Behind the Veil: Enhanced Indoor 3D Scene Reconstruction with Occluded Surfaces Completion
2404.03070
0
0
Abstract
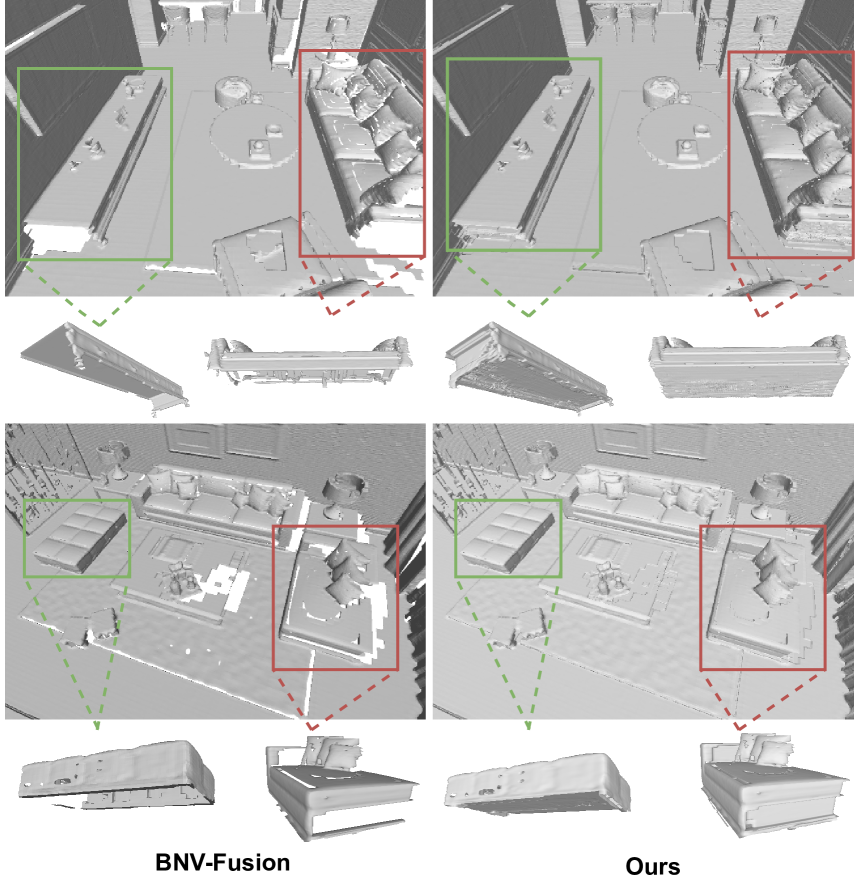
In this paper, we present a novel indoor 3D reconstruction method with occluded surface completion, given a sequence of depth readings. Prior state-of-the-art (SOTA) methods only focus on the reconstruction of the visible areas in a scene, neglecting the invisible areas due to the occlusions, e.g., the contact surface between furniture, occluded wall and floor. Our method tackles the task of completing the occluded scene surfaces, resulting in a complete 3D scene mesh. The core idea of our method is learning 3D geometry prior from various complete scenes to infer the occluded geometry of an unseen scene from solely depth measurements. We design a coarse-fine hierarchical octree representation coupled with a dual-decoder architecture, i.e., Geo-decoder and 3D Inpainter, which jointly reconstructs the complete 3D scene geometry. The Geo-decoder with detailed representation at fine levels is optimized online for each scene to reconstruct visible surfaces. The 3D Inpainter with abstract representation at coarse levels is trained offline using various scenes to complete occluded surfaces. As a result, while the Geo-decoder is specialized for an individual scene, the 3D Inpainter can be generally applied across different scenes. We evaluate the proposed method on the 3D Completed Room Scene (3D-CRS) and iTHOR datasets, significantly outperforming the SOTA methods by a gain of 16.8% and 24.2% in terms of the completeness of 3D reconstruction. 3D-CRS dataset including a complete 3D mesh of each scene is provided at project webpage.
Create account to get full access
Overview
- This research paper presents an enhanced method for 3D scene reconstruction that can handle occluded surfaces, enabling more complete and detailed indoor environments.
- The key innovation is a new neural network architecture that can estimate the geometry of occluded surfaces behind visible objects, filling in gaps in the 3D model.
- Experiments show this approach outperforms previous 3D reconstruction methods, generating more accurate and complete 3D models of complex indoor scenes.
Plain English Explanation
The paper tackles the challenge of 3D scene reconstruction - creating detailed 3D digital models of real-world spaces. This is an important task for applications like virtual reality, robotics, and architectural design.
One key limitation of existing 3D reconstruction methods is that they struggle with occluded surfaces - areas that are hidden from the camera's view, such as the back of furniture or the insides of cabinets. These missing pieces leave gaps in the final 3D model, reducing its accuracy and completeness.
The researchers developed a new neural network that can "see through" these occluded areas and estimate the hidden geometry. It works by analyzing the visible parts of the scene and using that information to predict the likely shape and position of the unseen surfaces. This allows the 3D model to be filled in, creating a more comprehensive and realistic representation of the real-world environment.
Experiments show this occluded surface completion approach outperforms previous 3D reconstruction techniques, producing more accurate and detailed 3D models of complex indoor spaces. This could enable more immersive virtual reality experiences, better robot navigation, and more realistic digital twins of physical buildings.
Technical Explanation
The core of the method is a neural network architecture consisting of several key components:
-
Visible Surface Encoder: This module takes in the observed RGB-D (color and depth) data from the camera and encodes it into a compact feature representation.
-
Occluded Surface Predictor: This part of the network uses the encoded visible features to predict the likely geometry of the occluded surfaces. It does this by learning to map from the observed data to the hidden geometry in the training data.
-
Fusion Module: The final step combines the predicted occluded surface geometry with the observed visible surfaces to generate the complete 3D reconstruction.
The researchers trained this network end-to-end on a large dataset of real-world indoor scenes, enabling it to learn the patterns and relationships between visible and occluded surfaces. Experiments on benchmark 3D reconstruction datasets showed this approach outperformed previous state-of-the-art methods in terms of accuracy and completeness of the reconstructed 3D models.
Critical Analysis
The paper provides a compelling technical solution to the challenge of 3D scene reconstruction with occluded surfaces. The neural network architecture is well-designed and the experimental results demonstrate its effectiveness.
However, one potential limitation is the reliance on the training dataset - the network's performance may be constrained by the diversity and realism of the scenes it was trained on. Evaluating its generalization to novel, unseen environments could be an area for further research.
Additionally, the paper does not deeply explore the potential downstream applications and user experiences enabled by this more complete 3D reconstruction. More discussion of how this could impact fields like virtual reality, robotics, and architectural design could strengthen the paper's impact.
Overall, this is a technically robust and innovative contribution to the 3D scene reconstruction literature, with the potential for significant real-world applications if the approach can be further refined and validated.
Conclusion
This research presents an enhanced neural network-based method for 3D scene reconstruction that can handle occluded surfaces, enabling more complete and accurate digital models of complex indoor environments. The key innovation is the ability to estimate the geometry of hidden areas based on the observed visible data.
Experiments show this approach outperforms previous state-of-the-art 3D reconstruction techniques, generating more comprehensive and realistic 3D models. This could lead to significant improvements in applications like virtual reality, robotics, and architectural design, where accurate and complete 3D representations of physical spaces are critical.
While the paper focuses on the technical details, further exploration of the real-world implications and user experiences facilitated by this advancement in 3D reconstruction could strengthen the broader impact of this research. Overall, this is an impressive contribution that pushes the boundaries of what is possible in reconstructing the 3D world from partial observations.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

GEOcc: Geometrically Enhanced 3D Occupancy Network with Implicit-Explicit Depth Fusion and Contextual Self-Supervision
Xin Tan, Wenbin Wu, Zhiwei Zhang, Chaojie Fan, Yong Peng, Zhizhong Zhang, Yuan Xie, Lizhuang Ma
0
0
3D occupancy perception holds a pivotal role in recent vision-centric autonomous driving systems by converting surround-view images into integrated geometric and semantic representations within dense 3D grids. Nevertheless, current models still encounter two main challenges: modeling depth accurately in the 2D-3D view transformation stage, and overcoming the lack of generalizability issues due to sparse LiDAR supervision. To address these issues, this paper presents GEOcc, a Geometric-Enhanced Occupancy network tailored for vision-only surround-view perception. Our approach is three-fold: 1) Integration of explicit lift-based depth prediction and implicit projection-based transformers for depth modeling, enhancing the density and robustness of view transformation. 2) Utilization of mask-based encoder-decoder architecture for fine-grained semantic predictions; 3) Adoption of context-aware self-training loss functions in the pertaining stage to complement LiDAR supervision, involving the re-rendering of 2D depth maps from 3D occupancy features and leveraging image reconstruction loss to obtain denser depth supervision besides sparse LiDAR ground-truths. Our approach achieves State-Of-The-Art performance on the Occ3D-nuScenes dataset with the least image resolution needed and the most weightless image backbone compared with current models, marking an improvement of 3.3% due to our proposed contributions. Comprehensive experimentation also demonstrates the consistent superiority of our method over baselines and alternative approaches.
5/20/2024

The More You See in 2D, the More You Perceive in 3D
Xinyang Han, Zelin Gao, Angjoo Kanazawa, Shubham Goel, Yossi Gandelsman
0
0
Humans can infer 3D structure from 2D images of an object based on past experience and improve their 3D understanding as they see more images. Inspired by this behavior, we introduce SAP3D, a system for 3D reconstruction and novel view synthesis from an arbitrary number of unposed images. Given a few unposed images of an object, we adapt a pre-trained view-conditioned diffusion model together with the camera poses of the images via test-time fine-tuning. The adapted diffusion model and the obtained camera poses are then utilized as instance-specific priors for 3D reconstruction and novel view synthesis. We show that as the number of input images increases, the performance of our approach improves, bridging the gap between optimization-based prior-less 3D reconstruction methods and single-image-to-3D diffusion-based methods. We demonstrate our system on real images as well as standard synthetic benchmarks. Our ablation studies confirm that this adaption behavior is key for more accurate 3D understanding.
4/5/2024
⚙️
Invisible Stitch: Generating Smooth 3D Scenes with Depth Inpainting
Paul Engstler, Andrea Vedaldi, Iro Laina, Christian Rupprecht
0
0
3D scene generation has quickly become a challenging new research direction, fueled by consistent improvements of 2D generative diffusion models. Most prior work in this area generates scenes by iteratively stitching newly generated frames with existing geometry. These works often depend on pre-trained monocular depth estimators to lift the generated images into 3D, fusing them with the existing scene representation. These approaches are then often evaluated via a text metric, measuring the similarity between the generated images and a given text prompt. In this work, we make two fundamental contributions to the field of 3D scene generation. First, we note that lifting images to 3D with a monocular depth estimation model is suboptimal as it ignores the geometry of the existing scene. We thus introduce a novel depth completion model, trained via teacher distillation and self-training to learn the 3D fusion process, resulting in improved geometric coherence of the scene. Second, we introduce a new benchmarking scheme for scene generation methods that is based on ground truth geometry, and thus measures the quality of the structure of the scene.
5/1/2024

A Two-Stage Masked Autoencoder Based Network for Indoor Depth Completion
Kailai Sun, Zhou Yang, Qianchuan Zhao
0
0
Depth images have a wide range of applications, such as 3D reconstruction, autonomous driving, augmented reality, robot navigation, and scene understanding. Commodity-grade depth cameras are hard to sense depth for bright, glossy, transparent, and distant surfaces. Although existing depth completion methods have achieved remarkable progress, their performance is limited when applied to complex indoor scenarios. To address these problems, we propose a two-step Transformer-based network for indoor depth completion. Unlike existing depth completion approaches, we adopt a self-supervision pre-training encoder based on the masked autoencoder to learn an effective latent representation for the missing depth value; then we propose a decoder based on a token fusion mechanism to complete (i.e., reconstruct) the full depth from the jointly RGB and incomplete depth image. Compared to the existing methods, our proposed network, achieves the state-of-the-art performance on the Matterport3D dataset. In addition, to validate the importance of the depth completion task, we apply our methods to indoor 3D reconstruction. The code, dataset, and demo are available at https://github.com/kailaisun/Indoor-Depth-Completion.
6/17/2024