voicecraft
Maintainer: cjwbw

8
| Property | Value |
|---|---|
| Run this model | Run on Replicate |
| API spec | View on Replicate |
| Github link | View on Github |
| Paper link | View on Arxiv |
Create account to get full access
Model overview
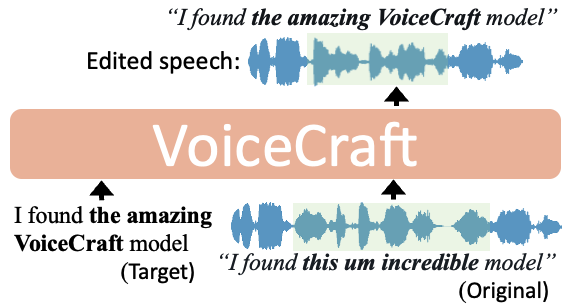
VoiceCraft is a token infilling neural codec language model developed by the maintainer cjwbw. It achieves state-of-the-art performance on both speech editing and zero-shot text-to-speech (TTS) on in-the-wild data including audiobooks, internet videos, and podcasts. Unlike similar voice cloning models like instant-id which require high-quality reference audio, VoiceCraft can clone an unseen voice with just a few seconds of reference.
Model inputs and outputs
VoiceCraft is a versatile model that can be used for both speech editing and zero-shot text-to-speech. For speech editing, the model takes in the original audio, the transcript, and target edits to the transcript. For zero-shot TTS, the model only requires a few seconds of reference audio and the target transcript.
Inputs
- Original audio: The audio file to be edited or used as a reference for TTS
- Original transcript: The transcript of the original audio, can be automatically generated using a model like WhisperX
- Target transcript: The desired transcript for the edited or synthesized audio
- Reference audio duration: The duration of the original audio to use as a reference for zero-shot TTS
Outputs
- Edited audio: The audio with the specified edits applied
- Synthesized audio: The audio generated from the target transcript using the reference audio
Capabilities
VoiceCraft is capable of high-quality speech editing and zero-shot text-to-speech. It can seamlessly blend new content into existing audio, enabling tasks like adding or removing words, changing the speaker's voice, or modifying emotional tone. For zero-shot TTS, VoiceCraft can generate natural-sounding speech in the voice of the reference audio, without any fine-tuning or additional training.
What can I use it for?
VoiceCraft can be used in a variety of applications, such as podcast production, audiobook creation, video dubbing, and voice assistant development. With its ability to edit and synthesize speech, creators can efficiently produce high-quality audio content without the need for extensive post-production work or specialized recording equipment. Additionally, VoiceCraft can be used to create personalized text-to-speech applications, where users can have their content read aloud in a voice of their choice.
Things to try
One interesting thing to try with VoiceCraft is to use it for speech-to-speech translation. By providing the model with an audio clip in one language and the transcript in the target language, it can generate the translated audio in the voice of the original speaker. This can be particularly useful for international collaborations or accessibility purposes.
Another idea is to explore the model's capabilities for audio restoration and enhancement. By providing VoiceCraft with a low-quality audio recording and the desired improvements, it may be able to generate a higher-quality version of the audio, while preserving the original speaker's voice.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Models

videocrafter
28
VideoCrafter is an open-source video generation and editing toolbox created by cjwbw, known for developing models like voicecraft, animagine-xl-3.1, video-retalking, and tokenflow. The latest version, VideoCrafter2, overcomes data limitations to generate high-quality videos from text or images. Model inputs and outputs VideoCrafter2 allows users to generate videos from text prompts or input images. The model takes in a text prompt, a seed value, denoising steps, and guidance scale as inputs, and outputs a video file. Inputs Prompt**: A text description of the video to be generated. Seed**: A random seed value to control the output video generation. Ddim Steps**: The number of denoising steps in the diffusion process. Unconditional Guidance Scale**: The classifier-free guidance scale, which controls the balance between the text prompt and unconditional generation. Outputs Video File**: A generated video file that corresponds to the provided text prompt or input image. Capabilities VideoCrafter2 can generate a wide variety of high-quality videos from text prompts, including scenes with people, animals, and abstract concepts. The model also supports image-to-video generation, allowing users to create dynamic videos from static images. What can I use it for? VideoCrafter2 can be used for various creative and practical applications, such as generating promotional videos, creating animated content, and augmenting video production workflows. The model's ability to generate videos from text or images can be especially useful for content creators, marketers, and storytellers who want to bring their ideas to life in a visually engaging way. Things to try Experiment with different text prompts to see the diverse range of videos VideoCrafter2 can generate. Try combining different concepts, styles, and settings to push the boundaries of what the model can create. You can also explore the image-to-video capabilities by providing various input images and observing how the model translates them into dynamic videos.
Updated Invalid Date
↗️
whisper
52
whisper is a large, general-purpose speech recognition model developed by OpenAI. It is trained on a diverse dataset of audio and can perform a variety of speech-related tasks, including multilingual speech recognition, speech translation, and spoken language identification. The whisper model is available in different sizes, with the larger models offering better accuracy at the cost of increased memory and compute requirements. The maintainer, cjwbw, has also created several similar models, such as stable-diffusion-2-1-unclip, anything-v3-better-vae, and dreamshaper, that explore different approaches to image generation and manipulation. Model inputs and outputs The whisper model is a sequence-to-sequence model that takes audio as input and produces a text transcript as output. It can handle a variety of audio formats, including FLAC, MP3, and WAV files. The model can also be used to perform speech translation, where the input audio is in one language and the output text is in another language. Inputs audio**: The audio file to be transcribed, in a supported format such as FLAC, MP3, or WAV. model**: The size of the whisper model to use, with options ranging from tiny to large. language**: The language spoken in the audio, or None to perform language detection. translate**: A boolean flag to indicate whether the output should be translated to English. Outputs transcription**: The text transcript of the input audio, in the specified format (e.g., plain text). Capabilities The whisper model is capable of performing high-quality speech recognition across a wide range of languages, including less common languages. It can also handle various accents and speaking styles, making it a versatile tool for transcribing diverse audio content. The model's ability to perform speech translation is particularly useful for applications where users need to consume content in a language they don't understand. What can I use it for? The whisper model can be used in a variety of applications, such as: Transcribing audio recordings for content creation, research, or accessibility purposes. Translating speech-based content, such as videos or podcasts, into multiple languages. Integrating speech recognition and translation capabilities into chatbots, virtual assistants, or other conversational interfaces. Automating the captioning or subtitling of video content. Things to try One interesting aspect of the whisper model is its ability to detect the language spoken in the audio, even if it's not provided as an input. This can be useful for applications where the language is unknown or variable, such as transcribing multilingual conversations. Additionally, the model's performance can be fine-tuned by adjusting parameters like temperature, patience, and suppressed tokens, which can help improve accuracy for specific use cases.
Updated Invalid Date
📊
openvoice
9
The openvoice model, developed by the team at MyShell, is a versatile instant voice cloning AI that can accurately clone the tone color and generate speech in multiple languages and accents. It offers flexible control over voice styles, such as emotion and accent, as well as other style parameters like rhythm, pauses, and intonation. The model also supports zero-shot cross-lingual voice cloning, allowing it to generate speech in languages not present in the training dataset. The openvoice model builds upon several excellent open-source projects, including TTS, VITS, and VITS2. It has been powering the instant voice cloning capability of myshell.ai since May 2023 and has been used tens of millions of times by users worldwide, witnessing explosive growth on the platform. Model inputs and outputs Inputs Audio**: The reference audio used to clone the tone color. Text**: The text to be spoken by the cloned voice. Speed**: The speed scale of the output audio. Language**: The language of the audio to be generated. Outputs Output**: The generated audio in the cloned voice. Capabilities The openvoice model excels at accurate tone color cloning, flexible voice style control, and zero-shot cross-lingual voice cloning. It can generate speech in multiple languages and accents, while allowing for granular control over voice styles, including emotion and accent, as well as other parameters like rhythm, pauses, and intonation. What can I use it for? The openvoice model can be used for a variety of applications, such as: Instant voice cloning for audio, video, or gaming content Customized text-to-speech for assistants, chatbots, or audiobooks Multilingual voice acting and dubbing Voice conversion and style transfer Things to try With the openvoice model, you can experiment with different input reference audios to clone a wide range of voices and accents. You can also play with the style parameters to create unique and expressive speech outputs. Additionally, you can explore the model's cross-lingual capabilities by generating speech in languages not present in the training data.
Updated Invalid Date
⛏️
text2video-zero
40
The text2video-zero model, developed by cjwbw from Picsart AI Research, leverages the power of existing text-to-image synthesis methods, like Stable Diffusion, to enable zero-shot video generation. This means the model can generate videos directly from text prompts without any additional training or fine-tuning. The model is capable of producing temporally consistent videos that closely follow the provided textual guidance. The text2video-zero model is related to other text-guided diffusion models like Clip-Guided Diffusion and TextDiffuser, which explore various techniques for using diffusion models as text-to-image and text-to-video generators. Model Inputs and Outputs Inputs Prompt**: The textual description of the desired video content. Model Name**: The Stable Diffusion model to use as the base for video generation. Timestep T0 and T1**: The range of DDPM steps to perform, controlling the level of variance between frames. Motion Field Strength X and Y**: Parameters that control the amount of motion applied to the generated frames. Video Length**: The desired duration of the output video. Seed**: An optional random seed to ensure reproducibility. Outputs Video**: The generated video file based on the provided prompt and parameters. Capabilities The text2video-zero model can generate a wide variety of videos from text prompts, including scenes with animals, people, and fantastical elements. For example, it can produce videos of "a horse galloping on a street", "a panda surfing on a wakeboard", or "an astronaut dancing in outer space". The model is able to capture the movement and dynamics of the described scenes, resulting in temporally consistent and visually compelling videos. What can I use it for? The text2video-zero model can be useful for a variety of applications, such as: Generating video content for social media, marketing, or entertainment purposes. Prototyping and visualizing ideas or concepts that can be described in text form. Experimenting with creative video generation and exploring the boundaries of what is possible with AI-powered video synthesis. Things to try One interesting aspect of the text2video-zero model is its ability to incorporate additional guidance, such as poses or edges, to further influence the generated video. By providing a reference video or image with canny edges, the model can generate videos that closely follow the visual structure of the guidance, while still adhering to the textual prompt. Another intriguing feature is the model's support for Dreambooth specialization, which allows you to fine-tune the model on a specific visual style or character. This can be used to generate videos that have a distinct artistic or stylistic flair, such as "an astronaut dancing in the style of Van Gogh's Starry Night".
Updated Invalid Date