BRAIxDet: Learning to Detect Malignant Breast Lesion with Incomplete Annotations
2301.13418
0
0
🤿
Abstract
Methods to detect malignant lesions from screening mammograms are usually trained with fully annotated datasets, where images are labelled with the localisation and classification of cancerous lesions. However, real-world screening mammogram datasets commonly have a subset that is fully annotated and another subset that is weakly annotated with just the global classification (i.e., without lesion localisation). Given the large size of such datasets, researchers usually face a dilemma with the weakly annotated subset: to not use it or to fully annotate it. The first option will reduce detection accuracy because it does not use the whole dataset, and the second option is too expensive given that the annotation needs to be done by expert radiologists. In this paper, we propose a middle-ground solution for the dilemma, which is to formulate the training as a weakly- and semi-supervised learning problem that we refer to as malignant breast lesion detection with incomplete annotations. To address this problem, our new method comprises two stages, namely: 1) pre-training a multi-view mammogram classifier with weak supervision from the whole dataset, and 2) extending the trained classifier to become a multi-view detector that is trained with semi-supervised student-teacher learning, where the training set contains fully and weakly-annotated mammograms. We provide extensive detection results on two real-world screening mammogram datasets containing incomplete annotations, and show that our proposed approach achieves state-of-the-art results in the detection of malignant breast lesions with incomplete annotations.
Create account to get full access
Overview
- Detecting malignant breast lesions in screening mammograms is important, but existing methods require fully annotated datasets where each image is labeled with the location and classification of any cancerous lesions.
- In real-world screening datasets, there is often a mix of fully annotated images and weakly annotated images with only global classification (no lesion location).
- Researchers face a dilemma: either discard the weakly annotated subset, reducing detection accuracy, or fully annotate the entire dataset, which is expensive.
Plain English Explanation
Screening mammograms are x-ray images used to detect breast cancer early. Doctors need to be able to automatically identify any suspicious lesions or growths in these mammograms. To train the computer systems to do this, researchers typically use datasets where each mammogram image is carefully labeled by experts - the location of any cancerous spots is identified, as well as whether the overall image shows a malignant (cancerous) or benign (non-cancerous) case.
However, in real-world mammogram screening programs, it's common for there to be a mix of fully labeled images and images that are only weakly labeled. The weakly labeled images might just indicate whether the overall case is cancerous or not, without specifying exactly where the cancerous lesions are located.
This creates a dilemma for researchers. If they only use the fully labeled subset, they won't have enough data to train their detection systems effectively. But getting the entire dataset fully labeled by expert radiologists would be extremely time-consuming and expensive. The researchers in this paper propose a middle-ground solution - a new training approach that can leverage both the fully labeled and weakly labeled mammogram images to improve cancer detection accuracy.
Technical Explanation
The key elements of the paper's technical approach are:
-
Pre-training a Classifier: The researchers first pre-train a multi-view mammogram classifier using the entire dataset, including the weakly annotated subset. This allows the model to learn general visual patterns associated with malignant lesions, even without precise location information.
-
Semi-Supervised Detection: The pre-trained classifier is then extended into a multi-view lesion detection model, which is further trained in a semi-supervised manner. This stage uses both the fully annotated subset (for direct lesion detection learning) and the weakly annotated subset (with a "teacher-student" knowledge transfer approach).
The researchers evaluate their approach on two real-world screening mammogram datasets with incomplete annotations. They show that their method achieves state-of-the-art performance in detecting malignant breast lesions, outperforming alternatives that either discard the weakly annotated data or require expensive full annotation of the entire dataset.
Critical Analysis
The paper provides a well-designed and thorough evaluation of their proposed approach, testing it on multiple real-world datasets. However, some potential limitations and areas for further research include:
- It's not clear how the performance of the detection model compares to expert human radiologists, which would be an important real-world benchmark.
- The datasets used still had a substantial fully annotated subset - it's uncertain how the approach would scale if the fully annotated data was much more limited.
- The paper does not explore the potential biases or fairness implications of training on datasets with incomplete annotations, which could be an important consideration.
Overall, the researchers present a compelling solution to the common challenge of working with partially annotated medical imaging datasets. Their work demonstrates the value of developing flexible, semi-supervised learning techniques to maximize the utility of available data.
Conclusion
This paper introduces a novel approach to train breast cancer detection models using a mix of fully and weakly annotated mammogram images. By leveraging both types of data through a two-stage training process, the researchers are able to achieve state-of-the-art performance without the high cost of fully annotating entire large-scale datasets.
This work highlights the importance of developing flexible machine learning techniques that can adapt to the realities of real-world medical data, which is often incomplete or imperfect. The ability to extract maximum value from partially annotated datasets has significant implications for accelerating the development of AI-powered medical imaging tools that can assist radiologists and improve patient outcomes.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
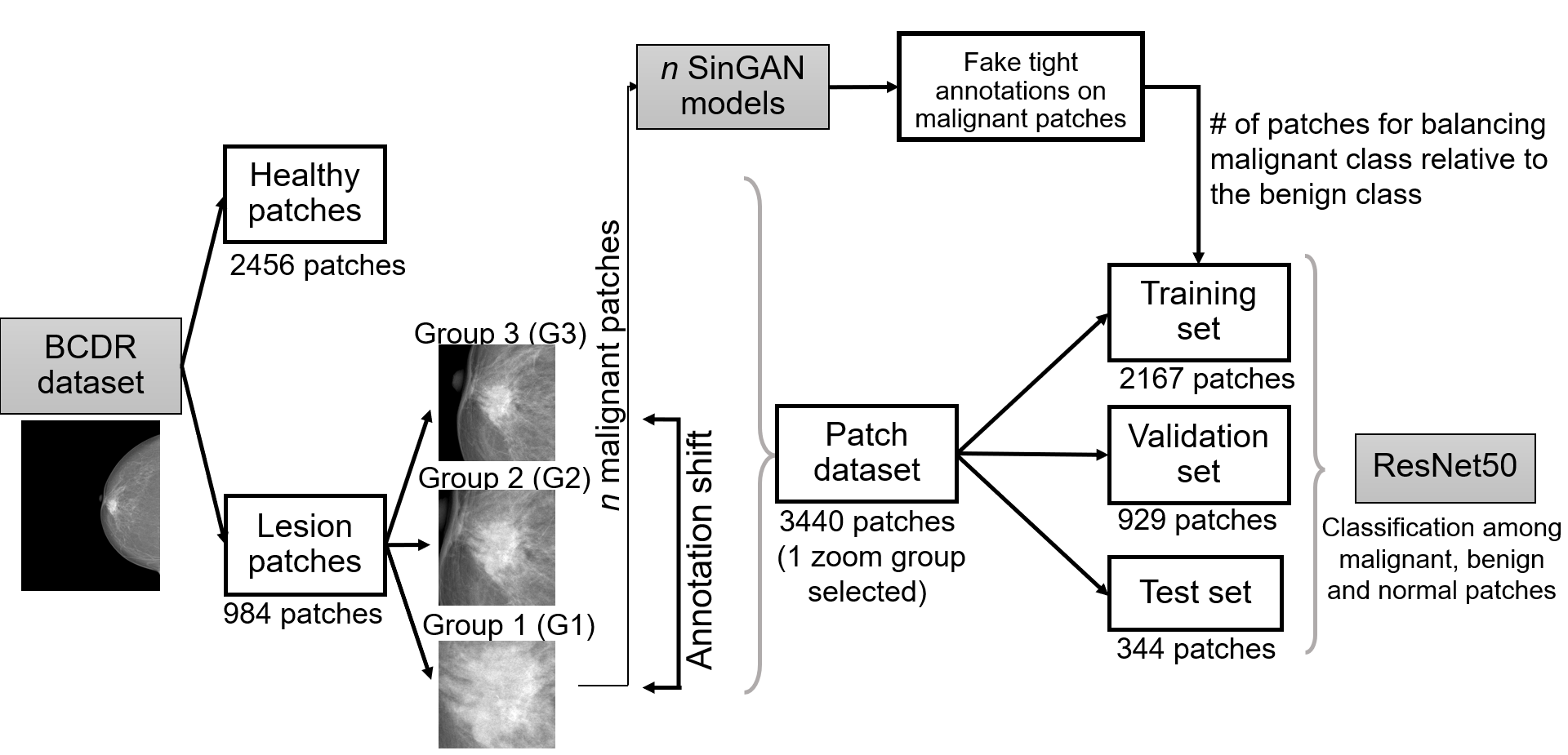
Mitigating annotation shift in cancer classification using single image generative models
Marta Buetas Arcas, Richard Osuala, Karim Lekadir, Oliver D'iaz
0
0
Artificial Intelligence (AI) has emerged as a valuable tool for assisting radiologists in breast cancer detection and diagnosis. However, the success of AI applications in this domain is restricted by the quantity and quality of available data, posing challenges due to limited and costly data annotation procedures that often lead to annotation shifts. This study simulates, analyses and mitigates annotation shifts in cancer classification in the breast mammography domain. First, a high-accuracy cancer risk prediction model is developed, which effectively distinguishes benign from malignant lesions. Next, model performance is used to quantify the impact of annotation shift. We uncover a substantial impact of annotation shift on multiclass classification performance particularly for malignant lesions. We thus propose a training data augmentation approach based on single-image generative models for the affected class, requiring as few as four in-domain annotations to considerably mitigate annotation shift, while also addressing dataset imbalance. Lastly, we further increase performance by proposing and validating an ensemble architecture based on multiple models trained under different data augmentation regimes. Our study offers key insights into annotation shift in deep learning breast cancer classification and explores the potential of single-image generative models to overcome domain shift challenges.
5/31/2024
🔎
Boosting Medical Image-based Cancer Detection via Text-guided Supervision from Reports
Guangyu Guo, Jiawen Yao, Yingda Xia, Tony C. W. Mok, Zhilin Zheng, Junwei Han, Le Lu, Dingwen Zhang, Jian Zhou, Ling Zhang
0
0
The absence of adequately sufficient expert-level tumor annotations hinders the effectiveness of supervised learning based opportunistic cancer screening on medical imaging. Clinical reports (that are rich in descriptive textual details) can offer a free lunch'' supervision information and provide tumor location as a type of weak label to cope with screening tasks, thus saving human labeling workloads, if properly leveraged. However, predicting cancer only using such weak labels can be very changeling since tumors are usually presented in small anatomical regions compared to the whole 3D medical scans. Weakly semi-supervised learning (WSSL) utilizes a limited set of voxel-level tumor annotations and incorporates alongside a substantial number of medical images that have only off-the-shelf clinical reports, which may strike a good balance between minimizing expert annotation workload and optimizing screening efficacy. In this paper, we propose a novel text-guided learning method to achieve highly accurate cancer detection results. Through integrating diagnostic and tumor location text prompts into the text encoder of a vision-language model (VLM), optimization of weakly supervised learning can be effectively performed in the latent space of VLM, thereby enhancing the stability of training. Our approach can leverage clinical knowledge by large-scale pre-trained VLM to enhance generalization ability, and produce reliable pseudo tumor masks to improve cancer detection. Our extensive quantitative experimental results on a large-scale cancer dataset, including 1,651 unique patients, validate that our approach can reduce human annotation efforts by at least 70% while maintaining comparable cancer detection accuracy to competing fully supervised methods (AUC value 0.961 versus 0.966).
5/24/2024

Enhancing AI Diagnostics: Autonomous Lesion Masking via Semi-Supervised Deep Learning
Ting-Ruen Wei, Michele Hell, Dang Bich Thuy Le, Aren Vierra, Ran Pang, Mahesh Patel, Young Kang, Yuling Yan
0
0
This study presents an unsupervised domain adaptation method aimed at autonomously generating image masks outlining regions of interest (ROIs) for differentiating breast lesions in breast ultrasound (US) imaging. Our semi-supervised learning approach utilizes a primitive model trained on a small public breast US dataset with true annotations. This model is then iteratively refined for the domain adaptation task, generating pseudo-masks for our private, unannotated breast US dataset. The dataset, twice the size of the public one, exhibits considerable variability in image acquisition perspectives and demographic representation, posing a domain-shift challenge. Unlike typical domain adversarial training, we employ downstream classification outcomes as a benchmark to guide the updating of pseudo-masks in subsequent iterations. We found the classification precision to be highly correlated with the completeness of the generated ROIs, which promotes the explainability of the deep learning classification model. Preliminary findings demonstrate the efficacy and reliability of this approach in streamlining the ROI annotation process, thereby enhancing the classification and localization of breast lesions for more precise and interpretable diagnoses.
4/22/2024
🏷️
Classification of Breast Cancer Histopathology Images using a Modified Supervised Contrastive Learning Method
Matina Mahdizadeh Sani, Ali Royat, Mahdieh Soleymani Baghshah
0
0
Deep neural networks have reached remarkable achievements in medical image processing tasks, specifically classifying and detecting various diseases. However, when confronted with limited data, these networks face a critical vulnerability, often succumbing to overfitting by excessively memorizing the limited information available. This work addresses the challenge mentioned above by improving the supervised contrastive learning method to reduce the impact of false positives. Unlike most existing methods that rely predominantly on fully supervised learning, our approach leverages the advantages of self-supervised learning in conjunction with employing the available labeled data. We evaluate our method on the BreakHis dataset, which consists of breast cancer histopathology images, and demonstrate an increase in classification accuracy by 1.45% at the image level and 1.42% at the patient level compared to the state-of-the-art method. This improvement corresponds to 93.63% absolute accuracy, highlighting our approach's effectiveness in leveraging data properties to learn more appropriate representation space.
5/7/2024