CSEPrompts: A Benchmark of Introductory Computer Science Prompts
2404.02540
0
0
📉
Abstract
Recent advances in AI, machine learning, and NLP have led to the development of a new generation of Large Language Models (LLMs) that are trained on massive amounts of data and often have trillions of parameters. Commercial applications (e.g., ChatGPT) have made this technology available to the general public, thus making it possible to use LLMs to produce high-quality texts for academic and professional purposes. Schools and universities are aware of the increasing use of AI-generated content by students and they have been researching the impact of this new technology and its potential misuse. Educational programs in Computer Science (CS) and related fields are particularly affected because LLMs are also capable of generating programming code in various programming languages. To help understand the potential impact of publicly available LLMs in CS education, we introduce CSEPrompts, a framework with hundreds of programming exercise prompts and multiple-choice questions retrieved from introductory CS and programming courses. We also provide experimental results on CSEPrompts to evaluate the performance of several LLMs with respect to generating Python code and answering basic computer science and programming questions.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper introduces CSEPrompts, a benchmark dataset for evaluating large language models (LLMs) on introductory computer science (CS) prompts.
- The dataset covers a range of topics, including programming, algorithms, data structures, and computer organization, with prompts designed to test an LLM's understanding and problem-solving abilities in the field of computer science.
- The authors evaluate several state-of-the-art LLMs on the CSEPrompts dataset and provide insights into their performance and limitations.
Plain English Explanation
The paper describes a new dataset called CSEPrompts, which is designed to test how well large language models (LLMs) can handle questions and problems in the field of computer science. LLMs are artificial intelligence systems that can understand and generate human-like text, and they are becoming increasingly capable at a wide range of tasks. However, it's important to understand their limitations, especially when it comes to specialized domains like computer science.
The CSEPrompts dataset includes a variety of prompts, or questions and problems, covering topics like programming, algorithms, data structures, and computer organization. These are the kinds of topics that students typically learn about in introductory computer science courses. By evaluating how well different LLMs perform on this dataset, the researchers can gain insights into the strengths and weaknesses of these models when it comes to computer science knowledge and problem-solving.
The paper presents the results of testing several state-of-the-art LLMs on the CSEPrompts dataset. This helps to identify which models are better suited for tasks related to computer science, and where there is still room for improvement. Understanding the capabilities and limitations of LLMs in this domain is important as these models become more widely used in educational and other applications.
Technical Explanation
The paper introduces a new benchmark dataset called CSEPrompts, which is designed to evaluate the performance of large language models (LLMs) on introductory computer science (CS) topics. The dataset includes a diverse set of prompts covering a range of CS concepts, such as programming, algorithms, data structures, and computer organization.
The authors evaluate several state-of-the-art LLMs, including GPT-3, InstructGPT, and CodeGPT, on the CSEPrompts dataset. They assess the models' performance on various metrics, such as accuracy, fluency, and relevance, to gain insights into the models' understanding and problem-solving capabilities in the computer science domain.
The results of the evaluation reveal both the strengths and limitations of the tested LLMs when it comes to handling computer science-related tasks. The models demonstrate varying levels of performance across different CS topics, highlighting the need for further research and development to improve the ability of LLMs to engage with specialized domains like computer science.
Critical Analysis
The CSEPrompts dataset and the evaluation of LLMs presented in this paper are a valuable contribution to the field of natural language processing and its application in computer science education. By developing a specialized benchmark dataset, the authors have provided a much-needed tool for assessing the capabilities of LLMs in a specific domain.
One potential limitation of the study is the scope of the dataset, which focuses on introductory-level computer science topics. While this is a crucial starting point, it would be beneficial to expand the dataset to include more advanced CS concepts and problem-solving scenarios to fully evaluate the potential of LLMs in this domain.
Additionally, the paper does not provide a detailed analysis of the types of errors or limitations observed in the LLMs' performance. A more comprehensive examination of the models' strengths, weaknesses, and potential biases could help guide future research and development efforts to improve the suitability of these models for computer science education and other applications.
Conclusion
The CSEPrompts dataset and the evaluation of LLMs presented in this paper represent an important step towards understanding the capabilities and limitations of large language models in the context of computer science education. By providing a specialized benchmark, the authors have laid the groundwork for further research and development to improve the performance of LLMs on tasks related to programming, algorithms, data structures, and other core computer science concepts.
As LLMs continue to advance and become more widely adopted, the insights gained from this study can inform the design of educational tools, tutoring systems, and other applications that leverage these powerful language models to support learning and problem-solving in the field of computer science.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
Quality Assessment of Prompts Used in Code Generation
Mohammed Latif Siddiq, Simantika Dristi, Joy Saha, Joanna C. S. Santos
0
0
Large Language Models (LLMs) are gaining popularity among software engineers. A crucial aspect of developing effective code-generation LLMs is to evaluate these models using a robust benchmark. Evaluation benchmarks with quality issues can provide a false sense of performance. In this work, we conduct the first-of-its-kind study of the quality of prompts within benchmarks used to compare the performance of different code generation models. To conduct this study, we analyzed 3,566 prompts from 9 code generation benchmarks to identify quality issues in them. We also investigated whether fixing the identified quality issues in the benchmarks' prompts affects a model's performance. We also studied memorization issues of the evaluation dataset, which can put into question a benchmark's trustworthiness. We found that code generation evaluation benchmarks mainly focused on Python and coding exercises and had very limited contextual dependencies to challenge the model. These datasets and the developers' prompts suffer from quality issues like spelling and grammatical errors, unclear sentences to express developers' intent, and not using proper documentation style. Fixing all these issues in the benchmarks can lead to a better performance for Python code generation, but not a significant improvement was observed for Java code generation. We also found evidence that GPT-3.5-Turbo and CodeGen-2.5 models possibly have data contamination issues.
4/17/2024

Prompt Design and Engineering: Introduction and Advanced Methods
Xavier Amatriain
0
0
Prompt design and engineering has rapidly become essential for maximizing the potential of large language models. In this paper, we introduce core concepts, advanced techniques like Chain-of-Thought and Reflection, and the principles behind building LLM-based agents. Finally, we provide a survey of tools for prompt engineers.
5/7/2024
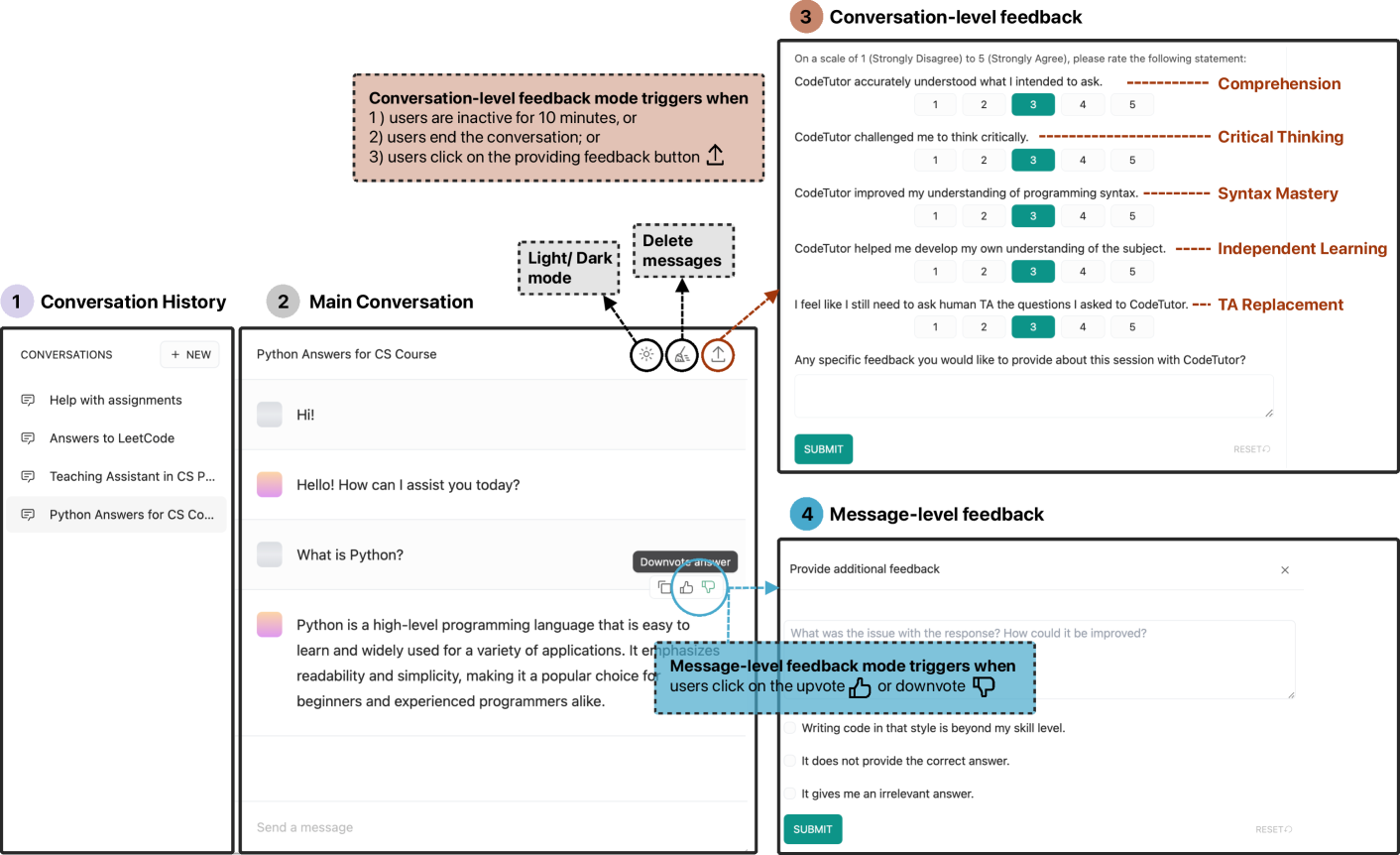
Evaluating the Effectiveness of LLMs in Introductory Computer Science Education: A Semester-Long Field Study
Wenhan Lyu (Rachel), Yimeng Wang (Rachel), Tingting (Rachel), Chung, Yifan Sun, Yixuan Zhang
0
0
The integration of AI assistants, especially through the development of Large Language Models (LLMs), into computer science education has sparked significant debate. An emerging body of work has looked into using LLMs in education, but few have examined the impacts of LLMs on students in entry-level programming courses, particularly in real-world contexts and over extended periods. To address this research gap, we conducted a semester-long, between-subjects study with 50 students using CodeTutor, an LLM-powered assistant developed by our research team. Our study results show that students who used CodeTutor (the experimental group) achieved statistically significant improvements in their final scores compared to peers who did not use the tool (the control group). Within the experimental group, those without prior experience with LLM-powered tools demonstrated significantly greater performance gain than their counterparts. We also found that students expressed positive feedback regarding CodeTutor's capability, though they also had concerns about CodeTutor's limited role in developing critical thinking skills. Over the semester, students' agreement with CodeTutor's suggestions decreased, with a growing preference for support from traditional human teaching assistants. Our analysis further reveals that the quality of user prompts was significantly correlated with CodeTutor's response effectiveness. Building upon our results, we discuss the implications of our findings for integrating Generative AI literacy into curricula to foster critical thinking skills and turn to examining the temporal dynamics of user engagement with LLM-powered tools. We further discuss the discrepancy between the anticipated functions of tools and students' actual capabilities, which sheds light on the need for tailored strategies to improve educational outcomes.
5/6/2024

Can Large Language Models Automatically Score Proficiency of Written Essays?
Watheq Mansour, Salam Albatarni, Sohaila Eltanbouly, Tamer Elsayed
0
0
Although several methods were proposed to address the problem of automated essay scoring (AES) in the last 50 years, there is still much to desire in terms of effectiveness. Large Language Models (LLMs) are transformer-based models that demonstrate extraordinary capabilities on various tasks. In this paper, we test the ability of LLMs, given their powerful linguistic knowledge, to analyze and effectively score written essays. We experimented with two popular LLMs, namely ChatGPT and Llama. We aim to check if these models can do this task and, if so, how their performance is positioned among the state-of-the-art (SOTA) models across two levels, holistically and per individual writing trait. We utilized prompt-engineering tactics in designing four different prompts to bring their maximum potential to this task. Our experiments conducted on the ASAP dataset revealed several interesting observations. First, choosing the right prompt depends highly on the model and nature of the task. Second, the two LLMs exhibited comparable average performance in AES, with a slight advantage for ChatGPT. Finally, despite the performance gap between the two LLMs and SOTA models in terms of predictions, they provide feedback to enhance the quality of the essays, which can potentially help both teachers and students.
4/17/2024