CancerLLM: A Large Language Model in Cancer Domain
2406.10459
0
0

Abstract
Medical Large Language Models (LLMs) such as ClinicalCamel 70B, Llama3-OpenBioLLM 70B have demonstrated impressive performance on a wide variety of medical NLP task.However, there still lacks a large language model (LLM) specifically designed for cancer domain. Moreover, these LLMs typically have billions of parameters, making them computationally expensive for healthcare systems.Thus, in this study, we propose CancerLLM, a model with 7 billion parameters and a Mistral-style architecture, pre-trained on 2,676,642 clinical notes and 515,524 pathology reports covering 17 cancer types, followed by fine-tuning on three cancer-relevant tasks, including cancer phenotypes extraction, cancer diagnosis generation, and cancer treatment plan generation. Our evaluation demonstrated that CancerLLM achieves state-of-the-art results compared to other existing LLMs, with an average F1 score improvement of 8.1%. Additionally, CancerLLM outperforms other models on two proposed robustness testbeds. This illustrates that CancerLLM can be effectively applied to clinical AI systems, enhancing clinical research and healthcare delivery in the field of cancer.
Create account to get full access
Overview
- This paper introduces CancerLLM, a large language model (LLM) specialized for the cancer domain.
- CancerLLM is trained on a large corpus of cancer-related data to provide advanced natural language processing capabilities for cancer-related tasks.
- The paper discusses the model's architecture, training, and evaluation on various cancer-related applications.
Plain English Explanation
CancerLLM is a special type of AI model called a large language model (LLM) that is focused on the cancer domain. Large language models are AI systems that can understand and generate human-like text by learning from a massive amount of text data.
The researchers who created CancerLLM trained this model specifically on a large collection of cancer-related information, such as medical literature, clinical notes, and cancer research papers. This allows CancerLLM to better understand and work with cancer-specific terminology, concepts, and tasks compared to a more general-purpose language model.
The goal of CancerLLM is to provide advanced natural language processing capabilities that can be applied to various cancer-related applications, such as summarizing cancer research, answering cancer-related questions, and assisting with cancer treatment planning. By leveraging the power of large language models in the cancer domain, CancerLLM aims to support cancer research, patient care, and decision-making.
Technical Explanation
The CancerLLM model is built upon the Transformer architecture, a widely-used neural network design for natural language processing tasks. The researchers trained CancerLLM on a large corpus of cancer-related data, including medical journals, clinical notes, cancer research papers, and other relevant sources.
During the training process, the model learns to understand the relationships between cancer-specific terminology, concepts, and the contextual nuances of cancer-related language. This allows CancerLLM to generate coherent and relevant cancer-focused text, as well as perform tasks like question answering, summarization, and knowledge extraction on cancer-related information.
The paper presents various experiments and evaluations of CancerLLM's performance on different cancer-related tasks, such as clinical note generation, cancer research summarization, and treatment recommendation. The results demonstrate that CancerLLM outperforms general-purpose language models on these cancer-specific applications, highlighting the benefits of domain-specific language modeling for the cancer field.
Critical Analysis
The paper provides a comprehensive introduction to CancerLLM and demonstrates its potential value in the cancer domain. However, the researchers acknowledge several limitations and areas for further research.
One potential concern is the quality and representativeness of the training data used to develop CancerLLM. The researchers note that the corpus may have biases or gaps in coverage, which could impact the model's performance on certain cancer-related tasks or its ability to generalize to diverse cancer populations.
Additionally, while the paper presents promising results, the researchers emphasize the need for further validation and evaluation of CancerLLM in real-world clinical settings. The model's performance should be assessed in collaborative studies with healthcare professionals to ensure its practical utility and safety in clinical decision-making.
Finally, the researchers highlight the importance of addressing ethical considerations, such as data privacy, model transparency, and the potential for unintended consequences when deploying large language models in the healthcare domain. These issues will require careful attention and ongoing monitoring as CancerLLM and similar models are further developed and integrated into cancer care.
Conclusion
The CancerLLM paper introduces a novel large language model tailored for the cancer domain, showcasing the potential of domain-specific language modeling to support cancer research, patient care, and decision-making. By leveraging the power of large language models and focusing on cancer-related data and tasks, CancerLLM demonstrates improved performance compared to general-purpose language models in various cancer-specific applications.
While the paper highlights the promise of CancerLLM, it also acknowledges the need for further research, validation, and careful consideration of ethical implications. As the field of large language models continues to evolve, the development of specialized models like CancerLLM could have significant impacts on the way cancer is understood, diagnosed, and treated in the years to come.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
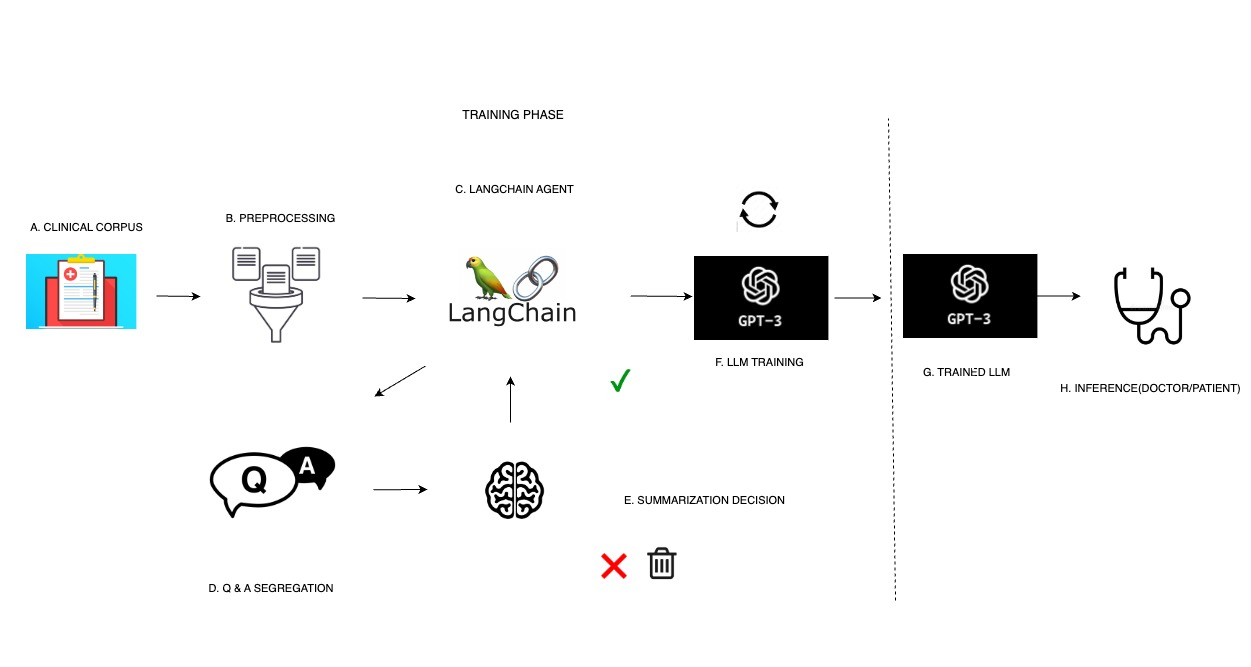
A Large Language Model Pipeline for Breast Cancer Oncology
Tristen Pool, Dennis Trujillo
0
0
Large language models (LLMs) have demonstrated potential in the innovation of many disciplines. However, how they can best be developed for oncology remains underdeveloped. State-of-the-art OpenAI models were fine-tuned on a clinical dataset and clinical guidelines text corpus for two important cancer treatment factors, adjuvant radiation therapy and chemotherapy, using a novel Langchain prompt engineering pipeline. A high accuracy (0.85+) was achieved in the classification of adjuvant radiation therapy and chemotherapy for breast cancer patients. Furthermore, a confidence interval was formed from observational data on the quality of treatment from human oncologists to estimate the proportion of scenarios in which the model must outperform the original oncologist in its treatment prediction to be a better solution overall as 8.2% to 13.3%. Due to indeterminacy in the outcomes of cancer treatment decisions, future investigation, potentially a clinical trial, would be required to determine if this threshold was met by the models. Nevertheless, with 85% of U.S. cancer patients receiving treatment at local community facilities, these kinds of models could play an important part in expanding access to quality care with outcomes that lie, at minimum, close to a human oncologist.
6/17/2024

A Survey on Large Language Models from General Purpose to Medical Applications: Datasets, Methodologies, and Evaluations
Jinqiang Wang, Huansheng Ning, Yi Peng, Qikai Wei, Daniel Tesfai, Wenwei Mao, Tao Zhu, Runhe Huang
0
0
Large Language Models (LLMs) have demonstrated surprising performance across various natural language processing tasks. Recently, medical LLMs enhanced with domain-specific knowledge have exhibited excellent capabilities in medical consultation and diagnosis. These models can smoothly simulate doctor-patient dialogues and provide professional medical advice. Most medical LLMs are developed through continued training of open-source general LLMs, which require significantly fewer computational resources than training LLMs from scratch. Additionally, this approach offers better protection of patient privacy compared to API-based solutions. This survey systematically explores how to train medical LLMs based on general LLMs. It covers: (a) how to acquire training corpus and construct customized medical training sets, (b) how to choose a appropriate training paradigm, (c) how to choose a suitable evaluation benchmark, and (d) existing challenges and promising future research directions are discussed. This survey can provide guidance for the development of LLMs focused on various medical applications, such as medical education, diagnostic planning, and clinical assistants.
6/18/2024
💬
Large Language Models for Medicine: A Survey
Yanxin Zheng, Wensheng Gan, Zefeng Chen, Zhenlian Qi, Qian Liang, Philip S. Yu
0
0
To address challenges in the digital economy's landscape of digital intelligence, large language models (LLMs) have been developed. Improvements in computational power and available resources have significantly advanced LLMs, allowing their integration into diverse domains for human life. Medical LLMs are essential application tools with potential across various medical scenarios. In this paper, we review LLM developments, focusing on the requirements and applications of medical LLMs. We provide a concise overview of existing models, aiming to explore advanced research directions and benefit researchers for future medical applications. We emphasize the advantages of medical LLMs in applications, as well as the challenges encountered during their development. Finally, we suggest directions for technical integration to mitigate challenges and potential research directions for the future of medical LLMs, aiming to meet the demands of the medical field better.
5/24/2024

Tx-LLM: A Large Language Model for Therapeutics
Juan Manuel Zambrano Chaves, Eric Wang, Tao Tu, Eeshit Dhaval Vaishnav, Byron Lee, S. Sara Mahdavi, Christopher Semturs, David Fleet, Vivek Natarajan, Shekoofeh Azizi
0
0
Developing therapeutics is a lengthy and expensive process that requires the satisfaction of many different criteria, and AI models capable of expediting the process would be invaluable. However, the majority of current AI approaches address only a narrowly defined set of tasks, often circumscribed within a particular domain. To bridge this gap, we introduce Tx-LLM, a generalist large language model (LLM) fine-tuned from PaLM-2 which encodes knowledge about diverse therapeutic modalities. Tx-LLM is trained using a collection of 709 datasets that target 66 tasks spanning various stages of the drug discovery pipeline. Using a single set of weights, Tx-LLM simultaneously processes a wide variety of chemical or biological entities(small molecules, proteins, nucleic acids, cell lines, diseases) interleaved with free-text, allowing it to predict a broad range of associated properties, achieving competitive with state-of-the-art (SOTA) performance on 43 out of 66 tasks and exceeding SOTA on 22. Among these, Tx-LLM is particularly powerful and exceeds best-in-class performance on average for tasks combining molecular SMILES representations with text such as cell line names or disease names, likely due to context learned during pretraining. We observe evidence of positive transfer between tasks with diverse drug types (e.g.,tasks involving small molecules and tasks involving proteins), and we study the impact of model size, domain finetuning, and prompting strategies on performance. We believe Tx-LLM represents an important step towards LLMs encoding biochemical knowledge and could have a future role as an end-to-end tool across the drug discovery development pipeline.
6/11/2024