BiLLM: Pushing the Limit of Post-Training Quantization for LLMs
2402.04291
0
0
Abstract
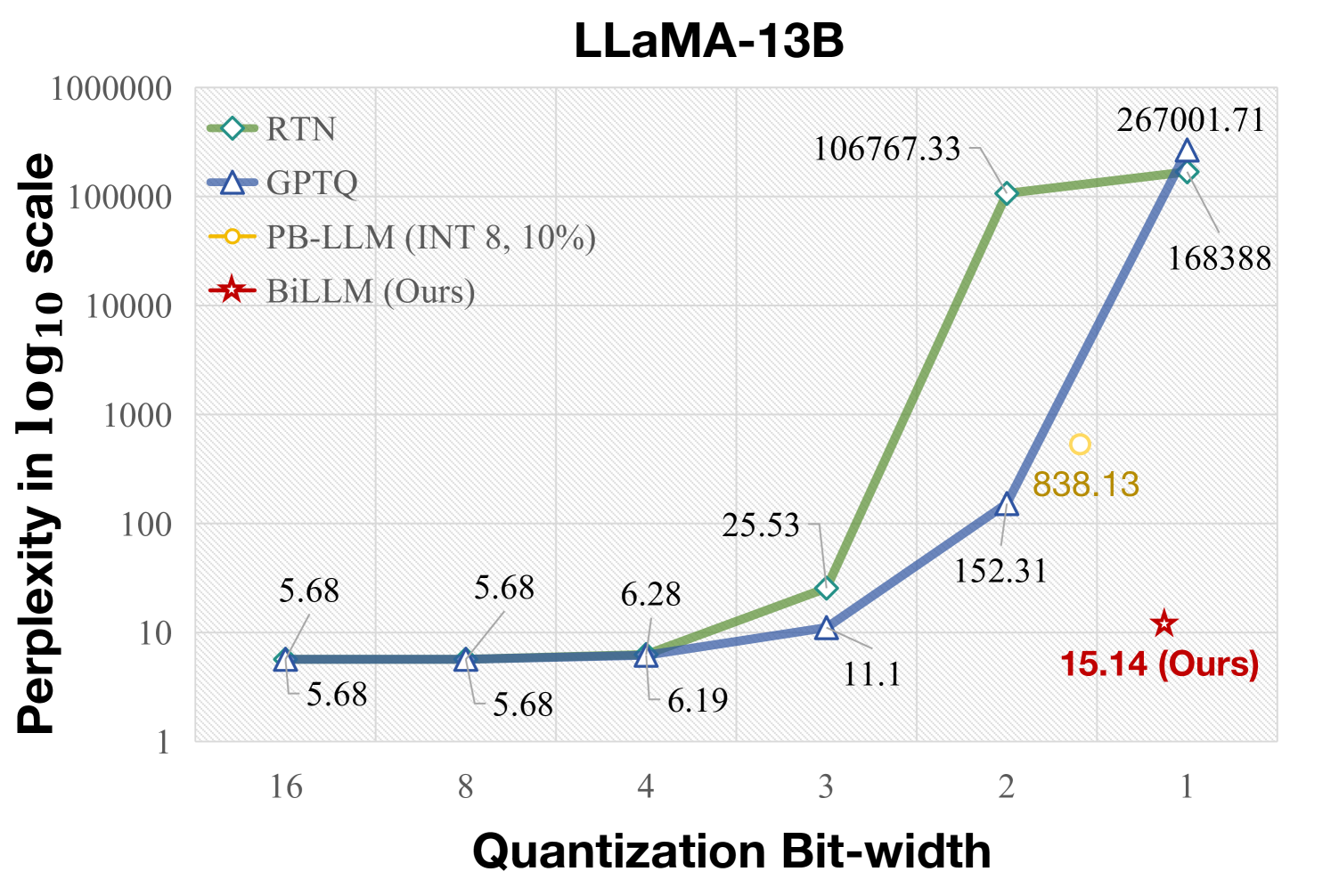
Pretrained large language models (LLMs) exhibit exceptional general language processing capabilities but come with significant demands on memory and computational resources. As a powerful compression technology, binarization can extremely reduce model weights to a mere 1 bit, lowering the expensive computation and memory requirements. However, existing quantization techniques fall short of maintaining LLM performance under ultra-low bit-widths. In response to this challenge, we present BiLLM, a groundbreaking 1-bit post-training quantization scheme tailored for pretrained LLMs. Based on the weight distribution of LLMs, BiLLM first identifies and structurally selects salient weights, and minimizes the compression loss through an effective binary residual approximation strategy. Moreover, considering the bell-shaped distribution of the non-salient weights, we propose an optimal splitting search to group and binarize them accurately. BiLLM achieving for the first time high-accuracy inference (e.g. 8.41 perplexity on LLaMA2-70B) with only 1.08-bit weights across various LLMs families and evaluation metrics, outperforms SOTA quantization methods of LLM by significant margins. Moreover, BiLLM enables the binarization process of the LLM with 7 billion weights within 0.5 hours on a single GPU, demonstrating satisfactory time efficiency. Our code is available at https://github.com/Aaronhuang-778/BiLLM.
Create account to get full access
Overview
• This paper introduces BiLLM, a novel method for post-training quantization of large language models (LLMs) that can push the limits of model compression without significantly impacting performance.
• The researchers combine multiple post-training techniques, including binarization, weight sharing, and layer-wise optimization, to achieve high compression rates for LLMs while maintaining high accuracy.
• The paper compares BiLLM to other state-of-the-art quantization methods and demonstrates its effectiveness on several benchmark tasks, including LLM-QBench.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can understand and generate human-like text. However, these models are typically very large and resource-intensive, making them difficult to deploy on devices with limited computing power, such as smartphones or edge devices.
The researchers in this paper have developed a new method called BiLLM that can compress LLMs by up to 32 times without significantly affecting their performance. They achieve this by combining several techniques, including binarization (reducing the weights to just two possible values), weight sharing (using the same weights for multiple parts of the model), and layer-wise optimization (fine-tuning each layer of the model separately).
By applying these techniques, the researchers were able to create smaller, more efficient versions of LLMs that can be deployed on a wider range of devices. This could make it easier to use these powerful AI models in a variety of real-world applications, such as language translation, voice assistants, and content generation.
Technical Explanation
The key innovation of the BiLLM method is the combination of multiple post-training quantization techniques to achieve high compression rates for LLMs. The researchers start by binarizing the model weights, which reduces each weight to just two possible values (0 or 1). This dramatically reduces the model size, but can also significantly impact performance.
To mitigate the performance loss, the researchers then apply weight sharing, which reduces the number of unique weights in the model. They also use a layer-wise optimization approach, where each layer of the model is fine-tuned separately to recover any accuracy lost during the quantization process.
The researchers evaluate BiLLM on several benchmark tasks, including LLM-QBench, and compare its performance to other state-of-the-art quantization methods, such as QLLM and OneUBMOD. The results show that BiLLM can achieve up to 32x compression with minimal impact on model accuracy, outperforming the other methods.
Critical Analysis
The paper provides a comprehensive evaluation of BiLLM and demonstrates its effectiveness on a range of benchmark tasks. However, it's important to note that the researchers only tested BiLLM on a limited set of LLMs, and it's unclear how the method would perform on larger or more complex models.
Additionally, the paper does not address the potential practical challenges of deploying compressed LLMs in real-world scenarios, such as the impact on inference latency or the difficulty of fine-tuning or updating the models after deployment.
Further research may be needed to explore these issues and to investigate the broader implications of highly compressed LLMs, such as their potential impact on energy consumption or carbon emissions.
Conclusion
This paper introduces BiLLM, a novel method for post-training quantization of large language models that can achieve up to 32x compression without significantly impacting model performance. By combining multiple quantization techniques, the researchers have developed a more efficient and effective approach to model compression, which could make it easier to deploy powerful LLMs on a wider range of devices.
The results of the paper are promising and could have significant implications for the field of natural language processing, potentially enabling new applications and use cases for LLMs that were previously infeasible due to their resource-intensive nature.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

SliM-LLM: Salience-Driven Mixed-Precision Quantization for Large Language Models
Wei Huang, Haotong Qin, Yangdong Liu, Yawei Li, Xianglong Liu, Luca Benini, Michele Magno, Xiaojuan Qi
0
0
Large language models (LLMs) achieve remarkable performance in natural language understanding but require substantial computation and memory resources. Post-training quantization (PTQ) is a powerful compression technique extensively investigated in LLMs. However, existing PTQ methods are still not ideal in terms of accuracy and efficiency, especially with below 4 bit-widths. Standard PTQ methods using group-wise quantization suffer difficulties in quantizing LLMs accurately to such low-bit, but advanced methods remaining high-precision weights element-wisely are hard to realize their theoretical hardware efficiency. This paper presents a Salience-Driven Mixed-Precision Quantization scheme for LLMs, namely SliM-LLM. The scheme exploits the salience distribution of weights to determine optimal bit-width and quantizers for accurate LLM quantization, while aligning bit-width partition to groups for compact memory usage and fast integer inference. Specifically, the proposed SliM-LLM mainly relies on two novel techniques: (1) Salience-Determined Bit Allocation utilizes the clustering characteristics of salience distribution to allocate the bit-widths of each group, increasing the accuracy of quantized LLMs and maintaining the inference efficiency; (2) Salience-Weighted Quantizer Calibration optimizes the parameters of the quantizer by considering the element-wise salience within the group, balancing the maintenance of salient information and minimization of errors. Comprehensive experiments show that SliM-LLM significantly improves the accuracy of LLMs at ultra-low bits, e.g., 2-bit LLaMA-7B achieves a 5.5-times memory-saving than original model on NVIDIA A800 GPUs, and 48% decrease of perplexity compared to the state-of-the-art gradient-free PTQ method. Moreover, SliM-LLM+, which is integrated from the extension of SliM-LLM with gradient-based quantizers, further reduces perplexity by 35.1%.
5/27/2024
LLM-QBench: A Benchmark Towards the Best Practice for Post-training Quantization of Large Language Models
Ruihao Gong, Yang Yong, Shiqiao Gu, Yushi Huang, Yunchen Zhang, Xianglong Liu, Dacheng Tao
0
0
Recent advancements in large language models (LLMs) are propelling us toward artificial general intelligence, thanks to their remarkable emergent abilities and reasoning capabilities. However, the substantial computational and memory requirements of LLMs limit their widespread adoption. Quan- tization, a key compression technique, offers a viable solution to mitigate these demands by compressing and accelerating LLMs, albeit with poten- tial risks to model accuracy. Numerous studies have aimed to minimize the accuracy loss associated with quantization. However, the quantization configurations in these studies vary and may not be optimized for hard- ware compatibility. In this paper, we focus on identifying the most effective practices for quantizing LLMs, with the goal of balancing performance with computational efficiency. For a fair analysis, we develop a quantization toolkit LLMC, and design four crucial principles considering the inference efficiency, quantized accuracy, calibration cost, and modularization. By benchmarking on various models and datasets with over 500 experiments, three takeaways corresponding to calibration data, quantization algorithm, and quantization schemes are derived. Finally, a best practice of LLM PTQ pipeline is constructed. All the benchmark results and the toolkit can be found at https://github.com/ModelTC/llmc.
5/13/2024

CLAQ: Pushing the Limits of Low-Bit Post-Training Quantization for LLMs
Haoyu Wang, Bei Liu, Hang Shao, Bo Xiao, Ke Zeng, Guanglu Wan, Yanmin Qian
0
0
Parameter quantization for Large Language Models (LLMs) has attracted increasing attentions recently in reducing memory costs and improving computational efficiency. Early approaches have been widely adopted. However, the existing methods suffer from poor performance in low-bit (such as 2 to 3 bits) scenarios. In this paper, we present a novel and effective Column-Level Adaptive weight Quantization (CLAQ) framework by introducing three different types of adaptive strategies for LLM quantization. Firstly, a K-Means clustering based algorithm is proposed that allows dynamic generation of quantization centroids for each column of a parameter matrix. Secondly, we design an outlier-guided adaptive precision search strategy which can dynamically assign varying bit-widths to different columns. Finally, a dynamic outlier reservation scheme is developed to retain some parameters in their original float point precision, in trade off of boosted model performance. Experiments on various mainstream open source LLMs including LLaMA-1, LLaMA-2 and Yi demonstrate that our methods achieve the state-of-the-art results across different bit settings, especially in extremely low-bit scenarios. Code is available at https://github.com/fayuge/CLAQ.
6/4/2024
💬
QLLM: Accurate and Efficient Low-Bitwidth Quantization for Large Language Models
Jing Liu, Ruihao Gong, Xiuying Wei, Zhiwei Dong, Jianfei Cai, Bohan Zhuang
0
0
Large Language Models (LLMs) excel in NLP, but their demands hinder their widespread deployment. While Quantization-Aware Training (QAT) offers a solution, its extensive training costs make Post-Training Quantization (PTQ) a more practical approach for LLMs. In existing studies, activation outliers in particular channels are identified as the bottleneck to PTQ accuracy. They propose to transform the magnitudes from activations to weights, which however offers limited alleviation or suffers from unstable gradients, resulting in a severe performance drop at low-bitwidth. In this paper, we propose QLLM, an accurate and efficient low-bitwidth PTQ method designed for LLMs. QLLM introduces an adaptive channel reassembly technique that reallocates the magnitude of outliers to other channels, thereby mitigating their impact on the quantization range. This is achieved by channel disassembly and channel assembly, which first breaks down the outlier channels into several sub-channels to ensure a more balanced distribution of activation magnitudes. Then similar channels are merged to maintain the original channel number for efficiency. Additionally, an adaptive strategy is designed to autonomously determine the optimal number of sub-channels for channel disassembly. To further compensate for the performance loss caused by quantization, we propose an efficient tuning method that only learns a small number of low-rank weights while freezing the pre-trained quantized model. After training, these low-rank parameters can be fused into the frozen weights without affecting inference. Extensive experiments on LLaMA-1 and LLaMA-2 show that QLLM can obtain accurate quantized models efficiently. For example, QLLM quantizes the 4-bit LLaMA-2-70B within 10 hours on a single A100-80G GPU, outperforming the previous state-of-the-art method by 7.89% on the average accuracy across five zero-shot tasks.
4/9/2024