Cascading Reinforcement Learning
2401.08961
0
0
🏅
Abstract
Cascading bandits have gained popularity in recent years due to their applicability to recommendation systems and online advertising. In the cascading bandit model, at each timestep, an agent recommends an ordered subset of items (called an item list) from a pool of items, each associated with an unknown attraction probability. Then, the user examines the list, and clicks the first attractive item (if any), and after that, the agent receives a reward. The goal of the agent is to maximize the expected cumulative reward. However, the prior literature on cascading bandits ignores the influences of user states (e.g., historical behaviors) on recommendations and the change of states as the session proceeds. Motivated by this fact, we propose a generalized cascading RL framework, which considers the impact of user states and state transition into decisions. In cascading RL, we need to select items not only with large attraction probabilities but also leading to good successor states. This imposes a huge computational challenge due to the combinatorial action space. To tackle this challenge, we delve into the properties of value functions, and design an oracle BestPerm to efficiently find the optimal item list. Equipped with BestPerm, we develop two algorithms CascadingVI and CascadingBPI, which are both computationally-efficient and sample-efficient, and provide near-optimal regret and sample complexity guarantees. Furthermore, we present experiments to show the improved computational and sample efficiencies of our algorithms compared to straightforward adaptations of existing RL algorithms in practice.
Create account to get full access
Overview
- The paper focuses on a class of reinforcement learning problems called "cascading bandits", which are relevant for recommendation systems and online advertising.
- In the cascading bandit model, an agent recommends a list of items to a user, who then examines the list and clicks on the first attractive item.
- The agent's goal is to maximize the expected cumulative reward, which depends on the user's click behavior.
- The paper proposes a "generalized cascading RL framework" that considers the influence of user states (e.g., past behaviors) on recommendations and the evolution of user states over time.
Plain English Explanation
In the cascading bandit problem, an AI system (the "agent") needs to recommend a list of items to a user, with the goal of maximizing the user's clicks and the system's overall reward. The user examines the list and clicks on the first item they find interesting. The agent's challenge is to recommend the items in an order that is likely to lead to a click, while also considering how the user's state (their past behavior and preferences) might change as they go through the list.
The researchers propose a new approach called "cascading RL" that takes the user's state and state transitions into account. This is more realistic than previous work, which ignored the influence of the user's history and how they might respond differently to recommendations over time. However, this added complexity also makes the problem computationally much harder to solve.
To address this, the researchers develop specialized algorithms that can efficiently find the best order of items to recommend, even with the added consideration of user state. These algorithms are shown to be both computationally efficient and sample efficient (requiring fewer interactions with users to learn a good policy).
Technical Explanation
The paper introduces a generalized cascading RL framework that extends the standard cascading bandit model by incorporating the impact of user states and state transitions on the recommendation process. In this framework, the agent needs to select an ordered list of items not only based on their attraction probabilities, but also considering how the recommended items will affect the user's future state and likelihood of clicking.
To tackle the computational challenge posed by the large combinatorial action space, the researchers analyze the properties of the value function and design an efficient oracle called "BestPerm" to find the optimal item list. Leveraging BestPerm, they develop two algorithms: CascadingVI and CascadingBPI. Both algorithms provide strong theoretical guarantees in terms of near-optimal regret and sample complexity.
The experiments demonstrate that the proposed algorithms significantly outperform straightforward adaptations of existing RL algorithms, both in terms of computation time and sample efficiency. This highlights the importance of exploiting the structure of the cascading RL problem to develop specialized and effective solution approaches.
Critical Analysis
The paper presents an important extension of the cascading bandit framework that addresses a key limitation of prior work: the lack of consideration for user state and state transitions. This is a realistic and practical extension that aligns better with real-world recommendation and advertising scenarios.
However, the paper does not explore the potential downsides or unintended consequences of this approach. For example, by optimizing recommendations based on anticipated user state changes, the system might inadvertently manipulate or exploit user behavior in ways that are not aligned with the user's best interests. [https://aimodels.fyi/papers/arxiv/chain-choice-hierarchical-policy-learning-conversational-recommendation]
Additionally, the paper does not discuss potential biases or fairness issues that could arise from the proposed algorithms. The way the system learns and makes recommendations could disproportionately benefit some users over others, leading to unfair or undesirable outcomes. [https://aimodels.fyi/papers/arxiv/distributed-no-regret-learning-multi-stage-systems]
Further research is needed to fully understand the implications and potential downsides of the generalized cascading RL framework, especially regarding user privacy, manipulation, and fairness. [https://aimodels.fyi/papers/arxiv/lc-tsallis-inf-generalized-best-both-worlds]
Conclusion
The paper introduces a novel and important extension to the cascading bandit problem by incorporating user state and state transitions into the recommendation process. The proposed generalized cascading RL framework and its accompanying algorithms demonstrate significant improvements in computational and sample efficiency compared to existing approaches.
While this research advances the state-of-the-art in reinforcement learning for recommendation systems, further work is needed to fully understand the implications and potential downsides of this approach. Careful consideration of user privacy, manipulation, and fairness will be crucial as these techniques are developed and deployed in real-world applications. [https://aimodels.fyi/papers/arxiv/online-continuous-hyperparameter-optimization-generalized-linear-contextual, https://aimodels.fyi/papers/arxiv/trajectory-wise-iterative-reinforcement-learning-framework-auto]
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Bandits with Preference Feedback: A Stackelberg Game Perspective
Barna P'asztor, Parnian Kassraie, Andreas Krause
0
0
Bandits with preference feedback present a powerful tool for optimizing unknown target functions when only pairwise comparisons are allowed instead of direct value queries. This model allows for incorporating human feedback into online inference and optimization and has been employed in systems for fine-tuning large language models. The problem is well understood in simplified settings with linear target functions or over finite small domains that limit practical interest. Taking the next step, we consider infinite domains and nonlinear (kernelized) rewards. In this setting, selecting a pair of actions is quite challenging and requires balancing exploration and exploitation at two levels: within the pair, and along the iterations of the algorithm. We propose MAXMINLCB, which emulates this trade-off as a zero-sum Stackelberg game, and chooses action pairs that are informative and yield favorable rewards. MAXMINLCB consistently outperforms existing algorithms and satisfies an anytime-valid rate-optimal regret guarantee. This is due to our novel preference-based confidence sequences for kernelized logistic estimators.
6/26/2024

Leveraging Offline Data in Linear Latent Bandits
Chinmaya Kausik, Kevin Tan, Ambuj Tewari
0
0
Sequential decision-making domains such as recommender systems, healthcare and education often have unobserved heterogeneity in the population that can be modeled using latent bandits $-$ a framework where an unobserved latent state determines the model for a trajectory. While the latent bandit framework is compelling, the extent of its generality is unclear. We first address this by establishing a de Finetti theorem for decision processes, and show that $textit{every}$ exchangeable and coherent stateless decision process is a latent bandit. The latent bandit framework lends itself particularly well to online learning with offline datasets, a problem of growing interest in sequential decision-making. One can leverage offline latent bandit data to learn a complex model for each latent state, so that an agent can simply learn the latent state online to act optimally. We focus on a linear model for a latent bandit with $d_A$-dimensional actions, where the latent states lie in an unknown $d_K$-dimensional subspace for $d_K ll d_A$. We present SOLD, a novel principled method to learn this subspace from short offline trajectories with guarantees. We then provide two methods to leverage this subspace online: LOCAL-UCB and ProBALL-UCB. We demonstrate that LOCAL-UCB enjoys $tilde O(min(d_Asqrt{T}, d_Ksqrt{T}(1+sqrt{d_AT/d_KN})))$ regret guarantees, where the effective dimension is lower when the size $N$ of the offline dataset is larger. ProBALL-UCB enjoys a slightly weaker guarantee, but is more practical and computationally efficient. Finally, we establish the efficacy of our methods using experiments on both synthetic data and real-life movie recommendation data from MovieLens.
5/28/2024

Recommenadation aided Caching using Combinatorial Multi-armed Bandits
Pavamana K J, Chandramani Kishore Singh
0
0
We study content caching with recommendations in a wireless network where the users are connected through a base station equipped with a finite-capacity cache. We assume a fixed set of contents with unknown user preferences and content popularities. We can recommend a subset of the contents to the users which encourages the users to request these contents. Recommendation can thus be used to increase cache hits. We formulate the cache hit optimization problem as a combinatorial multi-armed bandit (CMAB). We propose a UCB-based algorithm to decide which contents to cache and recommend. We provide an upper bound on the regret of our algorithm. We numerically demonstrate the performance of our algorithm and compare it to state-of-the-art algorithms.
5/6/2024
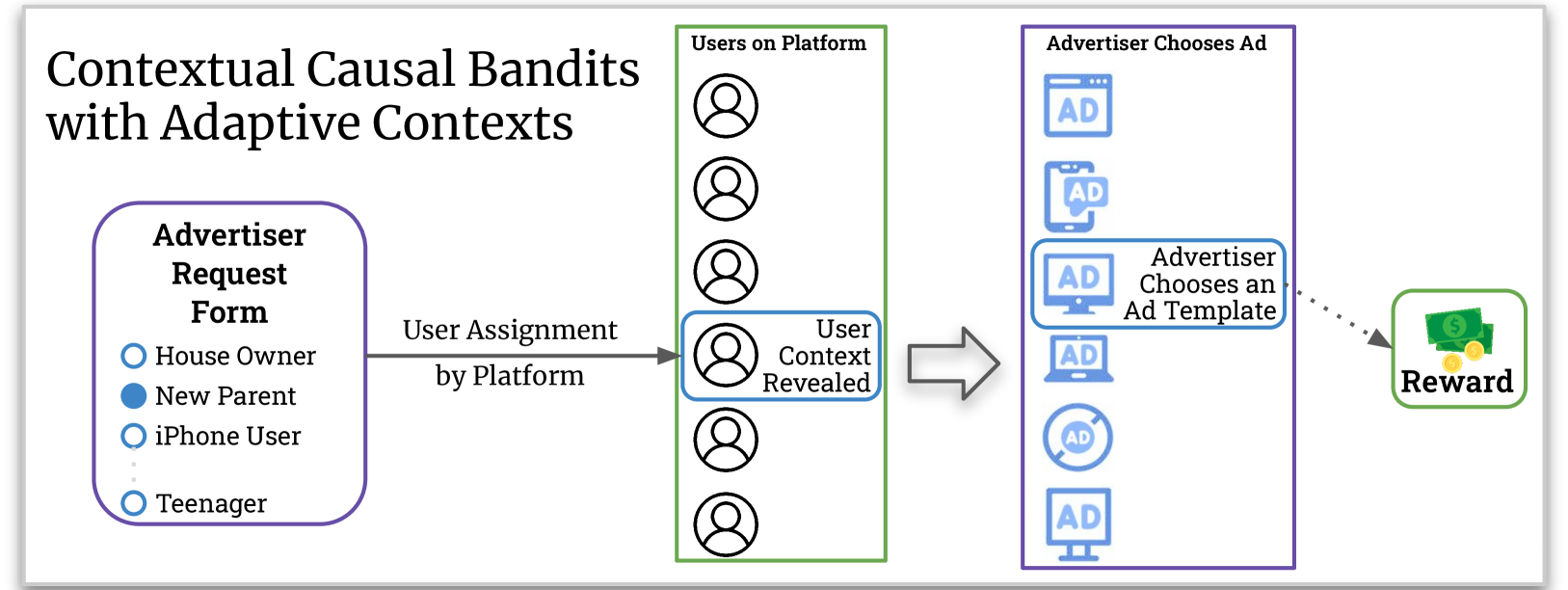
Causal Contextual Bandits with Adaptive Context
Rahul Madhavan, Aurghya Maiti, Gaurav Sinha, Siddharth Barman
0
0
We study a variant of causal contextual bandits where the context is chosen based on an initial intervention chosen by the learner. At the beginning of each round, the learner selects an initial action, depending on which a stochastic context is revealed by the environment. Following this, the learner then selects a final action and receives a reward. Given $T$ rounds of interactions with the environment, the objective of the learner is to learn a policy (of selecting the initial and the final action) with maximum expected reward. In this paper we study the specific situation where every action corresponds to intervening on a node in some known causal graph. We extend prior work from the deterministic context setting to obtain simple regret minimization guarantees. This is achieved through an instance-dependent causal parameter, $lambda$, which characterizes our upper bound. Furthermore, we prove that our simple regret is essentially tight for a large class of instances. A key feature of our work is that we use convex optimization to address the bandit exploration problem. We also conduct experiments to validate our theoretical results, and release our code at our project GitHub repository: https://github.com/adaptiveContextualCausalBandits/aCCB.
6/4/2024