Contrastive Localized Language-Image Pre-Training

0
Sign in to get full access
Overview
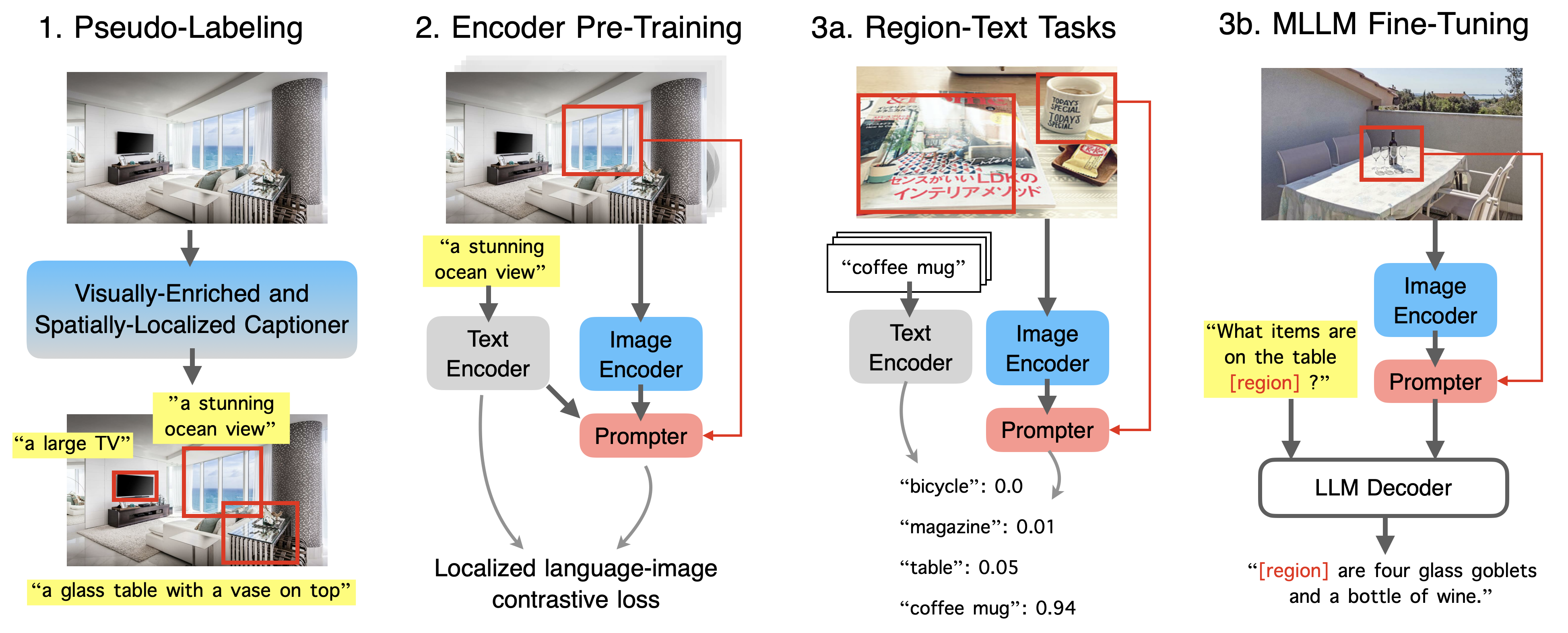
- The paper introduces a novel approach called Contrastive Localized Language-Image Pre-Training (CL-LIP) for improving the localization capabilities of CLIP, a popular language-image model.
- CL-LIP leverages contrastive learning to jointly optimize the model's ability to match text with relevant image regions, in addition to the overall image-text alignment.
- The authors demonstrate that CL-LIP outperforms CLIP on a range of localization tasks, while maintaining comparable performance on image-text retrieval.
Plain English Explanation
Contrastive Localized Language-Image Pre-Training aims to enhance the ability of CLIP, a language-image model, to precisely locate the relevant image regions that correspond to a given text description.
CLIP is a powerful model that can match text with relevant images, but it doesn't always do a great job of pinpointing the exact image regions that the text is referring to. This can be a limitation for applications that require fine-grained localization, like image captioning or visual question answering.
CL-LIP tackles this by using a specialized training process called contrastive learning. Instead of just aligning the entire image with the text, CL-LIP also learns to match the text with the specific image regions that are most relevant.
This localized approach allows the model to better understand the connection between language and visual elements, leading to improved performance on tasks that require precise localization. At the same time, CL-LIP maintains CLIP's strong ability to match text with whole images, ensuring it can still handle high-level image-text retrieval well.
Technical Explanation
The key idea behind CL-LIP is to augment the standard CLIP training procedure with an additional contrastive loss that encourages the model to align text with the most relevant image regions, rather than just the overall image.
Specifically, during training, the model is presented with an image-text pair and is tasked with not only matching the text to the correct image, but also identifying the specific image regions that correspond to the text. This is achieved by computing similarity scores between the text and various image patches, and then maximizing the similarity for the correct patch while minimizing it for incorrect patches.
The authors demonstrate that this localized contrastive learning approach leads to significant improvements in the model's ability to localize text in images, as measured by various region-based evaluation metrics. At the same time, CL-LIP maintains comparable performance to CLIP on standard image-text retrieval tasks, indicating that the localization-focused training does not come at the expense of the model's broader language-vision understanding.
Critical Analysis
The CL-LIP approach is a thoughtful and well-designed extension of CLIP that addresses an important limitation of the original model. By incorporating localized contrastive learning, CL-LIP is able to better capture the fine-grained relationships between language and visual elements, which is crucial for tasks like image captioning and visual question answering.
That said, the paper does not provide a thorough discussion of potential limitations or areas for further research. For example, it would be interesting to understand how CL-LIP's performance scales with the size of the training dataset, or how it might be affected by language or image distribution shifts. Additionally, the authors could have explored ways to further improve the model's localization capabilities, such as incorporating attention mechanisms or region proposal networks.
Overall, the CL-LIP approach represents a valuable contribution to the field of language-vision understanding, and the demonstrated improvements on localization tasks are quite promising. However, a more comprehensive analysis of the model's strengths, weaknesses, and future research directions would have further strengthened the paper.
Conclusion
Contrastive Localized Language-Image Pre-Training (CL-LIP) is a novel technique that enhances the localization capabilities of CLIP, a popular language-image model, without compromising its overall performance on image-text retrieval tasks.
By incorporating a specialized contrastive learning objective that aligns text with relevant image regions, CL-LIP is able to better capture the fine-grained relationships between language and visual elements. This, in turn, leads to significant improvements in the model's ability to precisely locate the image regions that correspond to a given text description.
The CL-LIP approach represents an important step forward in the field of language-vision understanding, as precise localization is crucial for many real-world applications. While the paper could have explored potential limitations and future research directions in more depth, the demonstrated results are quite promising and suggest that CL-LIP is a valuable addition to the language-image modeling toolkit.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!