Arrange, Inpaint, and Refine: Steerable Long-term Music Audio Generation and Editing via Content-based Controls
2402.09508
0
0
Abstract
Controllable music generation plays a vital role in human-AI music co-creation. While Large Language Models (LLMs) have shown promise in generating high-quality music, their focus on autoregressive generation limits their utility in music editing tasks. To address this gap, we propose a novel approach leveraging a parameter-efficient heterogeneous adapter combined with a masking training scheme. This approach enables autoregressive language models to seamlessly address music inpainting tasks. Additionally, our method integrates frame-level content-based controls, facilitating track-conditioned music refinement and score-conditioned music arrangement. We apply this method to fine-tune MusicGen, a leading autoregressive music generation model. Our experiments demonstrate promising results across multiple music editing tasks, offering more flexible controls for future AI-driven music editing tools. The source codes and a demo page showcasing our work are available at https://kikyo-16.github.io/AIR.
Create account to get full access
Overview
• This paper presents a novel approach for generating and editing long-term music audio using content-based controls.
• The method, called "Arrange, Inpaint, and Refine," allows for the generation of coherent and expressive music by providing users with intuitive high-level controls over the musical content.
• The system leverages large language models and diffusion-based generation to enable users to seamlessly arrange, inpaint, and refine music, empowering them to create diverse and customized musical experiences.
Plain English Explanation
The paper describes a new way to generate and edit long musical pieces using high-level controls. Instead of having to manually create every aspect of a song, the system allows users to provide broad instructions or descriptions, and the model will generate the music to match.
For example, a user could instruct the system to "arrange a jazzy piano piece with a laid-back groove." The model would then generate a cohesive musical composition that fits that description, handling all the details of the instrumentation, melody, harmony, and rhythm.
Users can also "inpaint" parts of the music, where they select a section and tell the model to modify or replace it according to new instructions, such as "add a guitar solo here." Additionally, the system enables users to "refine" the music, making small adjustments to the generated content to further customize it.
This approach empowers users to create diverse and personalized musical experiences without requiring extensive musical knowledge or production skills. By leveraging large language models and advanced generation techniques, the system can produce long-form, coherent music that captures the user's creative vision.
Technical Explanation
The paper introduces the "Arrange, Inpaint, and Refine" framework for long-term music audio generation and editing. The system utilizes a pipeline that combines large language models and diffusion-based generation to enable content-based controls over the musical output.
The first stage, "Arrange," involves using a text-to-music model to generate an initial musical composition based on a user's high-level instructions. [This builds on related work in text-to-music systems like https://aimodels.fyi/papers/arxiv/instruct-musicgen-unlocking-text-to-music-editing.]
The "Inpaint" stage allows users to select a section of the generated music and provide new instructions, which the model then uses to modify or replace that specific part of the composition. [This relates to techniques in audio inpainting, such as those explored in https://aimodels.fyi/papers/arxiv/audioldm-2-learning-holistic-audio-generation-self.]
Finally, the "Refine" stage enables fine-grained adjustments to the generated music, empowering users to further customize the output to their liking. [This builds upon work in interactive music generation, like https://aimodels.fyi/papers/arxiv/mozarts-touch-lightweight-multi-modal-music-generation.]
The system leverages large language models trained on both text and audio data to capture the semantic and musical relationships necessary for this type of long-form, content-based music generation and editing. [This integrates ideas from research on using large language models for music, as seen in https://aimodels.fyi/papers/arxiv/content-based-controls-music-large-language-modeling and https://aimodels.fyi/papers/arxiv/long-form-music-generation-latent-diffusion.]
Critical Analysis
The paper presents a compelling approach to music generation and editing that empowers users to create customized, long-form musical compositions. However, the authors acknowledge certain limitations and avenues for future research.
One potential concern is the reliance on large language models, which can be prone to biases and inconsistencies in their outputs. The authors suggest exploring ways to further improve the coherence and quality of the generated music, particularly over extended durations.
Additionally, while the "Inpaint" and "Refine" stages offer useful editing capabilities, the extent to which users can control and fine-tune the music may be limited by the underlying model's capabilities. Further research could investigate more advanced user control mechanisms or the integration of additional musical knowledge into the system.
The authors also note that the current system is focused on solo instrumental music and may need to be adapted to handle more complex musical arrangements, such as those involving multiple instruments and vocals. Exploring ways to scale the approach to more diverse musical genres and styles could be an area for future work.
Conclusion
The "Arrange, Inpaint, and Refine" framework presented in this paper represents a significant step forward in enabling users to generate and edit long-form music using intuitive, content-based controls. By leveraging large language models and diffusion-based generation, the system empowers users to create customized, coherent musical compositions without requiring extensive musical expertise.
This research has the potential to democratize music creation, allowing a wider audience to explore and express their musical ideas. Additionally, the techniques developed in this work could find applications in various domains, such as soundtrack generation for multimedia, personalized music therapy, and educational tools for aspiring musicians.
As the field of AI-assisted music generation continues to evolve, this paper serves as an important contribution, showcasing the potential of leveraging large language models and advanced generation techniques to unlock new frontiers in long-term, content-based music creation and editing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Content-based Controls For Music Large Language Modeling
Liwei Lin, Gus Xia, Junyan Jiang, Yixiao Zhang
0
0
Recent years have witnessed a rapid growth of large-scale language models in the domain of music audio. Such models enable end-to-end generation of higher-quality music, and some allow conditioned generation using text descriptions. However, the control power of text controls on music is intrinsically limited, as they can only describe music indirectly through meta-data (such as singers and instruments) or high-level representations (such as genre and emotion). We aim to further equip the models with direct and content-based controls on innate music languages such as pitch, chords and drum track. To this end, we contribute Coco-Mulla, a content-based control method for music large language modeling. It uses a parameter-efficient fine-tuning (PEFT) method tailored for Transformer-based audio models. Experiments show that our approach achieved high-quality music generation with low-resource semi-supervised learning, tuning with less than 4% parameters compared to the original model and training on a small dataset with fewer than 300 songs. Moreover, our approach enables effective content-based controls, and we illustrate the control power via chords and rhythms, two of the most salient features of music audio. Furthermore, we show that by combining content-based controls and text descriptions, our system achieves flexible music variation generation and arrangement. Our source codes and demos are available online.
4/16/2024

Instruct-MusicGen: Unlocking Text-to-Music Editing for Music Language Models via Instruction Tuning
Yixiao Zhang, Yukara Ikemiya, Woosung Choi, Naoki Murata, Marco A. Mart'inez-Ram'irez, Liwei Lin, Gus Xia, Wei-Hsiang Liao, Yuki Mitsufuji, Simon Dixon
0
0
Recent advances in text-to-music editing, which employ text queries to modify music (e.g. by changing its style or adjusting instrumental components), present unique challenges and opportunities for AI-assisted music creation. Previous approaches in this domain have been constrained by the necessity to train specific editing models from scratch, which is both resource-intensive and inefficient; other research uses large language models to predict edited music, resulting in imprecise audio reconstruction. To Combine the strengths and address these limitations, we introduce Instruct-MusicGen, a novel approach that finetunes a pretrained MusicGen model to efficiently follow editing instructions such as adding, removing, or separating stems. Our approach involves a modification of the original MusicGen architecture by incorporating a text fusion module and an audio fusion module, which allow the model to process instruction texts and audio inputs concurrently and yield the desired edited music. Remarkably, Instruct-MusicGen only introduces 8% new parameters to the original MusicGen model and only trains for 5K steps, yet it achieves superior performance across all tasks compared to existing baselines, and demonstrates performance comparable to the models trained for specific tasks. This advancement not only enhances the efficiency of text-to-music editing but also broadens the applicability of music language models in dynamic music production environments.
5/30/2024
🛸
AudioLDM 2: Learning Holistic Audio Generation with Self-supervised Pretraining
Haohe Liu, Yi Yuan, Xubo Liu, Xinhao Mei, Qiuqiang Kong, Qiao Tian, Yuping Wang, Wenwu Wang, Yuxuan Wang, Mark D. Plumbley
0
0
Although audio generation shares commonalities across different types of audio, such as speech, music, and sound effects, designing models for each type requires careful consideration of specific objectives and biases that can significantly differ from those of other types. To bring us closer to a unified perspective of audio generation, this paper proposes a framework that utilizes the same learning method for speech, music, and sound effect generation. Our framework introduces a general representation of audio, called language of audio (LOA). Any audio can be translated into LOA based on AudioMAE, a self-supervised pre-trained representation learning model. In the generation process, we translate any modalities into LOA by using a GPT-2 model, and we perform self-supervised audio generation learning with a latent diffusion model conditioned on LOA. The proposed framework naturally brings advantages such as in-context learning abilities and reusable self-supervised pretrained AudioMAE and latent diffusion models. Experiments on the major benchmarks of text-to-audio, text-to-music, and text-to-speech demonstrate state-of-the-art or competitive performance against previous approaches. Our code, pretrained model, and demo are available at https://audioldm.github.io/audioldm2.
5/14/2024
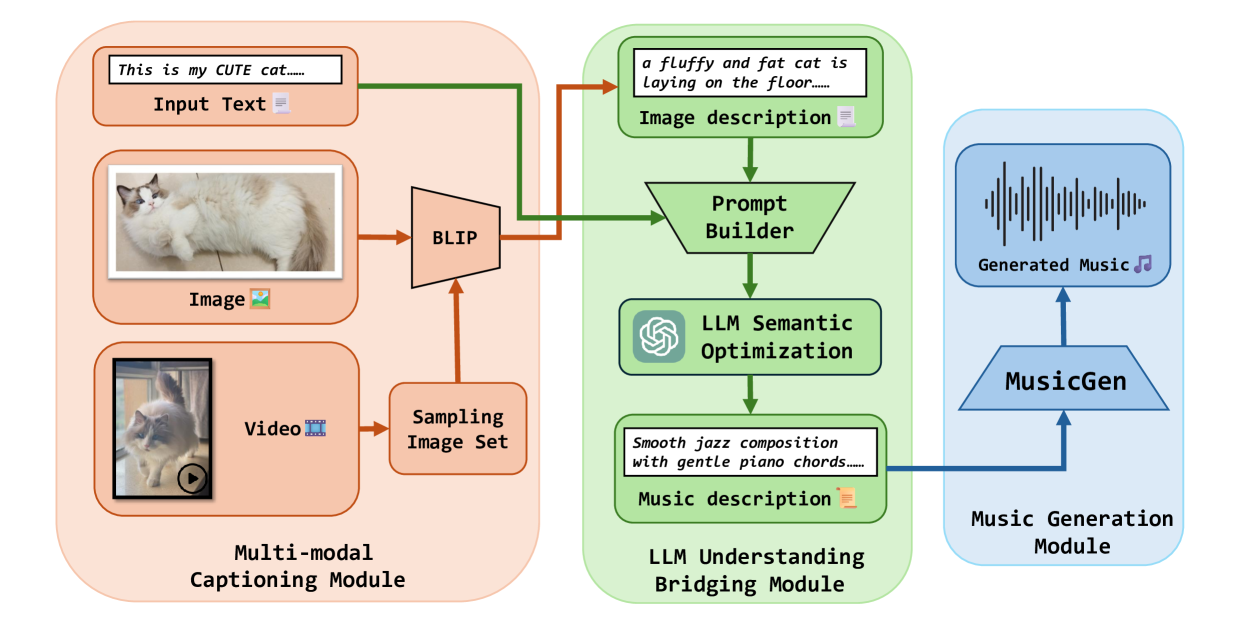
Mozart's Touch: A Lightweight Multi-modal Music Generation Framework Based on Pre-Trained Large Models
Tianze Xu, Jiajun Li, Xuesong Chen, Xinrui Yao, Shuchang Liu
0
0
In recent years, AI-Generated Content (AIGC) has witnessed rapid advancements, facilitating the generation of music, images, and other forms of artistic expression across various industries. However, researches on general multi-modal music generation model remain scarce. To fill this gap, we propose a multi-modal music generation framework Mozart's Touch. It could generate aligned music with the cross-modality inputs, such as images, videos and text. Mozart's Touch is composed of three main components: Multi-modal Captioning Module, Large Language Model (LLM) Understanding & Bridging Module, and Music Generation Module. Unlike traditional approaches, Mozart's Touch requires no training or fine-tuning pre-trained models, offering efficiency and transparency through clear, interpretable prompts. We also introduce LLM-Bridge method to resolve the heterogeneous representation problems between descriptive texts of different modalities. We conduct a series of objective and subjective evaluations on the proposed model, and results indicate that our model surpasses the performance of current state-of-the-art models. Our codes and examples is availble at: https://github.com/WangTooNaive/MozartsTouch
5/8/2024