Decoding Decision Reasoning: A Counterfactual-Powered Model for Knowledge Discovery
2406.18552
0
0
📈
Abstract
In medical imaging, particularly in early disease detection and prognosis tasks, discerning the rationale behind an AI model's predictions is crucial for evaluating the reliability of its decisions. Conventional explanation methods face challenges in identifying discernible decisive features in medical image classifications, where discriminative features are subtle or not immediately apparent. To bridge this gap, we propose an explainable model that is equipped with both decision reasoning and feature identification capabilities. Our approach not only detects influential image patterns but also uncovers the decisive features that drive the model's final predictions. By implementing our method, we can efficiently identify and visualise class-specific features leveraged by the data-driven model, providing insights into the decision-making processes of deep learning models. We validated our model in the demanding realm of medical prognosis task, demonstrating its efficacy and potential in enhancing the reliability of AI in healthcare and in discovering new knowledge in diseases where prognostic understanding is limited.
Create account to get full access
Overview
- Explains a new explainable AI model for medical image classification
- Aims to identify the key features that drive the model's predictions, providing interpretability
- Validated the model on a medical prognosis task, demonstrating its potential to enhance AI reliability in healthcare
Plain English Explanation
Our proposed explainable AI model is designed to provide insights into the decision-making process of deep learning models used for medical image analysis. In conventional AI models, it can be challenging to understand the specific features that are driving the model's predictions, especially when the discriminative features are subtle.
To address this, our approach not only detects influential image patterns, but also uncovers the decisive features that are responsible for the model's final predictions. By implementing this method, we can efficiently identify and visualize the class-specific features that the data-driven model is leveraging, giving us a better understanding of how the model is making its decisions.
We tested our explainable AI model on a medical prognosis task, where accurately predicting disease outcomes is critical. The model was able to provide clear explanations for its predictions, highlighting the key visual cues it was using. This can help build trust in AI systems and enable healthcare professionals to better understand the rationale behind the model's decisions, ultimately improving the reliability of AI in medical applications.
Technical Explanation
The core of our approach is an explainable AI model that combines decision reasoning and feature identification capabilities. Unlike conventional explanation methods, which can struggle to identify discernible decisive features in medical image classifications, our model is designed to overcome this challenge.
The model works by first detecting influential image patterns that contribute to the final predictions. It then uncovers the specific features within those patterns that are driving the model's decision-making process. This allows the model to not only identify the relevant regions of the image, but also explain why those regions are important.
We validated the performance of our explainable AI model on a medical prognosis task, where accurately predicting disease outcomes is crucial. The results demonstrated the model's ability to provide clear and interpretable explanations for its predictions, highlighting the key visual cues it was using. This can help build trust in AI systems and enable healthcare professionals to better understand the rationale behind the model's decisions, ultimately improving the reliability of AI in medical applications.
Critical Analysis
The research presented in this paper offers a promising approach to enhancing the interpretability of deep learning models in medical image analysis. By combining decision reasoning and feature identification capabilities, the proposed explainable AI model can provide valuable insights into the decision-making process of these models.
However, it's important to note that the model's performance was only validated on a single medical prognosis task. Further research is needed to assess the generalizability of the approach across a wider range of medical imaging tasks and datasets. Additionally, the paper does not address the potential computational or memory overhead associated with the additional explanatory components of the model.
While the research demonstrates the potential benefits of explainable AI in healthcare, it's crucial to continue exploring ways to strike a balance between model interpretability and performance. As AI systems become more widely deployed in medical settings, maintaining a high level of trust and transparency will be essential for their successful integration and adoption.
Conclusion
The proposed explainable AI model represents a significant step forward in addressing the interpretability challenges faced by deep learning models in medical image analysis. By providing both decision reasoning and feature identification capabilities, the model can help build trust in AI systems and enable healthcare professionals to better understand the rationale behind the model's predictions.
The successful validation of the model on a medical prognosis task suggests its potential to enhance the reliability of AI in healthcare and potentially uncover new insights into disease prognostic factors. As the field of explainable AI continues to evolve, this research highlights the importance of developing interpretable models that can bridge the gap between the black-box nature of deep learning and the need for transparency in high-stakes domains like medicine.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
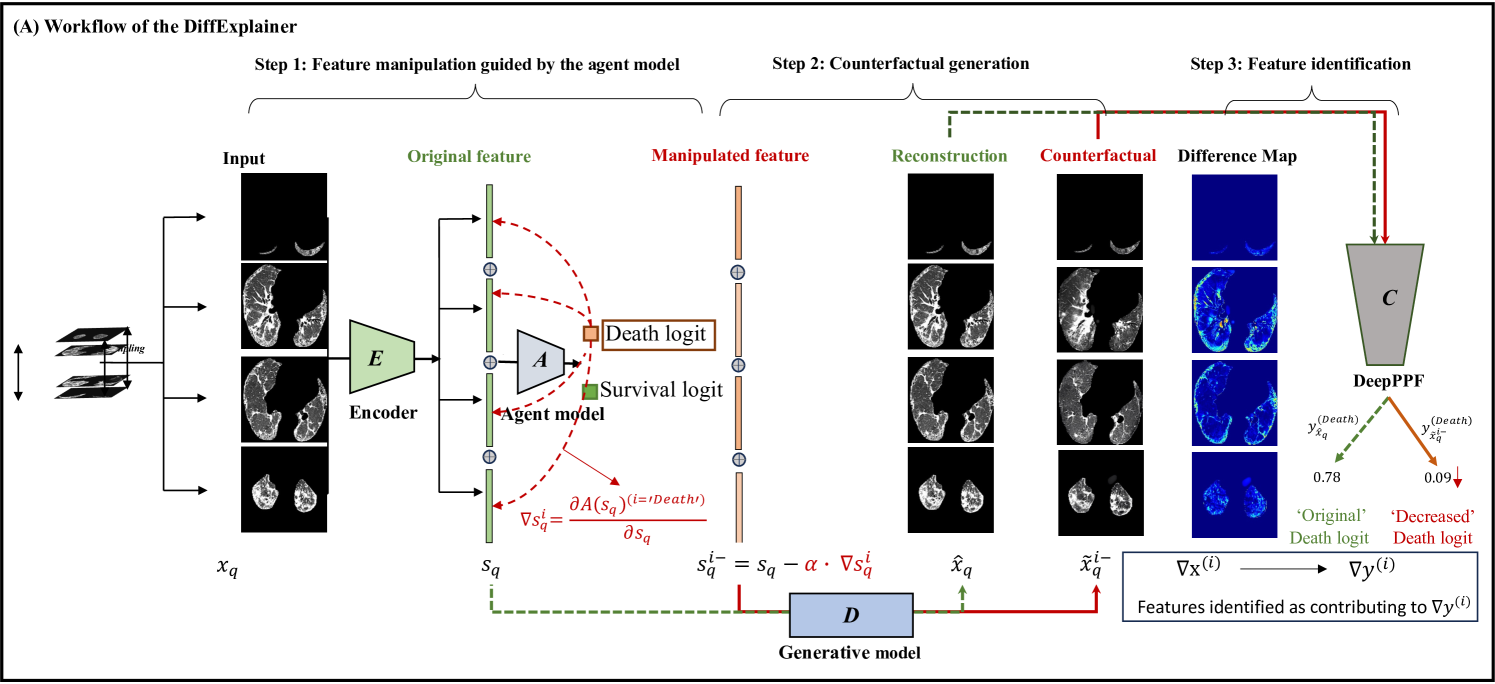
DiffExplainer: Unveiling Black Box Models Via Counterfactual Generation
Yingying Fang, Shuang Wu, Zihao Jin, Caiwen Xu, Shiyi Wang, Simon Walsh, Guang Yang
0
0
In the field of medical imaging, particularly in tasks related to early disease detection and prognosis, understanding the reasoning behind AI model predictions is imperative for assessing their reliability. Conventional explanation methods encounter challenges in identifying decisive features in medical image classifications, especially when discriminative features are subtle or not immediately evident. To address this limitation, we propose an agent model capable of generating counterfactual images that prompt different decisions when plugged into a black box model. By employing this agent model, we can uncover influential image patterns that impact the black model's final predictions. Through our methodology, we efficiently identify features that influence decisions of the deep black box. We validated our approach in the rigorous domain of medical prognosis tasks, showcasing its efficacy and potential to enhance the reliability of deep learning models in medical image classification compared to existing interpretation methods. The code will be publicly available at https://github.com/ayanglab/DiffExplainer.
6/28/2024
💬
Viewing the process of generating counterfactuals as a source of knowledge: a new approach for explaining classifiers
Vincent Lemaire, Nathan Le Boudec, Victor Guyomard, Franc{c}oise Fessant
0
0
There are now many explainable AI methods for understanding the decisions of a machine learning model. Among these are those based on counterfactual reasoning, which involve simulating features changes and observing the impact on the prediction. This article proposes to view this simulation process as a source of creating a certain amount of knowledge that can be stored to be used, later, in different ways. This process is illustrated in the additive model and, more specifically, in the case of the naive Bayes classifier, whose interesting properties for this purpose are shown.
4/15/2024
🖼️
MiMICRI: Towards Domain-centered Counterfactual Explanations of Cardiovascular Image Classification Models
Grace Guo, Lifu Deng, Animesh Tandon, Alex Endert, Bum Chul Kwon
0
0
The recent prevalence of publicly accessible, large medical imaging datasets has led to a proliferation of artificial intelligence (AI) models for cardiovascular image classification and analysis. At the same time, the potentially significant impacts of these models have motivated the development of a range of explainable AI (XAI) methods that aim to explain model predictions given certain image inputs. However, many of these methods are not developed or evaluated with domain experts, and explanations are not contextualized in terms of medical expertise or domain knowledge. In this paper, we propose a novel framework and python library, MiMICRI, that provides domain-centered counterfactual explanations of cardiovascular image classification models. MiMICRI helps users interactively select and replace segments of medical images that correspond to morphological structures. From the counterfactuals generated, users can then assess the influence of each segment on model predictions, and validate the model against known medical facts. We evaluate this library with two medical experts. Our evaluation demonstrates that a domain-centered XAI approach can enhance the interpretability of model explanations, and help experts reason about models in terms of relevant domain knowledge. However, concerns were also surfaced about the clinical plausibility of the counterfactuals generated. We conclude with a discussion on the generalizability and trustworthiness of the MiMICRI framework, as well as the implications of our findings on the development of domain-centered XAI methods for model interpretability in healthcare contexts.
4/26/2024
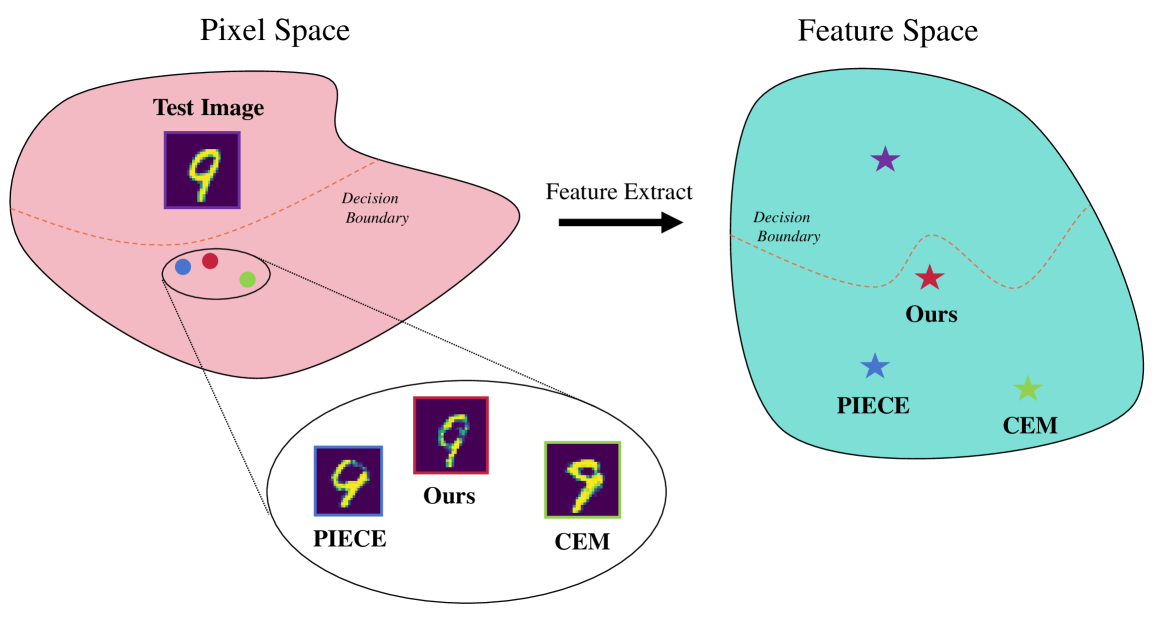
Enhancing Counterfactual Image Generation Using Mahalanobis Distance with Distribution Preferences in Feature Space
Yukai Zhang, Ao Xu, Zihao Li, Tieru Wu
0
0
In the realm of Artificial Intelligence (AI), the importance of Explainable Artificial Intelligence (XAI) is increasingly recognized, particularly as AI models become more integral to our lives. One notable single-instance XAI approach is counterfactual explanation, which aids users in comprehending a model's decisions and offers guidance on altering these decisions. Specifically in the context of image classification models, effective image counterfactual explanations can significantly enhance user understanding. This paper introduces a novel method for computing feature importance within the feature space of a black-box model. By employing information fusion techniques, our method maximizes the use of data to address feature counterfactual explanations in the feature space. Subsequently, we utilize an image generation model to transform these feature counterfactual explanations into image counterfactual explanations. Our experiments demonstrate that the counterfactual explanations generated by our method closely resemble the original images in both pixel and feature spaces. Additionally, our method outperforms established baselines, achieving impressive experimental results.
6/3/2024