Can multiple-choice questions really be useful in detecting the abilities of LLMs?
2403.17752
0
0
Abstract
Multiple-choice questions (MCQs) are widely used in the evaluation of large language models (LLMs) due to their simplicity and efficiency. However, there are concerns about whether MCQs can truly measure LLM's capabilities, particularly in knowledge-intensive scenarios where long-form generation (LFG) answers are required. The misalignment between the task and the evaluation method demands a thoughtful analysis of MCQ's efficacy, which we undertake in this paper by evaluating nine LLMs on four question-answering (QA) datasets in two languages: Chinese and English. We identify a significant issue: LLMs exhibit an order sensitivity in bilingual MCQs, favoring answers located at specific positions, i.e., the first position. We further quantify the gap between MCQs and long-form generation questions (LFGQs) by comparing their direct outputs, token logits, and embeddings. Our results reveal a relatively low correlation between answers from MCQs and LFGQs for identical questions. Additionally, we propose two methods to quantify the consistency and confidence of LLMs' output, which can be generalized to other QA evaluation benchmarks. Notably, our analysis challenges the idea that the higher the consistency, the greater the accuracy. We also find MCQs to be less reliable than LFGQs in terms of expected calibration error. Finally, the misalignment between MCQs and LFGQs is not only reflected in the evaluation performance but also in the embedding space. Our code and models can be accessed at https://github.com/Meetyou-AI-Lab/Can-MC-Evaluate-LLMs.
Create account to get full access
Introduction
This paper explores the effectiveness of using multiple-choice questions to assess the capabilities of large language models (LLMs). Multiple-choice questions are a common way to evaluate human knowledge, but their utility for testing the abilities of advanced AI systems is less clear. The researchers conducted experiments to understand how well multiple-choice questions can capture the nuanced understanding of LLMs.
Experimental Details
Test Set Generation
The researchers generated a diverse set of multiple-choice questions across various domains, including math-multiple-choice-question-generation-via-human, multiple-choice-questions-are-efficient-robust-llm, and exploring-automated-distractor-generation-math-multiple-choice. They also used existing datasets like unibucllm-harnessing-llms-automated-prediction-item-difficulty to evaluate the models.
Model Evaluation
The researchers tested several large language models, including GPT-3, on the multiple-choice question sets. They assessed the models' performance in terms of accuracy, as well as their ability to provide justifications for their answers.
Plain English Explanation
The key idea of this paper is to investigate how well multiple-choice questions can be used to assess the capabilities of advanced AI language models. Multiple-choice tests are commonly used to evaluate human knowledge, but it's not clear if they are well-suited for testing the more nuanced understanding of LLMs.
The researchers created a diverse set of multiple-choice questions across various topics, from math to general knowledge. They then tested several prominent language models, like GPT-3, on these question sets. The goal was to see how accurately the models could answer the questions and whether they could provide meaningful justifications for their answers.
The findings suggest that multiple-choice questions can be a useful tool for evaluating LLMs, but they have some limitations. The models were generally able to perform well on the questions, but they sometimes struggled to articulate their reasoning in a clear and coherent way. This highlights the need to go beyond simple multiple-choice tests and explore more sophisticated ways of assessing the depth of understanding in these advanced AI systems.
Technical Explanation
The researchers generated a diverse set of multiple-choice questions from various sources, including existing datasets and custom-built question sets. They evaluated the performance of several prominent language models, such as GPT-3, on these question sets.
The key metrics used to assess the models' capabilities were accuracy (how often they selected the correct answer) and their ability to provide justifications for their answers. The researchers found that the language models could generally perform well on the multiple-choice questions, achieving high accuracy scores.
However, the models sometimes struggled to articulate their reasoning in a clear and coherent way. This suggests that while multiple-choice questions can be a useful tool for evaluating LLMs, they may not fully capture the depth of understanding that these advanced AI systems possess.
Critical Analysis
The paper presents a valuable investigation into the use of multiple-choice questions for assessing LLMs. However, the researchers acknowledge that this approach has some limitations. Multiple-choice questions, by their nature, provide a limited set of options for the model to choose from, which may not fully test the model's understanding of the underlying concepts.
Additionally, the researchers note that the models' ability to provide justifications for their answers was not always satisfactory. This highlights the need to explore more sophisticated evaluation methods that go beyond simple multiple-choice tests and can better capture the nuanced reasoning of these advanced AI systems.
Future research in this area could explore the use of open-ended questions, task-based assessments, or other more complex evaluation frameworks to gain a more comprehensive understanding of the capabilities and limitations of large language models.
Conclusion
This paper provides an important exploration of the potential and limitations of using multiple-choice questions to assess the abilities of large language models. The researchers found that while LLMs can generally perform well on such tests, the multiple-choice format may not fully capture the depth of their understanding.
The findings suggest that a more holistic approach to evaluating LLMs is needed, one that goes beyond simple multiple-choice tests and explores a range of assessment methods. This is an important area of research that will help us better understand the true capabilities and limitations of these advanced AI systems, and how they can be most effectively deployed to benefit society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Beyond the Answers: Reviewing the Rationality of Multiple Choice Question Answering for the Evaluation of Large Language Models
Haochun Wang, Sendong Zhao, Zewen Qiang, Nuwa Xi, Bing Qin, Ting Liu
0
0
In the field of natural language processing (NLP), Large Language Models (LLMs) have precipitated a paradigm shift, markedly enhancing performance in natural language generation tasks. Despite these advancements, the comprehensive evaluation of LLMs remains an inevitable challenge for the community. Recently, the utilization of Multiple Choice Question Answering (MCQA) as a benchmark for LLMs has gained considerable traction. This study first investigates the limitations of MCQA as an evaluation method for LLMs and then analyzes the fundamental reason for the limitations of MCQA, that while LLMs may select the correct answers, it is possible that they also recognize other wrong options as correct. Finally, we propose a dataset augmenting method for Multiple-Choice Questions (MCQs), MCQA+, that can more accurately reflect the performance of the model, which underscores the need for more robust evaluation mechanisms in assessing the performance of LLMs.
5/31/2024
Multiple Choice Questions and Large Languages Models: A Case Study with Fictional Medical Data
Maxime Griot, Jean Vanderdonckt, Demet Yuksel, Coralie Hemptinne
0
0
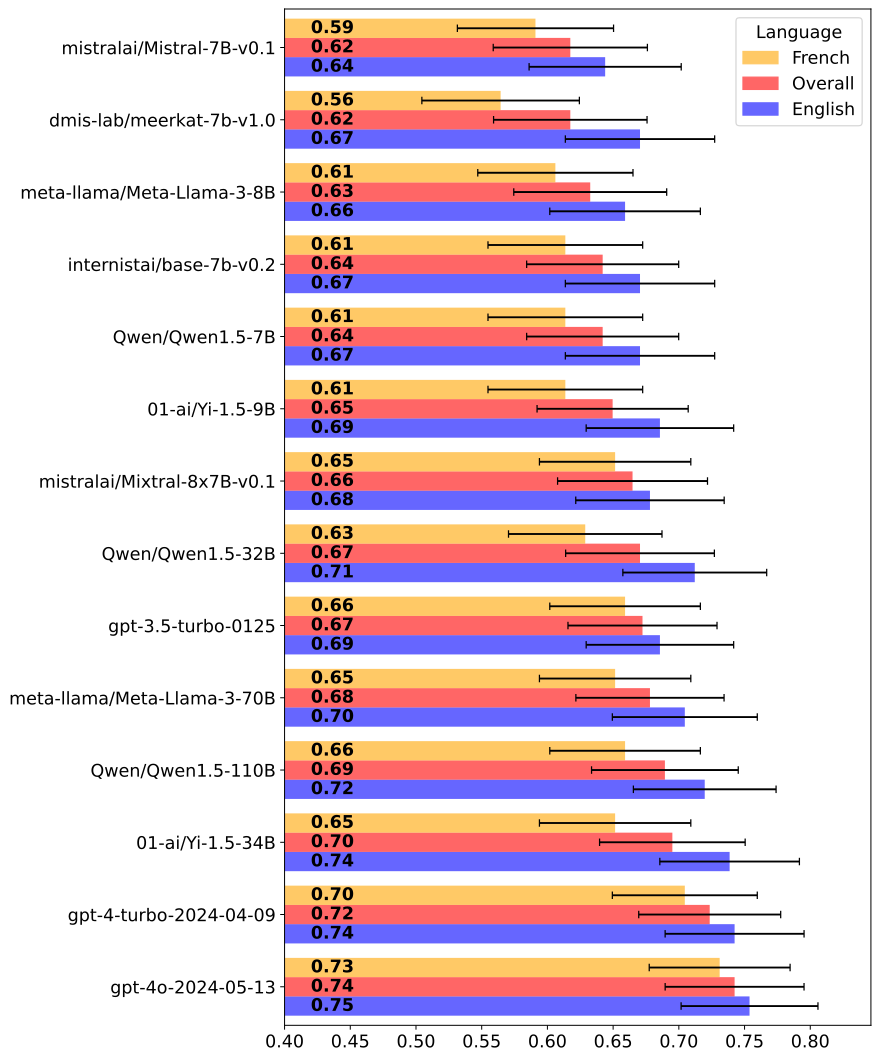
Large Language Models (LLMs) like ChatGPT demonstrate significant potential in the medical field, often evaluated using multiple-choice questions (MCQs) similar to those found on the USMLE. Despite their prevalence in medical education, MCQs have limitations that might be exacerbated when assessing LLMs. To evaluate the effectiveness of MCQs in assessing the performance of LLMs, we developed a fictional medical benchmark focused on a non-existent gland, the Glianorex. This approach allowed us to isolate the knowledge of the LLM from its test-taking abilities. We used GPT-4 to generate a comprehensive textbook on the Glianorex in both English and French and developed corresponding multiple-choice questions in both languages. We evaluated various open-source, proprietary, and domain-specific LLMs using these questions in a zero-shot setting. The models achieved average scores around 67%, with minor performance differences between larger and smaller models. Performance was slightly higher in English than in French. Fine-tuned medical models showed some improvement over their base versions in English but not in French. The uniformly high performance across models suggests that traditional MCQ-based benchmarks may not accurately measure LLMs' clinical knowledge and reasoning abilities, instead highlighting their pattern recognition skills. This study underscores the need for more robust evaluation methods to better assess the true capabilities of LLMs in medical contexts.
6/5/2024

Open-LLM-Leaderboard: From Multi-choice to Open-style Questions for LLMs Evaluation, Benchmark, and Arena
Aidar Myrzakhan, Sondos Mahmoud Bsharat, Zhiqiang Shen
0
0
Multiple-choice questions (MCQ) are frequently used to assess large language models (LLMs). Typically, an LLM is given a question and selects the answer deemed most probable after adjustments for factors like length. Unfortunately, LLMs may inherently favor certain answer choice IDs, such as A/B/C/D, due to inherent biases of priori unbalanced probabilities, influencing the prediction of answers based on these IDs. Previous research has introduced methods to reduce this ''selection bias'' by simply permutating options on a few test samples and applying to new ones. Another problem of MCQ is the lottery ticket choice by ''random guessing''. The LLM does not learn particular knowledge, but the option is guessed correctly. This situation is especially serious for those small-scale LLMs. To address them, a more thorough approach involves shifting from MCQ to open-style questions, which can fundamentally eliminate selection bias and random guessing issues. However, transitioning causes its own set of challenges in (1) identifying suitable open-style questions and (2) validating the correctness of LLM open-style responses against human-annotated ground-truths. This work aims to tackle these significant difficulties, and establish a new LLM evaluation benchmark through entirely open-style questions. Consequently, we introduce the Open-LLM-Leaderboard to track various LLMs' performance and reflect true capability of them, such as GPT-4o/4/3.5, Claude 3, Gemini, etc. Our code and dataset are available at https://github.com/VILA-Lab/Open-LLM-Leaderboard.
6/12/2024
Artifacts or Abduction: How Do LLMs Answer Multiple-Choice Questions Without the Question?
Nishant Balepur, Abhilasha Ravichander, Rachel Rudinger
0
0
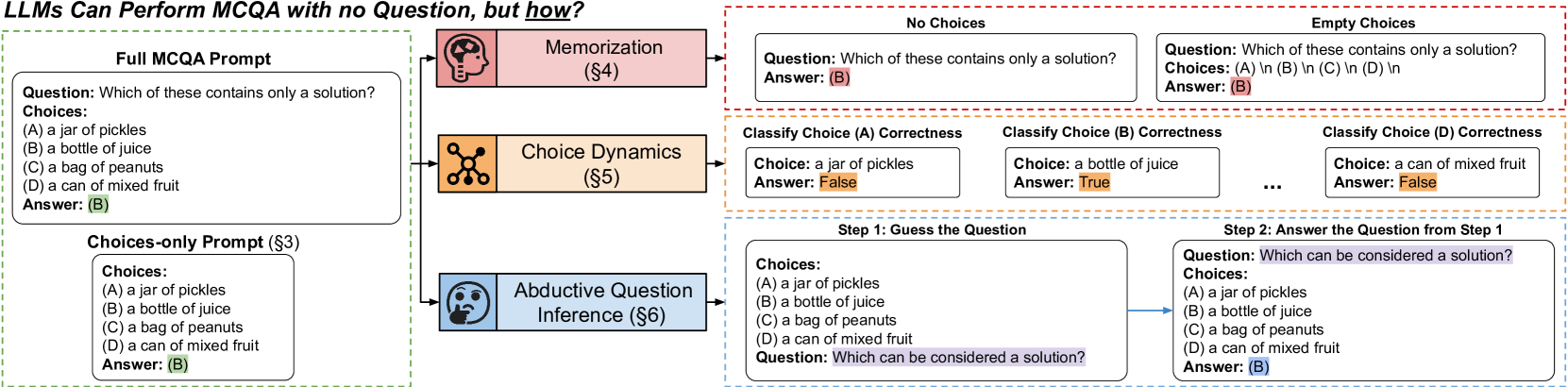
Multiple-choice question answering (MCQA) is often used to evaluate large language models (LLMs). To see if MCQA assesses LLMs as intended, we probe if LLMs can perform MCQA with choices-only prompts, where models must select the correct answer only from the choices. In three MCQA datasets and four LLMs, this prompt bests a majority baseline in 11/12 cases, with up to 0.33 accuracy gain. To help explain this behavior, we conduct an in-depth, black-box analysis on memorization, choice dynamics, and question inference. Our key findings are threefold. First, we find no evidence that the choices-only accuracy stems from memorization alone. Second, priors over individual choices do not fully explain choices-only accuracy, hinting that LLMs use the group dynamics of choices. Third, LLMs have some ability to infer a relevant question from choices, and surprisingly can sometimes even match the original question. Inferring the original question is an impressive reasoning strategy, but it cannot fully explain the high choices-only accuracy of LLMs in MCQA. Thus, while LLMs are not fully incapable of reasoning in MCQA, we still advocate for the use of stronger baselines in MCQA benchmarks, the design of robust MCQA datasets for fair evaluations, and further efforts to explain LLM decision-making.
6/11/2024