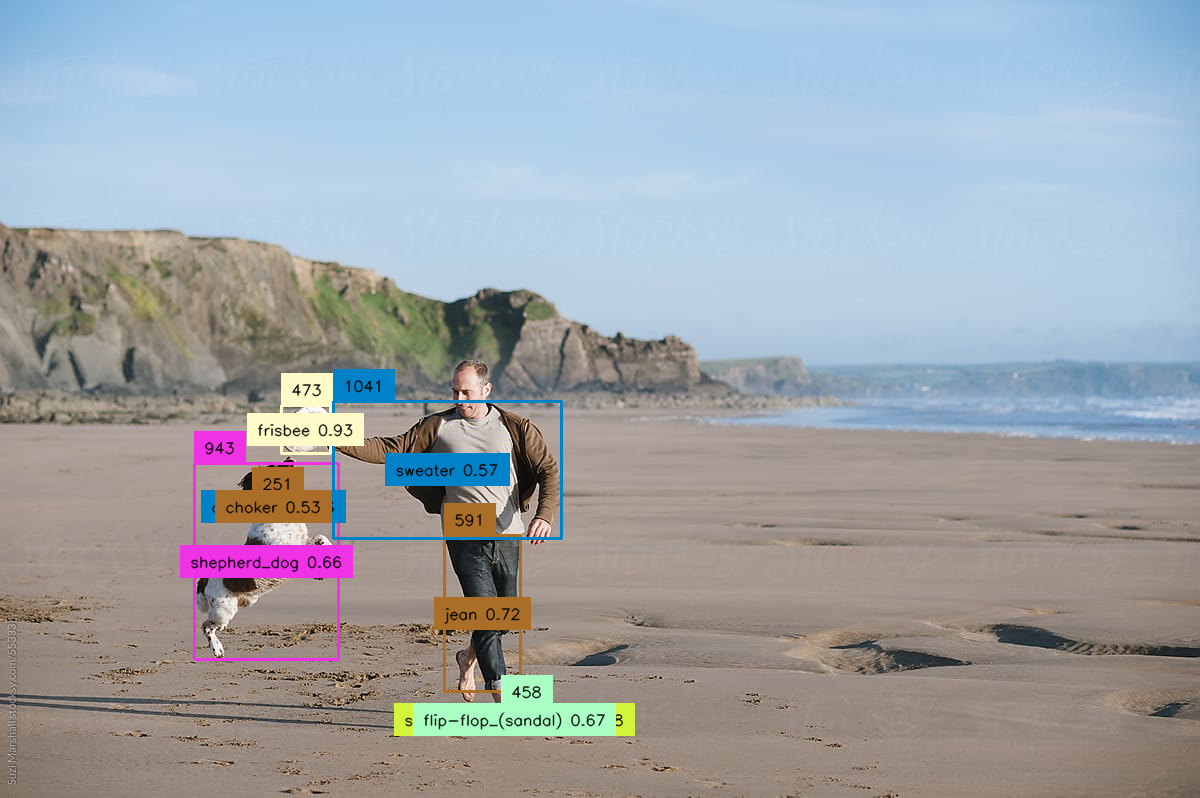
codet
1
The codet model is an object detection AI model developed by Replicate and maintained by the creator adirik. It is designed to detect objects in images with high accuracy. The codet model shares similarities with other object detection models like Marigold, which focuses on monocular depth estimation, and StyleMC, MaSaCtrl-Anything-v4-0, and MaSaCtrl-Stable-Diffusion-v1-4, which are focused on text-guided image generation and editing. Model inputs and outputs The codet model takes an input image and a confidence threshold, and outputs an array of image URIs. The input image is used for object detection, and the confidence threshold is used to filter the detected objects based on their confidence scores. Inputs Image**: The input image to be processed for object detection. Confidence**: The confidence threshold to filter the detected objects. Show Visualisation**: An optional flag to display the detection results on the input image. Outputs Array of Image URIs**: The output of the model is an array of image URIs, where each URI represents a detected object in the input image. Capabilities The codet model is capable of detecting objects in images with high accuracy. It uses a novel approach called "Co-Occurrence Guided Region-Word Alignment" to improve the model's performance on open-vocabulary object detection tasks. What can I use it for? The codet model can be useful in a variety of applications, such as: Image analysis and understanding**: The model can be used to analyze and understand the contents of images, which can be valuable in fields like e-commerce, security, and robotics. Visual search and retrieval**: The model can be used to build visual search engines or image retrieval systems, where users can search for specific objects within a large collection of images. Augmented reality and computer vision**: The model can be integrated into AR/VR applications or computer vision systems to provide real-time object detection and identification. Things to try Some ideas for things to try with the codet model include: Experiment with different confidence thresholds to see how it affects the accuracy and number of detected objects. Use the model to analyze a variety of images and see how it performs on different types of objects. Integrate the model into a larger system, such as an image-processing pipeline or a computer vision application.
Updated Invalid Date

llava-13b
16.7K
llava-13b is a large language and vision model developed by Replicate user yorickvp. The model aims to achieve GPT-4 level capabilities through visual instruction tuning, building on top of large language and vision models. It can be compared to similar multimodal models like meta-llama-3-8b-instruct from Meta, which is a fine-tuned 8 billion parameter language model for chat completions, or cinematic-redmond from fofr, a cinematic model fine-tuned on SDXL. Model inputs and outputs llava-13b takes in a text prompt and an optional image, and generates text outputs. The model is able to perform a variety of language and vision tasks, including image captioning, visual question answering, and multimodal instruction following. Inputs Prompt**: The text prompt to guide the model's language generation. Image**: An optional input image that the model can leverage to generate more informative and contextual responses. Outputs Text**: The model's generated text output, which can range from short responses to longer passages. Capabilities The llava-13b model aims to achieve GPT-4 level capabilities by leveraging visual instruction tuning techniques. This allows the model to excel at tasks that require both language and vision understanding, such as answering questions about images, following multimodal instructions, and generating captions and descriptions for visual content. What can I use it for? llava-13b can be used for a variety of applications that require both language and vision understanding, such as: Image Captioning**: Generate detailed descriptions of images to aid in accessibility or content organization. Visual Question Answering**: Answer questions about the contents and context of images. Multimodal Instruction Following**: Follow instructions that combine text and visual information, such as assembling furniture or following a recipe. Things to try Some interesting things to try with llava-13b include: Experimenting with different prompts and image inputs to see how the model responds and adapts. Pushing the model's capabilities by asking it to perform more complex multimodal tasks, such as generating a step-by-step guide for a DIY project based on a set of images. Comparing the model's performance to similar multimodal models like meta-llama-3-8b-instruct to understand its strengths and weaknesses.
Updated Invalid Date