Constrained Meta Agnostic Reinforcement Learning
2406.14047
0
0

Abstract
Meta-Reinforcement Learning (Meta-RL) aims to acquire meta-knowledge for quick adaptation to diverse tasks. However, applying these policies in real-world environments presents a significant challenge in balancing rapid adaptability with adherence to environmental constraints. Our novel approach, Constraint Model Agnostic Meta Learning (C-MAML), merges meta learning with constrained optimization to address this challenge. C-MAML enables rapid and efficient task adaptation by incorporating task-specific constraints directly into its meta-algorithm framework during the training phase. This fusion results in safer initial parameters for learning new tasks. We demonstrate the effectiveness of C-MAML in simulated locomotion with wheeled robot tasks of varying complexity, highlighting its practicality and robustness in dynamic environments.
Create account to get full access
Overview
- This paper introduces Constrained Meta Agnostic Reinforcement Learning (CMARL), a novel approach to reinforcement learning (RL) that aims to address challenges faced by existing meta-learning and constrained RL methods.
- CMARL combines the principles of meta-learning and constrained Markov decision processes (CMDPs) to enable agents to learn general policies that satisfy constraints across a diverse range of environments.
- The key innovation of CMARL is its ability to learn a meta-policy that can adapt to new environments while respecting predefined constraints, such as safety or resource limits.
Plain English Explanation
CMARL is a new way of training AI systems to learn general skills that can be applied across different environments, while also following certain rules or constraints. Imagine you're teaching a robot to navigate a house - you might want it to learn how to move around efficiently, but also avoid bumping into furniture or using too much electricity.
Traditional reinforcement learning methods can struggle with this, as they often focus on optimizing for a single task without considering constraints. Meta-learning approaches, on the other hand, try to learn general skills that can be applied to new environments, but don't always account for constraints.
CMARL combines the best of both worlds. It allows the AI system to learn a "meta-policy" - a general set of skills that can be adapted to different environments. Crucially, this meta-policy is also designed to respect predefined constraints, such as safety or resource limits. So the robot can learn to navigate efficiently while still avoiding obstacles and minimizing energy use.
By incorporating constraints into the meta-learning process, CMARL aims to produce AI agents that are more robust, reliable, and aligned with human values as they are deployed in the real world.
Technical Explanation
The core idea of CMARL is to extend meta-learning approaches to the constrained Markov decision process (CMDP) setting. The authors propose a bilevel optimization framework that jointly learns a meta-policy and task-specific constraint functions.
The meta-policy is trained to quickly adapt to new environments while satisfying predefined constraints, such as safety or resource limits. This is achieved by optimizing the meta-policy parameters to minimize the expected constraint violation across a distribution of tasks.
The authors demonstrate the effectiveness of CMARL on a range of simulated robotic control tasks, where the agents must learn to perform complex maneuvers while respecting constraints like joint torque limits or obstacle avoidance. Compared to baseline methods, CMARL is able to learn more robust and constrained-satisfying policies, highlighting its potential for real-world applications where safety and resource efficiency are paramount.
Critical Analysis
The CMARL approach represents an interesting and important step forward in the field of constrained reinforcement learning. By integrating constraint satisfaction into the meta-learning process, the authors have developed a framework that can produce agents capable of adapting to new environments while respecting predefined limits.
One potential limitation of the current work is the reliance on hand-crafted constraint functions. In real-world applications, it may be challenging to precisely specify the appropriate constraints a priori. An interesting direction for future research would be to investigate methods for learning the constraint functions alongside the meta-policy, potentially through cooperative meta-learning or other advanced techniques.
Additionally, the paper focuses on simulated robotic control tasks, which, while valuable for proof-of-concept, may not fully capture the complexity and uncertainty of real-world environments. Further testing on more diverse and realistic benchmarks would help validate the broader applicability of the CMARL approach.
Overall, the CMARL framework represents a promising step towards developing AI systems that can learn general skills while respecting important constraints. As the authors note, this capability is crucial for the safe and responsible deployment of autonomous agents in the real world.
Conclusion
The Constrained Meta Agnostic Reinforcement Learning (CMARL) framework proposed in this paper offers a novel approach to reinforcement learning that combines the strengths of meta-learning and constrained Markov decision processes. By jointly learning a meta-policy and task-specific constraint functions, CMARL can produce agents capable of adapting to new environments while satisfying predefined limits on safety, resource usage, and other critical factors.
This work represents an important step forward in the field of constrained reinforcement learning, with significant implications for the development of robust and responsible autonomous systems. As AI agents become more pervasive in real-world applications, the ability to learn general skills while respecting essential constraints will be crucial for ensuring their safe and ethical deployment.
While the current paper focuses on simulated robotic control tasks, further research is needed to explore the broader applicability of CMARL and address potential limitations, such as the challenge of specifying appropriate constraint functions. Nevertheless, this work lays the groundwork for a promising new direction in reinforcement learning that could ultimately lead to the creation of more reliable, trustworthy, and beneficial AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
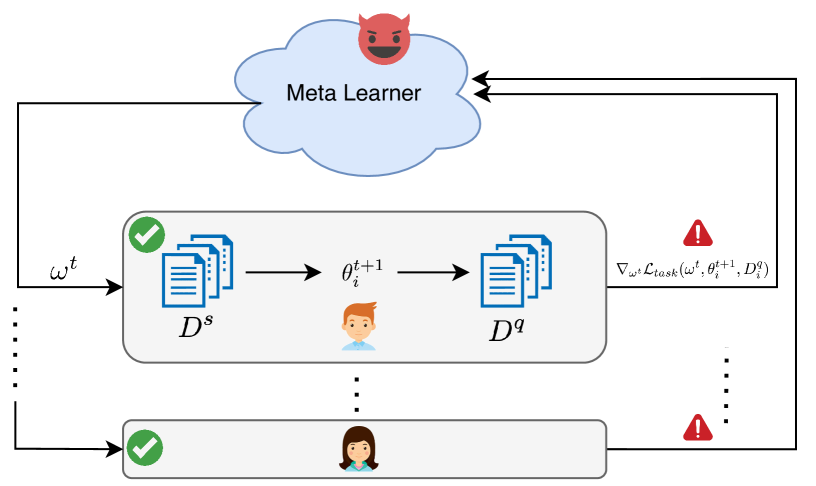
Privacy Challenges in Meta-Learning: An Investigation on Model-Agnostic Meta-Learning
Mina Rafiei, Mohammadmahdi Maheri, Hamid R. Rabiee
0
0
Meta-learning involves multiple learners, each dedicated to specific tasks, collaborating in a data-constrained setting. In current meta-learning methods, task learners locally learn models from sensitive data, termed support sets. These task learners subsequently share model-related information, such as gradients or loss values, which is computed using another part of the data termed query set, with a meta-learner. The meta-learner employs this information to update its meta-knowledge. Despite the absence of explicit data sharing, privacy concerns persist. This paper examines potential data leakage in a prominent metalearning algorithm, specifically Model-Agnostic Meta-Learning (MAML). In MAML, gradients are shared between the metalearner and task-learners. The primary objective is to scrutinize the gradient and the information it encompasses about the task dataset. Subsequently, we endeavor to propose membership inference attacks targeting the task dataset containing support and query sets. Finally, we explore various noise injection methods designed to safeguard the privacy of task data and thwart potential attacks. Experimental results demonstrate the effectiveness of these attacks on MAML and the efficacy of proper noise injection methods in countering them.
6/4/2024
🏅
Theoretical Analysis of Meta Reinforcement Learning: Generalization Bounds and Convergence Guarantees
Cangqing Wang, Mingxiu Sui, Dan Sun, Zecheng Zhang, Yan Zhou
0
0
This research delves deeply into Meta Reinforcement Learning (Meta RL) through a exploration focusing on defining generalization limits and ensuring convergence. By employing a approach this article introduces an innovative theoretical framework to meticulously assess the effectiveness and performance of Meta RL algorithms. We present an explanation of generalization limits measuring how well these algorithms can adapt to learning tasks while maintaining consistent results. Our analysis delves into the factors that impact the adaptability of Meta RL revealing the relationship, between algorithm design and task complexity. Additionally we establish convergence assurances by proving conditions under which Meta RL strategies are guaranteed to converge towards solutions. We examine the convergence behaviors of Meta RL algorithms across scenarios providing a comprehensive understanding of the driving forces behind their long term performance. This exploration covers both convergence and real time efficiency offering a perspective, on the capabilities of these algorithms.
5/24/2024
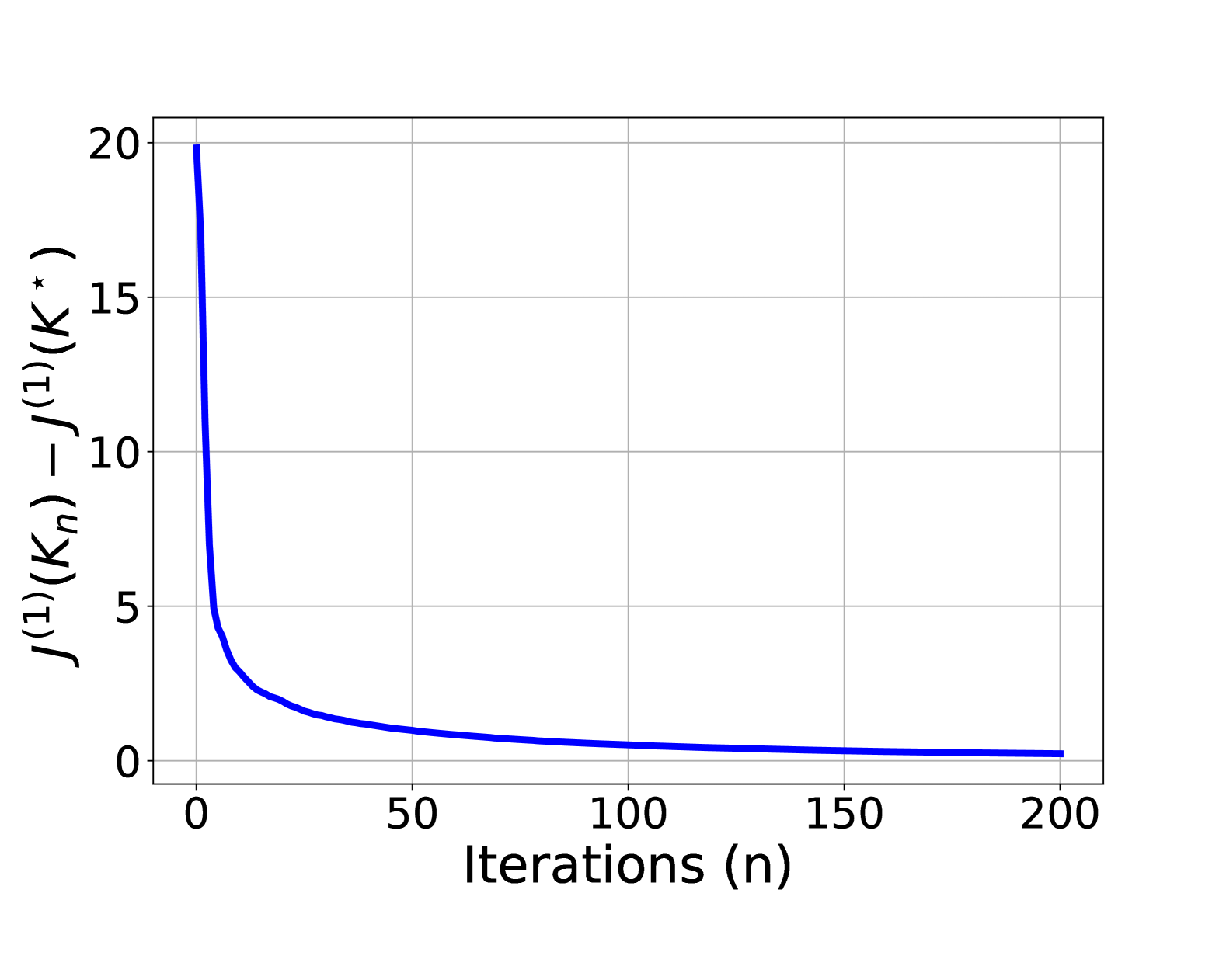
Meta-Learning Linear Quadratic Regulators: A Policy Gradient MAML Approach for Model-free LQR
Leonardo F. Toso, Donglin Zhan, James Anderson, Han Wang
0
0
We investigate the problem of learning linear quadratic regulators (LQR) in a multi-task, heterogeneous, and model-free setting. We characterize the stability and personalization guarantees of a policy gradient-based (PG) model-agnostic meta-learning (MAML) (Finn et al., 2017) approach for the LQR problem under different task-heterogeneity settings. We show that our MAML-LQR algorithm produces a stabilizing controller close to each task-specific optimal controller up to a task-heterogeneity bias in both model-based and model-free learning scenarios. Moreover, in the model-based setting, we show that such a controller is achieved with a linear convergence rate, which improves upon sub-linear rates from existing work. Our theoretical guarantees demonstrate that the learned controller can efficiently adapt to unseen LQR tasks.
6/4/2024
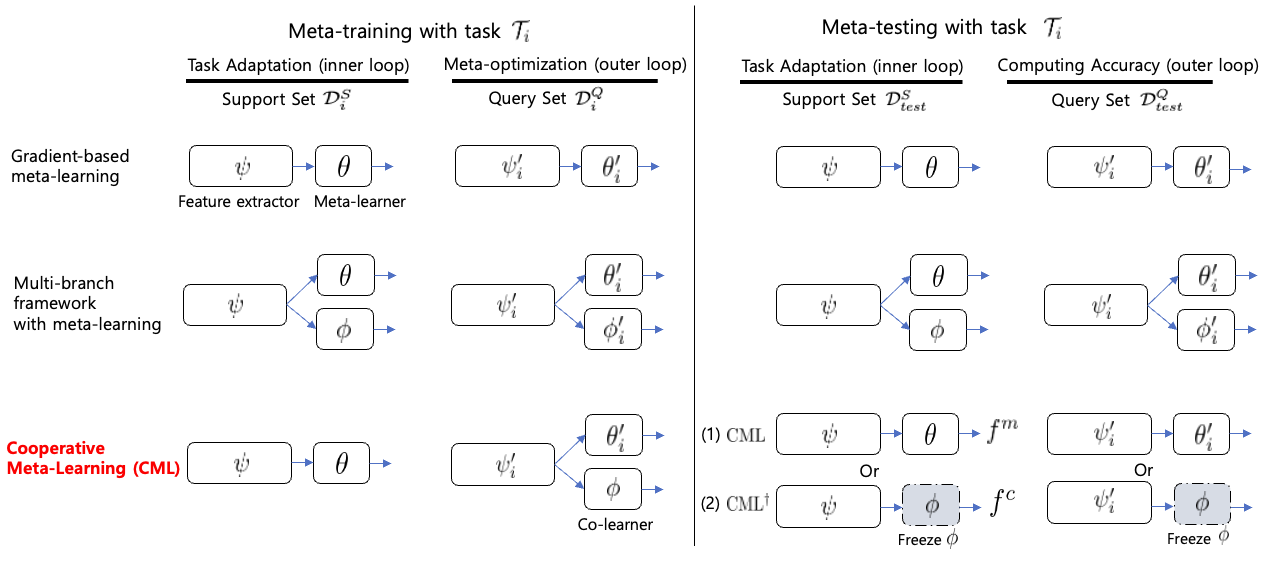
Cooperative Meta-Learning with Gradient Augmentation
Jongyun Shin, Seunjin Han, Jangho Kim
0
0
Model agnostic meta-learning (MAML) is one of the most widely used gradient-based meta-learning, consisting of two optimization loops: an inner loop and outer loop. MAML learns the new task from meta-initialization parameters with an inner update and finds the meta-initialization parameters in the outer loop. In general, the injection of noise into the gradient of the model for augmenting the gradient is one of the widely used regularization methods. In this work, we propose a novel cooperative meta-learning framework dubbed CML which leverages gradient-level regularization with gradient augmentation. We inject learnable noise into the gradient of the model for the model generalization. The key idea of CML is introducing the co-learner which has no inner update but the outer loop update to augment gradients for finding better meta-initialization parameters. Since the co-learner does not update in the inner loop, it can be easily deleted after meta-training. Therefore, CML infers with only meta-learner without additional cost and performance degradation. We demonstrate that CML is easily applicable to gradient-based meta-learning methods and CML leads to increased performance in few-shot regression, few-shot image classification and few-shot node classification tasks. Our codes are at https://github.com/JJongyn/CML.
6/10/2024