Block-Diagonal Guided DBSCAN Clustering
2404.01341
0
0

Abstract
Cluster analysis plays a crucial role in database mining, and one of the most widely used algorithms in this field is DBSCAN. However, DBSCAN has several limitations, such as difficulty in handling high-dimensional large-scale data, sensitivity to input parameters, and lack of robustness in producing clustering results. This paper introduces an improved version of DBSCAN that leverages the block-diagonal property of the similarity graph to guide the clustering procedure of DBSCAN. The key idea is to construct a graph that measures the similarity between high-dimensional large-scale data points and has the potential to be transformed into a block-diagonal form through an unknown permutation, followed by a cluster-ordering procedure to generate the desired permutation. The clustering structure can be easily determined by identifying the diagonal blocks in the permuted graph. We propose a gradient descent-based method to solve the proposed problem. Additionally, we develop a DBSCAN-based points traversal algorithm that identifies clusters with high densities in the graph and generates an augmented ordering of clusters. The block-diagonal structure of the graph is then achieved through permutation based on the traversal order, providing a flexible foundation for both automatic and interactive cluster analysis. We introduce a split-and-refine algorithm to automatically search for all diagonal blocks in the permuted graph with theoretically optimal guarantees under specific cases. We extensively evaluate our proposed approach on twelve challenging real-world benchmark clustering datasets and demonstrate its superior performance compared to the state-of-the-art clustering method on every dataset.
Create account to get full access
Overview
- This paper presents a new approach called Block-Diagonal Guided DBSCAN (BDG-DBSCAN) for clustering data with a block-diagonal structure.
- The key idea is to leverage the block-diagonal property of the data's self-representation matrix to guide the clustering process and improve the performance of the widely-used DBSCAN algorithm.
- The method involves identifying diagonal blocks in the self-representation matrix, which correspond to clusters in the data, and then using this information to inform the DBSCAN clustering.
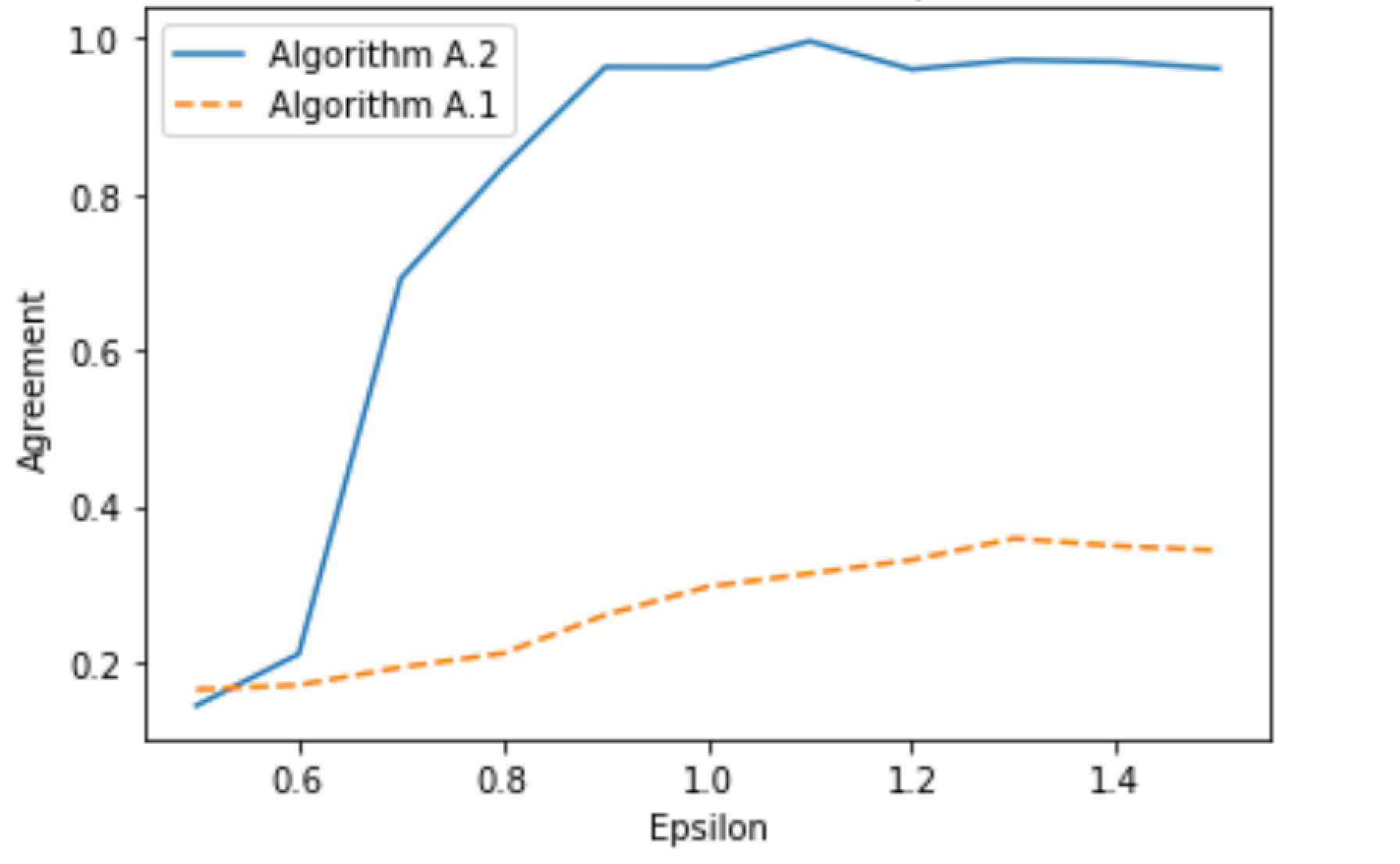
- Experiments on synthetic and real-world datasets show that BDG-DBSCAN outperforms standard DBSCAN and other popular clustering methods.
Plain English Explanation
Clustering is a common machine learning task where the goal is to group similar data points together. One popular clustering algorithm is called DBSCAN, which groups data points based on their density. However, DBSCAN can struggle when the data has a block-diagonal structure, where the data naturally separates into distinct clusters.
The key insight behind this new approach is that you can use information about the block-diagonal structure of the data to guide the DBSCAN clustering process and improve its performance. The method first computes a self-representation matrix, which captures the relationships between data points. This matrix will have a block-diagonal structure if the data naturally separates into distinct clusters.
The algorithm then identifies the diagonal blocks in this matrix, which correspond to the clusters in the data. It then uses this information to inform the DBSCAN clustering, allowing it to better detect the cluster boundaries and improve the overall clustering results.
The experiments show that this new Block-Diagonal Guided DBSCAN approach outperforms standard DBSCAN and other popular clustering methods, especially on datasets with a clear block-diagonal structure. This is an important advance because many real-world datasets, such as those found in social networks or biology, often exhibit this block-diagonal property.
Technical Explanation
The core technical innovation of this paper is the Block-Diagonal Guided DBSCAN (BDG-DBSCAN) algorithm, which leverages the block-diagonal structure of the data's self-representation matrix to improve the performance of the DBSCAN clustering algorithm.
The first step is to compute the self-representation matrix, which captures the relationships between data points. This matrix will have a block-diagonal structure if the data naturally separates into distinct clusters. The algorithm then identifies the diagonal blocks in this matrix, which correspond to the clusters in the data.
Next, the method uses this block-diagonal information to guide the DBSCAN clustering process. Specifically, it initializes the DBSCAN algorithm with the diagonal blocks as the initial clusters. It then iteratively merges clusters that are within a certain distance threshold, guided by the block-diagonal structure. This allows the algorithm to better detect the true cluster boundaries and improve the overall clustering performance.
The paper evaluates BDG-DBSCAN on both synthetic and real-world datasets, comparing it to standard DBSCAN and other popular clustering methods. The results show that BDG-DBSCAN consistently outperforms these baselines, especially on datasets with a clear block-diagonal structure. This highlights the importance of leveraging the underlying structure of the data to improve clustering algorithms.
Critical Analysis
The authors thoroughly evaluate BDG-DBSCAN and demonstrate its effectiveness, but there are a few potential limitations and areas for further research:
-
The method relies on accurately identifying the diagonal blocks in the self-representation matrix, which can be challenging for noisy or complex datasets. The authors acknowledge this and suggest exploring more robust block detection methods.
-
The experiments only consider datasets with a clear block-diagonal structure. It would be useful to see how BDG-DBSCAN performs on more general datasets without this property, and whether it can still provide improvements over standard DBSCAN.
-
The paper does not discuss the computational complexity of the BDG-DBSCAN algorithm compared to standard DBSCAN. As the additional block detection step adds overhead, it would be important to understand the trade-offs in terms of runtime and scalability.
-
While the experiments show promising results, the paper does not provide much insight into the practical significance or real-world applications of this approach. Further research could explore how BDG-DBSCAN performs on large-scale, real-world datasets and the potential impact on specific domains.
Overall, this paper presents a novel and interesting method for improving clustering performance by leveraging the underlying block-diagonal structure of the data. The technical approach is well-designed and the experimental results are convincing, but there are still opportunities to further explore the limitations and broader implications of this work.
Conclusion
This paper introduces a new clustering algorithm called Block-Diagonal Guided DBSCAN (BDG-DBSCAN) that leverages the block-diagonal structure of the data's self-representation matrix to improve the performance of the widely-used DBSCAN algorithm. By identifying the diagonal blocks in the self-representation matrix and using this information to guide the DBSCAN clustering process, BDG-DBSCAN is able to better detect the true cluster boundaries and outperform standard DBSCAN and other popular clustering methods.
The key significance of this work is that many real-world datasets, such as those found in social networks or biology, often exhibit a block-diagonal structure. By designing algorithms that can effectively leverage this underlying structure, we can develop more powerful and accurate clustering techniques. While the current paper has some limitations, it represents an important step forward in this direction and opens up promising avenues for future research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
LINSCAN -- A Linearity Based Clustering Algorithm
Andrew Dennehy, Xiaoyu Zou, Shabnam J. Semnani, Yuri Fialko, Alexander Cloninger
0
0
DBSCAN and OPTICS are powerful algorithms for identifying clusters of points in domains where few assumptions can be made about the structure of the data. In this paper, we leverage these strengths and introduce a new algorithm, LINSCAN, designed to seek lineated clusters that are difficult to find and isolate with existing methods. In particular, by embedding points as normal distributions approximating their local neighborhoods and leveraging a distance function derived from the Kullback Leibler Divergence, LINSCAN can detect and distinguish lineated clusters that are spatially close but have orthogonal covariances. We demonstrate how LINSCAN can be applied to seismic data to identify active faults, including intersecting faults, and determine their orientation. Finally, we discuss the properties a generalization of DBSCAN and OPTICS must have in order to retain the stability benefits of these algorithms.
6/27/2024
🧠
Gap-Free Clustering: Sensitivity and Robustness of SDP
Matthew Zurek, Yudong Chen
0
0
We study graph clustering in the Stochastic Block Model (SBM) in the presence of both large clusters and small, unrecoverable clusters. Previous convex relaxation approaches achieving exact recovery do not allow any small clusters of size $o(sqrt{n})$, or require a size gap between the smallest recovered cluster and the largest non-recovered cluster. We provide an algorithm based on semidefinite programming (SDP) which removes these requirements and provably recovers large clusters regardless of the remaining cluster sizes. Mid-sized clusters pose unique challenges to the analysis, since their proximity to the recovery threshold makes them highly sensitive to small noise perturbations and precludes a closed-form candidate solution. We develop novel techniques, including a leave-one-out-style argument which controls the correlation between SDP solutions and noise vectors even when the removal of one row of noise can drastically change the SDP solution. We also develop improved eigenvalue perturbation bounds of potential independent interest. Our results are robust to certain semirandom settings that are challenging for alternative algorithms. Using our gap-free clustering procedure, we obtain efficient algorithms for the problem of clustering with a faulty oracle with superior query complexities, notably achieving $o(n^2)$ sample complexity even in the presence of a large number of small clusters. Our gap-free clustering procedure also leads to improved algorithms for recursive clustering.
6/19/2024
🔗
Spectral clustering in the Gaussian mixture block model
Shuangping Li, Tselil Schramm
0
0
Gaussian mixture block models are distributions over graphs that strive to model modern networks: to generate a graph from such a model, we associate each vertex $i$ with a latent feature vector $u_i in mathbb{R}^d$ sampled from a mixture of Gaussians, and we add edge $(i,j)$ if and only if the feature vectors are sufficiently similar, in that $langle u_i,u_j rangle ge tau$ for a pre-specified threshold $tau$. The different components of the Gaussian mixture represent the fact that there may be different types of nodes with different distributions over features -- for example, in a social network each component represents the different attributes of a distinct community. Natural algorithmic tasks associated with these networks are embedding (recovering the latent feature vectors) and clustering (grouping nodes by their mixture component). In this paper we initiate the study of clustering and embedding graphs sampled from high-dimensional Gaussian mixture block models, where the dimension of the latent feature vectors $dto infty$ as the size of the network $n to infty$. This high-dimensional setting is most appropriate in the context of modern networks, in which we think of the latent feature space as being high-dimensional. We analyze the performance of canonical spectral clustering and embedding algorithms for such graphs in the case of 2-component spherical Gaussian mixtures, and begin to sketch out the information-computation landscape for clustering and embedding in these models.
4/12/2024
Multi-View Stochastic Block Models
Vincent Cohen-Addad, Tommaso d'Orsi, Silvio Lattanzi, Rajai Nasser
0
0
Graph clustering is a central topic in unsupervised learning with a multitude of practical applications. In recent years, multi-view graph clustering has gained a lot of attention for its applicability to real-world instances where one has access to multiple data sources. In this paper we formalize a new family of models, called textit{multi-view stochastic block models} that captures this setting. For this model, we first study efficient algorithms that naively work on the union of multiple graphs. Then, we introduce a new efficient algorithm that provably outperforms previous approaches by analyzing the structure of each graph separately. Furthermore, we complement our results with an information-theoretic lower bound studying the limits of what can be done in this model. Finally, we corroborate our results with experimental evaluations.
6/10/2024