Characterizing Multimodal Long-form Summarization: A Case Study on Financial Reports
2404.06162
0
0
Abstract
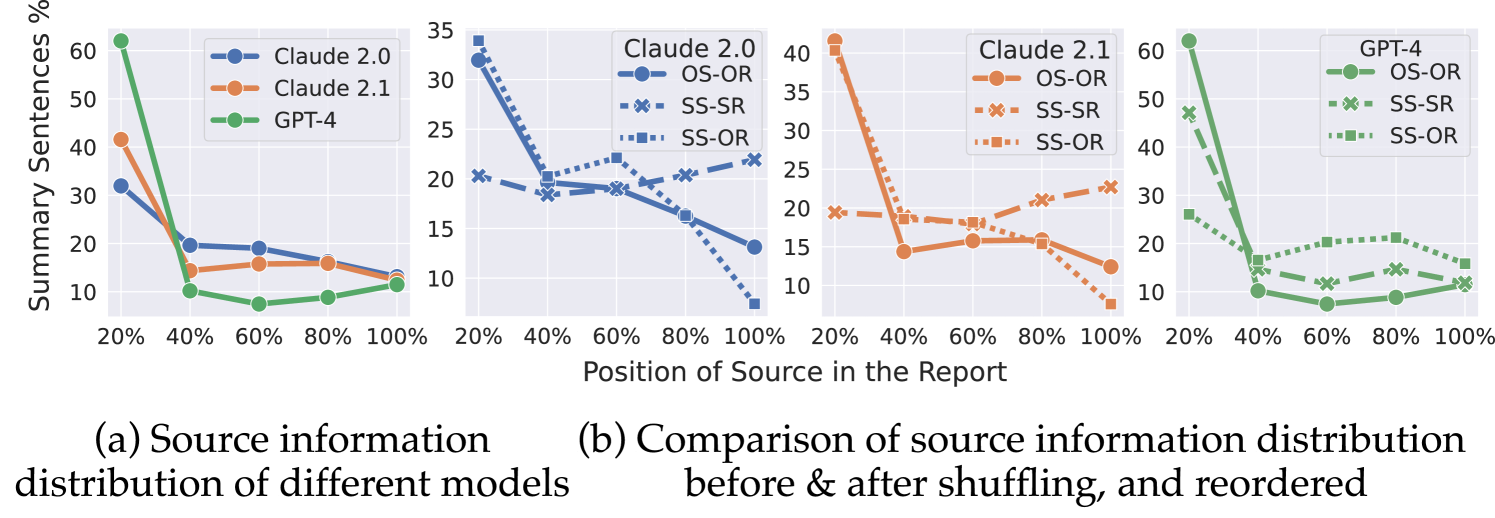
As large language models (LLMs) expand the power of natural language processing to handle long inputs, rigorous and systematic analyses are necessary to understand their abilities and behavior. A salient application is summarization, due to its ubiquity and controversy (e.g., researchers have declared the death of summarization). In this paper, we use financial report summarization as a case study because financial reports not only are long but also use numbers and tables extensively. We propose a computational framework for characterizing multimodal long-form summarization and investigate the behavior of Claude 2.0/2.1, GPT-4/3.5, and Command. We find that GPT-3.5 and Command fail to perform this summarization task meaningfully. For Claude 2 and GPT-4, we analyze the extractiveness of the summary and identify a position bias in LLMs. This position bias disappears after shuffling the input for Claude, which suggests that Claude has the ability to recognize important information. We also conduct a comprehensive investigation on the use of numeric data in LLM-generated summaries and offer a taxonomy of numeric hallucination. We employ prompt engineering to improve GPT-4's use of numbers with limited success. Overall, our analyses highlight the strong capability of Claude 2 in handling long multimodal inputs compared to GPT-4.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores the challenges and opportunities in long-form, multimodal summarization on financial reports.
- The researchers analyze the relationship between the input text and the generated summary, investigating how different modalities (text, tables, figures) contribute to the summarization process.
- They propose a novel evaluation framework to assess the quality and faithfulness of the generated summaries.
Plain English Explanation
This paper looks at the task of creating detailed summaries for long, complex documents that contain not just text but also tables, charts, and other visual elements. The researchers focused on financial reports as a case study, as these documents often contain a mix of textual information and numerical data.
The key questions the paper tries to answer are:
- How can we build AI systems that can effectively summarize these multimodal documents?
- What is the relationship between the original document and the summary produced by the AI?
- How can we evaluate whether the summary accurately captures the most important information from the full document?
To address these questions, the researchers developed a new evaluation framework. This allowed them to assess not just the quality of the summaries, but also how well they aligned with the original source material. The goal was to ensure the summaries were faithful representations of the full documents, rather than just fluent-sounding text.
Technical Explanation
The paper starts by introducing the task of long-form, multimodal summarization, where the input documents contain a mix of text, tables, figures, and other visual elements. The researchers focus on financial reports as a case study, as these documents often have this multimodal nature.
To study this task, the authors collected a dataset of financial reports and their associated human-written summaries. They then developed a novel evaluation framework that went beyond just measuring the quality of the summaries. This framework also assessed how well the summaries aligned with and faithfully captured the key information from the original documents.
Using this framework, the researchers conducted a series of experiments to trace the relationship between the input documents and the generated summaries. They investigated how different modalities (text, tables, figures) contributed to the summarization process, and how faithfully the summaries reflected the content of the full documents.
The findings from this analysis provide valuable insights into the challenges and opportunities in multimodal long-form summarization. The authors discuss the implications of their work for developing more robust and trustworthy AI-powered summarization systems, particularly in domains like finance where accuracy and transparency are critical.
Critical Analysis
The paper makes a compelling case for the importance of multimodal long-form summarization, particularly in domains like finance where documents often contain a rich mix of textual and numerical information. The proposed evaluation framework is a promising step towards more holistic and meaningful assessment of summarization systems.
However, the paper also acknowledges several limitations and areas for future research. For example, the dataset used is relatively small, and the analysis is focused on a specific domain (financial reports). It would be valuable to see how well the findings generalize to other types of long-form, multimodal documents.
Additionally, while the paper provides insights into the relationship between the input and output, it does not delve deeply into the inner workings of the summarization models themselves. Further research could explore how different architectural choices or training approaches impact the faithfulness and quality of the generated summaries.
Overall, this paper makes a valuable contribution to the field of multimodal natural language processing, highlighting the need for more nuanced evaluation and a deeper understanding of the strengths and limitations of current summarization technologies. As AI systems become increasingly integrated into high-stakes domains, this type of critical analysis and continuous improvement will be essential.
Conclusion
This paper offers a comprehensive analysis of the challenges and opportunities in long-form, multimodal summarization, using financial reports as a case study. The researchers developed a novel evaluation framework that goes beyond just measuring summary quality, also assessing how faithfully the summaries reflect the original source material.
The findings provide valuable insights into the relationship between the input documents and the generated summaries, showing how different modalities (text, tables, figures) contribute to the summarization process. This work has important implications for the development of more robust and trustworthy AI-powered summarization systems, particularly in domains where accuracy and transparency are critical.
While the paper acknowledges several limitations, it represents a significant step forward in the understanding and evaluation of multimodal natural language processing technologies. As AI continues to advance, this type of critical analysis and continuous improvement will be essential to ensure these systems are reliable, transparent, and beneficial to society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
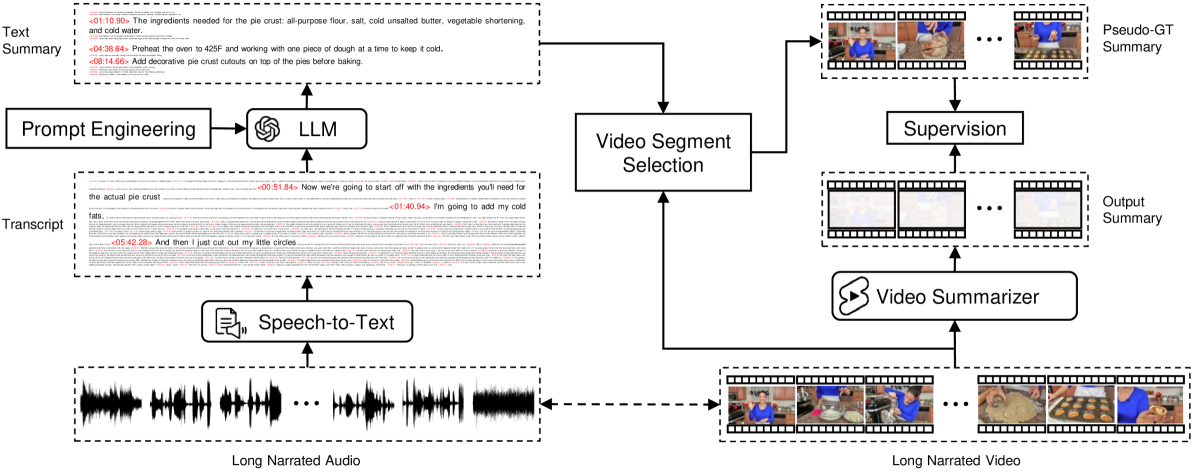
Scaling Up Video Summarization Pretraining with Large Language Models
Dawit Mureja Argaw, Seunghyun Yoon, Fabian Caba Heilbron, Hanieh Deilamsalehy, Trung Bui, Zhaowen Wang, Franck Dernoncourt, Joon Son Chung
0
0
Long-form video content constitutes a significant portion of internet traffic, making automated video summarization an essential research problem. However, existing video summarization datasets are notably limited in their size, constraining the effectiveness of state-of-the-art methods for generalization. Our work aims to overcome this limitation by capitalizing on the abundance of long-form videos with dense speech-to-video alignment and the remarkable capabilities of recent large language models (LLMs) in summarizing long text. We introduce an automated and scalable pipeline for generating a large-scale video summarization dataset using LLMs as Oracle summarizers. By leveraging the generated dataset, we analyze the limitations of existing approaches and propose a new video summarization model that effectively addresses them. To facilitate further research in the field, our work also presents a new benchmark dataset that contains 1200 long videos each with high-quality summaries annotated by professionals. Extensive experiments clearly indicate that our proposed approach sets a new state-of-the-art in video summarization across several benchmarks.
4/5/2024

Instruction-Guided Bullet Point Summarization of Long Financial Earnings Call Transcripts
Subhendu Khatuya, Koushiki Sinha, Niloy Ganguly, Saptarshi Ghosh, Pawan Goyal
0
0
While automatic summarization techniques have made significant advancements, their primary focus has been on summarizing short news articles or documents that have clear structural patterns like scientific articles or government reports. There has not been much exploration into developing efficient methods for summarizing financial documents, which often contain complex facts and figures. Here, we study the problem of bullet point summarization of long Earning Call Transcripts (ECTs) using the recently released ECTSum dataset. We leverage an unsupervised question-based extractive module followed by a parameter efficient instruction-tuned abstractive module to solve this task. Our proposed model FLAN-FinBPS achieves new state-of-the-art performances outperforming the strongest baseline with 14.88% average ROUGE score gain, and is capable of generating factually consistent bullet point summaries that capture the important facts discussed in the ECTs.
5/14/2024
💬
Evaluating Text Summaries Generated by Large Language Models Using OpenAI's GPT
Hassan Shakil, Atqiya Munawara Mahi, Phuoc Nguyen, Zeydy Ortiz, Mamoun T. Mardini
0
0
This research examines the effectiveness of OpenAI's GPT models as independent evaluators of text summaries generated by six transformer-based models from Hugging Face: DistilBART, BERT, ProphetNet, T5, BART, and PEGASUS. We evaluated these summaries based on essential properties of high-quality summary - conciseness, relevance, coherence, and readability - using traditional metrics such as ROUGE and Latent Semantic Analysis (LSA). Uniquely, we also employed GPT not as a summarizer but as an evaluator, allowing it to independently assess summary quality without predefined metrics. Our analysis revealed significant correlations between GPT evaluations and traditional metrics, particularly in assessing relevance and coherence. The results demonstrate GPT's potential as a robust tool for evaluating text summaries, offering insights that complement established metrics and providing a basis for comparative analysis of transformer-based models in natural language processing tasks.
5/8/2024
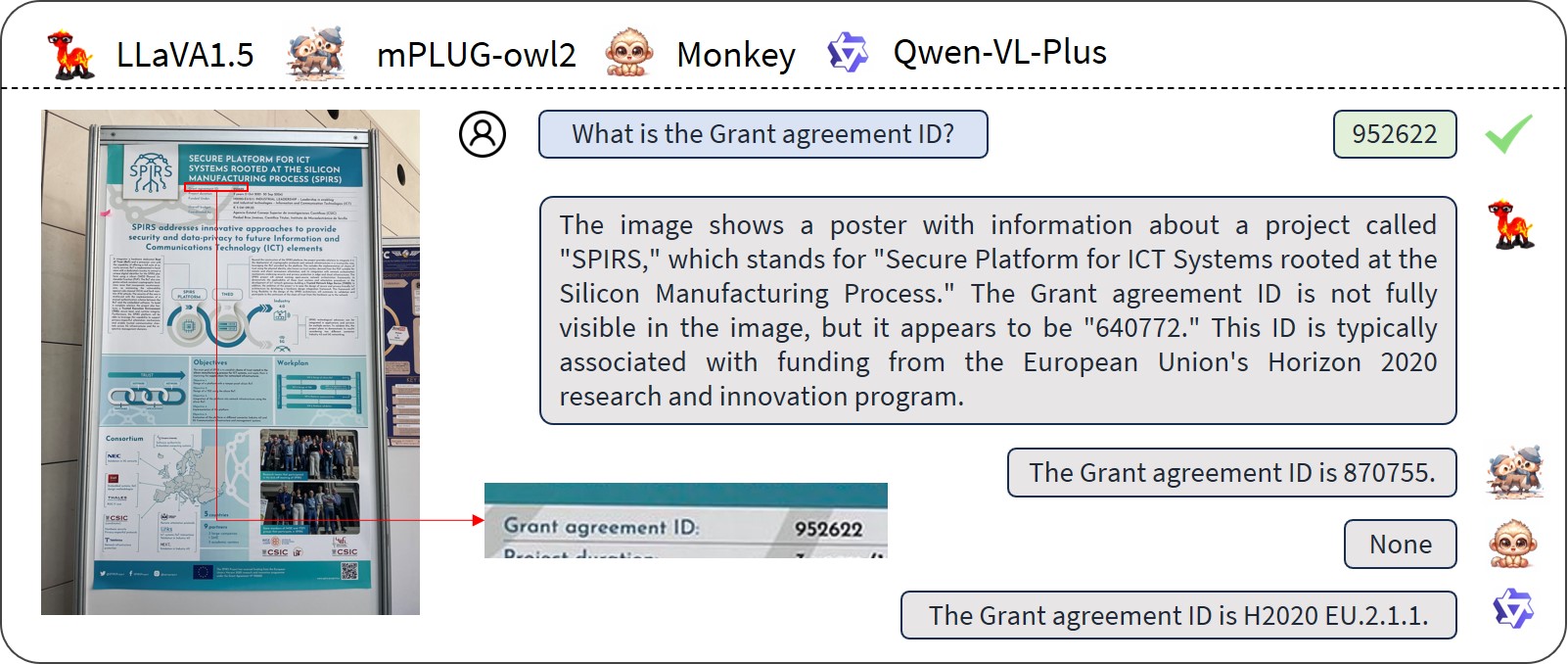
Exploring the Capabilities of Large Multimodal Models on Dense Text
Shuo Zhang, Biao Yang, Zhang Li, Zhiyin Ma, Yuliang Liu, Xiang Bai
0
0
While large multi-modal models (LMM) have shown notable progress in multi-modal tasks, their capabilities in tasks involving dense textual content remains to be fully explored. Dense text, which carries important information, is often found in documents, tables, and product descriptions. Understanding dense text enables us to obtain more accurate information, assisting in making better decisions. To further explore the capabilities of LMM in complex text tasks, we propose the DT-VQA dataset, with 170k question-answer pairs. In this paper, we conduct a comprehensive evaluation of GPT4V, Gemini, and various open-source LMMs on our dataset, revealing their strengths and weaknesses. Furthermore, we evaluate the effectiveness of two strategies for LMM: prompt engineering and downstream fine-tuning. We find that even with automatically labeled training datasets, significant improvements in model performance can be achieved. We hope that this research will promote the study of LMM in dense text tasks. Code will be released at https://github.com/Yuliang-Liu/MultimodalOCR.
5/14/2024