ALoRA: Allocating Low-Rank Adaptation for Fine-tuning Large Language Models
2403.16187
0
0
Abstract
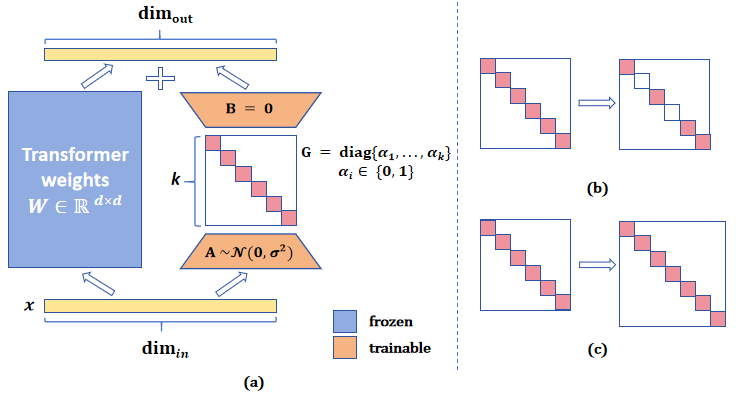
Parameter-efficient fine-tuning (PEFT) is widely studied for its effectiveness and efficiency in the era of large language models. Low-rank adaptation (LoRA) has demonstrated commendable performance as a popular and representative method. However, it is implemented with a fixed intrinsic rank that might not be the ideal setting for the downstream tasks. Recognizing the need for more flexible downstream task adaptation, we extend the methodology of LoRA to an innovative approach we call allocating low-rank adaptation (ALoRA) that enables dynamic adjustments to the intrinsic rank during the adaptation process. First, we propose a novel method, AB-LoRA, that can effectively estimate the importance score of each LoRA rank. Second, guided by AB-LoRA, we gradually prune abundant and negatively impacting LoRA ranks and allocate the pruned LoRA budgets to important Transformer modules needing higher ranks. We have conducted experiments on various tasks, and the experimental results demonstrate that our ALoRA method can outperform the recent baselines with comparable tunable parameters.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper introduces ALoRA, a novel method for fine-tuning large language models (LLMs) that is more parameter-efficient than traditional fine-tuning approaches.
- ALoRA works by allocating a small number of low-rank adaptation modules that are trained while keeping the majority of the model's parameters frozen.
- The paper compares ALoRA to other parameter-efficient fine-tuning (PEFT) techniques and shows that it outperforms these methods on a range of NLP tasks.
- The authors also present variants of ALoRA, including mTLoRA for multi-task learning and AFLoRA for adaptively freezing parameters during fine-tuning.
Plain English Explanation
Large language models (LLMs) like GPT-3 are powerful, but fine-tuning them on specific tasks can be computationally expensive and require retraining the entire model. The ALoRA method presented in this paper offers a more efficient solution.
Rather than retraining the entire model, ALoRA adds a small number of "low-rank adaptation" modules that are trained while most of the model's original parameters remain frozen. This allows the model to be fine-tuned for a new task without having to completely retrain it from scratch.
The paper shows that ALoRA outperforms other parameter-efficient fine-tuning (PEFT) techniques, like LoRA and Adapter Tuning, on a variety of natural language processing tasks. This makes ALoRA a promising approach for quickly adapting large language models to new applications.
The authors also introduce variants of ALoRA, such as mTLoRA for multi-task learning and AFLoRA for adaptively freezing model parameters during fine-tuning. These extensions demonstrate the flexibility and potential of the ALoRA approach.
Technical Explanation
The key idea behind ALoRA is to fine-tune large language models by adding a small number of low-rank adaptation modules, rather than retraining the entire model. These adaptation modules are trained while the majority of the model's original parameters remain frozen.
Specifically, ALoRA inserts low-rank matrices (called LoRA layers) into the attention and feed-forward layers of the LLM. These LoRA layers are then trained on the target task, while the original model weights are kept fixed. This allows the model to be fine-tuned using far fewer trainable parameters compared to full fine-tuning.
The paper compares ALoRA to other PEFT methods, including LoRA, Adapter Tuning, and BitFit. The results show that ALoRA outperforms these techniques on a range of natural language processing tasks, such as text classification, question answering, and natural language inference.
The authors also present two variants of ALoRA:
- mTLoRA for efficient multi-task fine-tuning, where a single set of LoRA layers is used across multiple tasks.
- AFLoRA for adaptively freezing parameters during fine-tuning, which can further improve parameter efficiency.
Critical Analysis
The paper provides a thorough evaluation of ALoRA and its variants, demonstrating their effectiveness compared to other PEFT methods. However, the authors do not discuss potential limitations or caveats of their approach.
One potential concern is the impact of the LoRA layers on the interpretability and transparency of the fine-tuned models. By modifying the core model architecture, ALoRA may make it more difficult to understand the internal workings and decision-making of the fine-tuned models.
Additionally, the paper does not address the potential for negative transfer or interference when using ALoRA for multi-task learning (mTLoRA). Further research may be needed to understand the conditions under which mTLoRA can be effectively applied without degrading performance on individual tasks.
Overall, the ALoRA method appears to be a promising advance in parameter-efficient fine-tuning of large language models. However, researchers and practitioners should consider the potential trade-offs and limitations when applying this technique in real-world scenarios.
Conclusion
The ALoRA method introduced in this paper offers a novel approach to fine-tuning large language models more efficiently than traditional fine-tuning techniques. By adding a small number of low-rank adaptation modules, ALoRA can adapt LLMs to new tasks while keeping the majority of the model's parameters frozen.
The paper's experimental results demonstrate the effectiveness of ALoRA, showing that it outperforms other parameter-efficient fine-tuning methods on a range of NLP tasks. The authors also present variants of ALoRA, such as mTLoRA for multi-task learning and AFLoRA for adaptive parameter freezing, further expanding the potential applications of this approach.
While the paper does not address all the potential limitations of ALoRA, it represents an important contribution to the field of efficient fine-tuning of large language models. As LLMs continue to grow in size and importance, techniques like ALoRA will be crucial for enabling their widespread adoption and application across a diverse range of domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌿
LoRA Land: 310 Fine-tuned LLMs that Rival GPT-4, A Technical Report
Justin Zhao, Timothy Wang, Wael Abid, Geoffrey Angus, Arnav Garg, Jeffery Kinnison, Alex Sherstinsky, Piero Molino, Travis Addair, Devvret Rishi
0
0
Low Rank Adaptation (LoRA) has emerged as one of the most widely adopted methods for Parameter Efficient Fine-Tuning (PEFT) of Large Language Models (LLMs). LoRA reduces the number of trainable parameters and memory usage while achieving comparable performance to full fine-tuning. We aim to assess the viability of training and serving LLMs fine-tuned with LoRA in real-world applications. First, we measure the quality of LLMs fine-tuned with quantized low rank adapters across 10 base models and 31 tasks for a total of 310 models. We find that 4-bit LoRA fine-tuned models outperform base models by 34 points and GPT-4 by 10 points on average. Second, we investigate the most effective base models for fine-tuning and assess the correlative and predictive capacities of task complexity heuristics in forecasting the outcomes of fine-tuning. Finally, we evaluate the latency and concurrency capabilities of LoRAX, an open-source Multi-LoRA inference server that facilitates the deployment of multiple LoRA fine-tuned models on a single GPU using shared base model weights and dynamic adapter loading. LoRAX powers LoRA Land, a web application that hosts 25 LoRA fine-tuned Mistral-7B LLMs on a single NVIDIA A100 GPU with 80GB memory. LoRA Land highlights the quality and cost-effectiveness of employing multiple specialized LLMs over a single, general-purpose LLM.
5/3/2024
LoRA Learns Less and Forgets Less
Dan Biderman, Jose Gonzalez Ortiz, Jacob Portes, Mansheej Paul, Philip Greengard, Connor Jennings, Daniel King, Sam Havens, Vitaliy Chiley, Jonathan Frankle, Cody Blakeney, John P. Cunningham
0
0
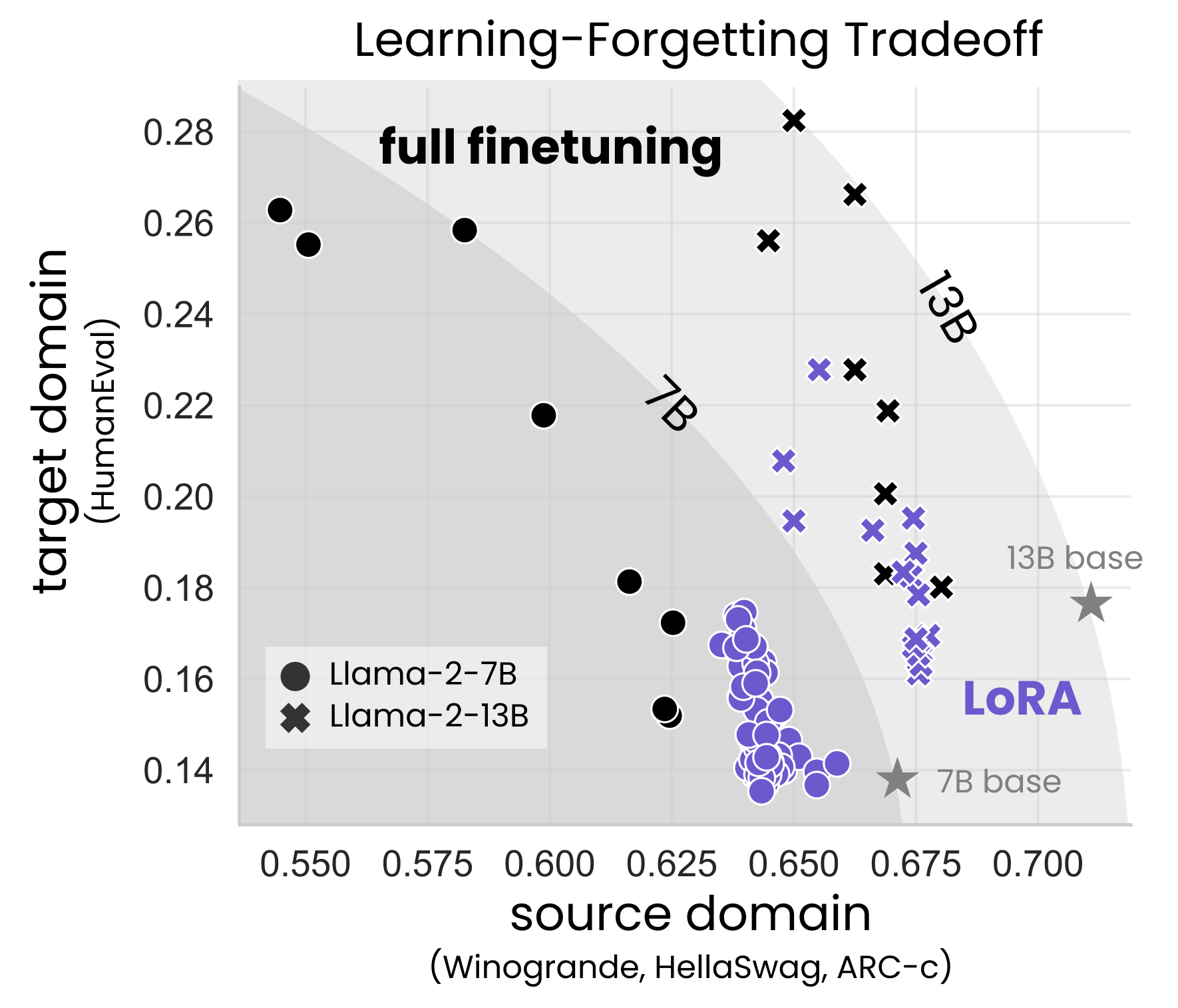
Low-Rank Adaptation (LoRA) is a widely-used parameter-efficient finetuning method for large language models. LoRA saves memory by training only low rank perturbations to selected weight matrices. In this work, we compare the performance of LoRA and full finetuning on two target domains, programming and mathematics. We consider both the instruction finetuning ($approx$100K prompt-response pairs) and continued pretraining ($approx$10B unstructured tokens) data regimes. Our results show that, in most settings, LoRA substantially underperforms full finetuning. Nevertheless, LoRA exhibits a desirable form of regularization: it better maintains the base model's performance on tasks outside the target domain. We show that LoRA provides stronger regularization compared to common techniques such as weight decay and dropout; it also helps maintain more diverse generations. We show that full finetuning learns perturbations with a rank that is 10-100X greater than typical LoRA configurations, possibly explaining some of the reported gaps. We conclude by proposing best practices for finetuning with LoRA.
5/17/2024
Batched Low-Rank Adaptation of Foundation Models
Yeming Wen, Swarat Chaudhuri
0
0
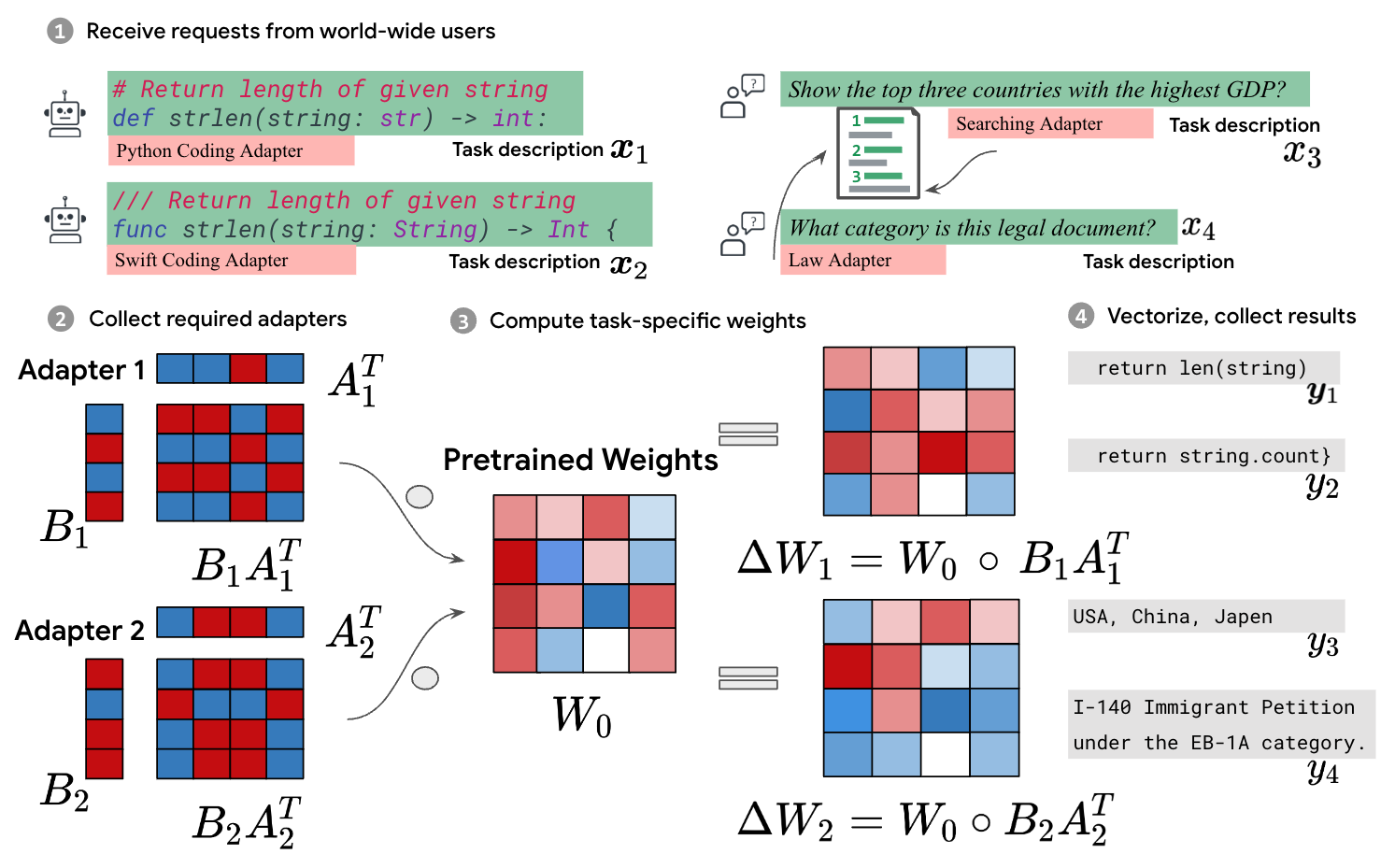
Low-Rank Adaptation (LoRA) has recently gained attention for fine-tuning foundation models by incorporating trainable low-rank matrices, thereby reducing the number of trainable parameters. While LoRA offers numerous advantages, its applicability for real-time serving to a diverse and global user base is constrained by its incapability to handle multiple task-specific adapters efficiently. This imposes a performance bottleneck in scenarios requiring personalized, task-specific adaptations for each incoming request. To mitigate this constraint, we introduce Fast LoRA (FLoRA), a framework in which each input example in a minibatch can be associated with its unique low-rank adaptation weights, allowing for efficient batching of heterogeneous requests. We empirically demonstrate that FLoRA retains the performance merits of LoRA, showcasing competitive results on the MultiPL-E code generation benchmark spanning over 8 languages and a multilingual speech recognition task across 6 languages.
4/29/2024
HydraLoRA: An Asymmetric LoRA Architecture for Efficient Fine-Tuning
Chunlin Tian, Zhan Shi, Zhijiang Guo, Li Li, Chengzhong Xu
0
0
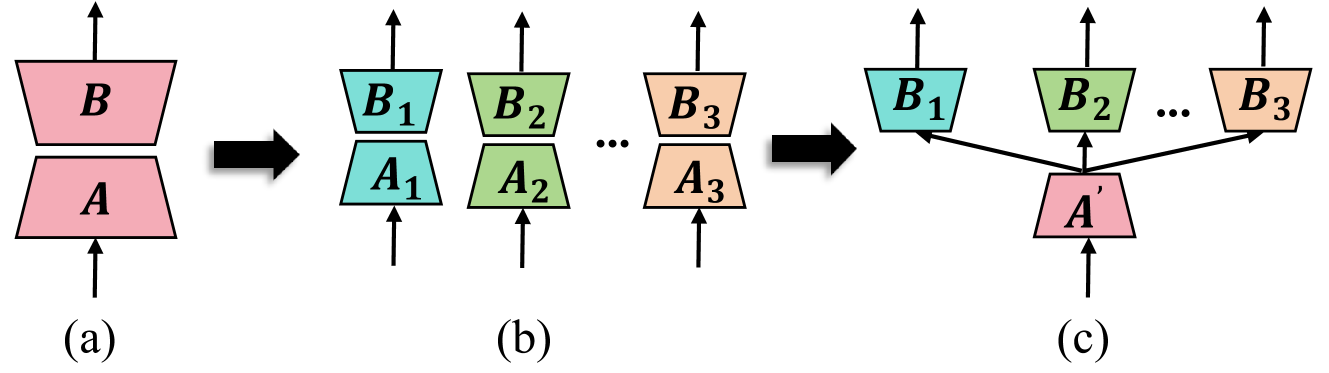
Adapting Large Language Models (LLMs) to new tasks through fine-tuning has been made more efficient by the introduction of Parameter-Efficient Fine-Tuning (PEFT) techniques, such as LoRA. However, these methods often underperform compared to full fine-tuning, particularly in scenarios involving complex datasets. This issue becomes even more pronounced in complex domains, highlighting the need for improved PEFT approaches that can achieve better performance. Through a series of experiments, we have uncovered two critical insights that shed light on the training and parameter inefficiency of LoRA. Building on these insights, we have developed HydraLoRA, a LoRA framework with an asymmetric structure that eliminates the need for domain expertise. Our experiments demonstrate that HydraLoRA outperforms other PEFT approaches, even those that rely on domain knowledge during the training and inference phases. href{https://github.com/Clin0212/HydraLoRA}{Code}.
5/1/2024