Decision Mamba: Reinforcement Learning via Sequence Modeling with Selective State Spaces
2403.19925
0
0
Abstract
Decision Transformer, a promising approach that applies Transformer architectures to reinforcement learning, relies on causal self-attention to model sequences of states, actions, and rewards. While this method has shown competitive results, this paper investigates the integration of the Mamba framework, known for its advanced capabilities in efficient and effective sequence modeling, into the Decision Transformer architecture, focusing on the potential performance enhancements in sequential decision-making tasks. Our study systematically evaluates this integration by conducting a series of experiments across various decision-making environments, comparing the modified Decision Transformer, Decision Mamba, with its traditional counterpart. This work contributes to the advancement of sequential decision-making models, suggesting that the architecture and training methodology of neural networks can significantly impact their performance in complex tasks, and highlighting the potential of Mamba as a valuable tool for improving the efficacy of Transformer-based models in reinforcement learning scenarios.
Create account to get full access
Introduction
The paper explores the integration of the Mamba framework, a novel sequence modeling architecture, into the Decision Transformer model for reinforcement learning. Decision Transformer introduced a paradigm shift by replacing traditional reinforcement learning's reliance on value functions with a direct mapping of state-action-reward sequences to optimal actions using causal self-attention mechanisms.
While causal self-attention has been instrumental in achieving remarkable results, the paper investigates the potential performance improvements that could be gained by substituting the Mamba framework for the causal self-attention mechanism within the Decision Transformer model. Mamba introduces a data-dependent selection mechanism and efficient hardware-aware design to address the data- and time-invariant issues of prior state space models.
The paper hypothesizes that Mamba's architecture design could offer a novel way to encode and exploit the temporal dependencies and intricate patterns present in sequential decision-making tasks, potentially resulting in more accurate, robust, and nuanced decision-making outputs. The primary focus of the paper is on the possible performance gains that Mamba's architecture design might confer on the Decision Transformer's sequence modeling capabilities, rather than solely on efficiency considerations.
By examining the performance implications of integrating Mamba into Decision Transformer, the work aims to contribute to the broader discourse on how best to architect and train models for the nuanced demands of sequential decision-making, offering potential pathways to significant advancements in the field of reinforcement learning.
Preliminaries
This section provides an overview of offline reinforcement learning (RL) and state space models (SSMs) in deep learning.
In offline RL, also known as batch RL, the agent learns from a fixed dataset without interacting with the environment, which is more challenging than online RL. One approach is behavior cloning (BC), which learns the mapping from states to actions directly from the dataset. However, the offline dataset often lacks sufficient expert demonstrations, so return-conditioned BC can be used to incorporate reward information and target future returns.
Decision Transformer (DT) is a promising approach that reconceptualizes RL as a sequence modeling task, taking a sequence of returns-to-go, states, and actions as input and autoregressively learning to predict the optimal action for a given target return.
SSMs in deep learning are a class of sequence modeling frameworks based on linear ordinary differential equations. They map an input signal to an output signal via a latent state. The discretized SSM can be expressed as a sequence-to-sequence mapping, and imposing structural conditions on the state matrix gives rise to the structured state space model (S4). Mamba builds upon the S4 framework, introducing a data-dependent selection mechanism and a hardware-aware parallel algorithm to effectively capture contextual information, especially for long sequences, while maintaining computational efficiency.
Decision Mamba
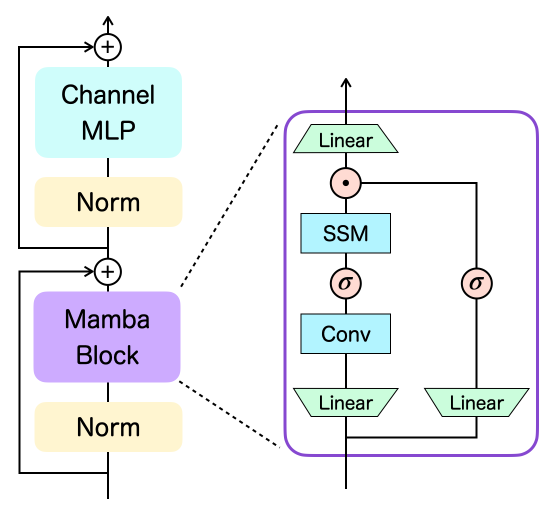
Decision Mamba (DMamba) utilizes the Mamba block as a token-mixing module instead of the self-attention module of Transformer networks. The paper provides an overview of the DMamba architecture, describing it as a variant of Transformer-type networks.
The network architecture of DMamba adopts the basic Transformer-type neural network, similar to GPT architectures. The main module, the Mamba layer, consists of a token-mixing layer and a channel-mixing layer. These layers include layer normalization, residual connections, and corresponding mixing blocks.
The input trajectory is transformed into token embeddings by an embedding layer, which can be a linear layer or a 2D convolutional layer depending on the environment. These token embeddings are then processed by a stack of Mamba layers.
The Mamba block operates linear projections to obtain hidden states, which are transformed using a SiLU activation function. This produces the core of the block, the selective state-space model (SSM). The output is then generated by applying another linear and SiLU functions.
During training, the model is trained on a dataset of offline trajectories. Sub-trajectories of length 3K are sampled, and the model predicts the next action given the current state and return-to-go (RTG). The loss function depends on the environment, using either mean squared error for continuous actions or cross-entropy loss for discrete actions.
In the inference phase, the model receives a current trajectory and generates an action. The next state and reward are then used to update the RTG for the previous timestep.
Experiments
The paper compares the effectiveness of the DMamba sequence modeling framework for reinforcement learning (RL) against various DT variants, including the original DT, Decision S4 (DS4), and Decision ConvFormer (DC). The experiments were conducted on continuous OpenAI Gym tasks and discrete Atari control tasks.
For the OpenAI Gym tasks, the results show that DMamba performs comparably to the other methods across various medium-quality and medium-expert datasets. An ablation study on the channel-mixing layers in DMamba indicates that the core Mamba block is sufficient for RL sequence modeling tasks within the given scope.
In the Atari domain, which poses challenges due to long-term credit assignment, the paper examines the effect of the context length K in DMamba. The results suggest that longer context lengths can improve performance on Breakout but degrade it on Qbert, potentially indicating limitations in the Mamba block's selection mechanism for certain tasks.
Overall, the paper provides a comprehensive evaluation of DMamba against state-of-the-art sequence modeling approaches for RL, highlighting its competitive performance and the role of the core Mamba block and context length in different task domains.
Conclusion and Discussion
The paper examines the capabilities of the recently proposed Mamba model for sequence modeling in reinforcement learning (RL). It introduces the Decision Mamba (DMamba) model, which incorporates the Mamba block based on the selective SSM into a DT-type neural network architecture. The empirical study shows that DMamba is competitive with existing DT-type models, suggesting the effectiveness of Mamba for RL tasks.
However, the paper notes that merely applying the Mamba block to DT-type networks does not enhance efficiency due to the numerous interactions between CPUs and GPUs for the RL tasks considered. The paper adheres to the DT experimental setup for fair comparison but suggests reconsidering the implementation to leverage Mamba's advantages efficiently.
Another limitation is the absence of a hyperparameter search and an analysis of how to use the Mamba block more effectively to reflect the data structure of RL tasks. The paper proposes adapting the network architecture to better suit the RL data structure or preprocessing trajectory datasets into a format more compatible with Mamba. Applying Mamba to non-Markov decision processes is also suggested as a future direction.
The paper concludes that a comprehensive study with an exploration of improved Transformer-type network architectures for RL will be released elsewhere.
Appendix A Implementation Details of DMamba
The provided section describes the implementation details of the Mamba layer and the hyperparameters used for the experiments on the OpenAI Gym and Atari domains.
For the Mamba layer, the key aspects are:
- It is implemented using the Mamba module, as shown in the provided pseudo-code.
- The Mamba layer is incorporated into a Block module that also includes layer normalization and an MLP-based channel transformation.
For the OpenAI Gym tasks:
- The hyperparameters are adopted from previous studies, with some adaptations for each dataset.
- Key hyperparameters include the number of layers, batch size, context length, return-to-go conditioning, dropout, nonlinearity function, gradient norm clipping, and learning rate decay.
For the Atari domain:
- The hyperparameters also follow previous work, with specific values for different Atari games.
- Hyperparameters include the number of layers, embedding dimension, batch size, context length, return-to-go conditioning, nonlinearity functions, maximum epochs, dropout, learning rate, and learning rate decay.
The full set of code for the experiments is available in the provided GitHub repository.
Appendix B Task Scores and Normalization
The provided text describes the formula used to calculate the normalized scores for each domain. The normalized score is calculated as 100 times the raw score minus the random score, divided by the expert score minus the random score.
For OpenAI Gym tasks, the protocol from Fu et al. (2020) is used. For Atari games, the raw and baseline scores are provided in Table 7, which are used for normalization as described in Ye et al. (2021), Table 1. The column of DMamba in Table 7 shows the raw scores corresponding to Table 2 in the main text.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
Mamba as Decision Maker: Exploring Multi-scale Sequence Modeling in Offline Reinforcement Learning
Jiahang Cao, Qiang Zhang, Ziqing Wang, Jiaxu Wang, Hao Cheng, Yecheng Shao, Wen Zhao, Gang Han, Yijie Guo, Renjing Xu
0
0
Sequential modeling has demonstrated remarkable capabilities in offline reinforcement learning (RL), with Decision Transformer (DT) being one of the most notable representatives, achieving significant success. However, RL trajectories possess unique properties to be distinguished from the conventional sequence (e.g., text or audio): (1) local correlation, where the next states in RL are theoretically determined solely by current states and actions based on the Markov Decision Process (MDP), and (2) global correlation, where each step's features are related to long-term historical information due to the time-continuous nature of trajectories. In this paper, we propose a novel action sequence predictor, named Mamba Decision Maker (MambaDM), where Mamba is expected to be a promising alternative for sequence modeling paradigms, owing to its efficient modeling of multi-scale dependencies. In particular, we introduce a novel mixer module that proficiently extracts and integrates both global and local features of the input sequence, effectively capturing interrelationships in RL datasets. Extensive experiments demonstrate that MambaDM achieves state-of-the-art performance in Atari and OpenAI Gym datasets. Furthermore, we empirically investigate the scaling laws of MambaDM, finding that increasing model size does not bring performance improvement, but scaling the dataset amount by 2x for MambaDM can obtain up to 33.7% score improvement on Atari dataset. This paper delves into the sequence modeling capabilities of MambaDM in the RL domain, paving the way for future advancements in robust and efficient decision-making systems. Our code will be available at https://github.com/AndyCao1125/MambaDM.
6/5/2024

Decision Mamba: Reinforcement Learning via Hybrid Selective Sequence Modeling
Sili Huang, Jifeng Hu, Zhejian Yang, Liwei Yang, Tao Luo, Hechang Chen, Lichao Sun, Bo Yang
0
0
Recent works have shown the remarkable superiority of transformer models in reinforcement learning (RL), where the decision-making problem is formulated as sequential generation. Transformer-based agents could emerge with self-improvement in online environments by providing task contexts, such as multiple trajectories, called in-context RL. However, due to the quadratic computation complexity of attention in transformers, current in-context RL methods suffer from huge computational costs as the task horizon increases. In contrast, the Mamba model is renowned for its efficient ability to process long-term dependencies, which provides an opportunity for in-context RL to solve tasks that require long-term memory. To this end, we first implement Decision Mamba (DM) by replacing the backbone of Decision Transformer (DT). Then, we propose a Decision Mamba-Hybrid (DM-H) with the merits of transformers and Mamba in high-quality prediction and long-term memory. Specifically, DM-H first generates high-value sub-goals from long-term memory through the Mamba model. Then, we use sub-goals to prompt the transformer, establishing high-quality predictions. Experimental results demonstrate that DM-H achieves state-of-the-art in long and short-term tasks, such as D4RL, Grid World, and Tmaze benchmarks. Regarding efficiency, the online testing of DM-H in the long-term task is 28$times$ times faster than the transformer-based baselines.
6/4/2024

Decision Mamba: A Multi-Grained State Space Model with Self-Evolution Regularization for Offline RL
Qi Lv, Xiang Deng, Gongwei Chen, Michael Yu Wang, Liqiang Nie
0
0
While the conditional sequence modeling with the transformer architecture has demonstrated its effectiveness in dealing with offline reinforcement learning (RL) tasks, it is struggle to handle out-of-distribution states and actions. Existing work attempts to address this issue by data augmentation with the learned policy or adding extra constraints with the value-based RL algorithm. However, these studies still fail to overcome the following challenges: (1) insufficiently utilizing the historical temporal information among inter-steps, (2) overlooking the local intrastep relationships among states, actions and return-to-gos (RTGs), (3) overfitting suboptimal trajectories with noisy labels. To address these challenges, we propose Decision Mamba (DM), a novel multi-grained state space model (SSM) with a self-evolving policy learning strategy. DM explicitly models the historical hidden state to extract the temporal information by using the mamba architecture. To capture the relationship among state-action-RTG triplets, a fine-grained SSM module is designed and integrated into the original coarse-grained SSM in mamba, resulting in a novel mamba architecture tailored for offline RL. Finally, to mitigate the overfitting issue on noisy trajectories, a self-evolving policy is proposed by using progressive regularization. The policy evolves by using its own past knowledge to refine the suboptimal actions, thus enhancing its robustness on noisy demonstrations. Extensive experiments on various tasks show that DM outperforms other baselines substantially.
6/11/2024
🤷
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Albert Gu, Tri Dao
0
0
Foundation models, now powering most of the exciting applications in deep learning, are almost universally based on the Transformer architecture and its core attention module. Many subquadratic-time architectures such as linear attention, gated convolution and recurrent models, and structured state space models (SSMs) have been developed to address Transformers' computational inefficiency on long sequences, but they have not performed as well as attention on important modalities such as language. We identify that a key weakness of such models is their inability to perform content-based reasoning, and make several improvements. First, simply letting the SSM parameters be functions of the input addresses their weakness with discrete modalities, allowing the model to selectively propagate or forget information along the sequence length dimension depending on the current token. Second, even though this change prevents the use of efficient convolutions, we design a hardware-aware parallel algorithm in recurrent mode. We integrate these selective SSMs into a simplified end-to-end neural network architecture without attention or even MLP blocks (Mamba). Mamba enjoys fast inference (5$times$ higher throughput than Transformers) and linear scaling in sequence length, and its performance improves on real data up to million-length sequences. As a general sequence model backbone, Mamba achieves state-of-the-art performance across several modalities such as language, audio, and genomics. On language modeling, our Mamba-3B model outperforms Transformers of the same size and matches Transformers twice its size, both in pretraining and downstream evaluation.
6/3/2024