Deep Reinforcement Learning for Traveling Purchaser Problems
2404.02476
0
0
Abstract
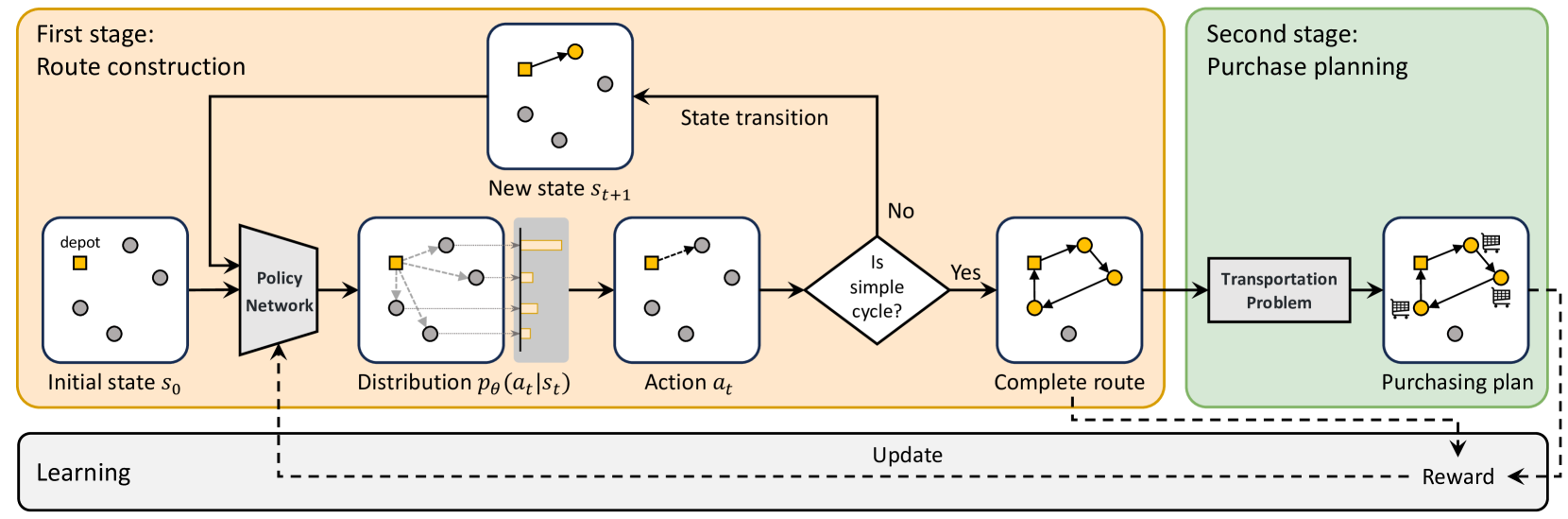
The traveling purchaser problem (TPP) is an important combinatorial optimization problem with broad applications. Due to the coupling between routing and purchasing, existing works on TPPs commonly address route construction and purchase planning simultaneously, which, however, leads to exact methods with high computational cost and heuristics with sophisticated design but limited performance. In sharp contrast, we propose a novel approach based on deep reinforcement learning (DRL), which addresses route construction and purchase planning separately, while evaluating and optimizing the solution from a global perspective. The key components of our approach include a bipartite graph representation for TPPs to capture the market-product relations, and a policy network that extracts information from the bipartite graph and uses it to sequentially construct the route. One significant benefit of our framework is that we can efficiently construct the route using the policy network, and once the route is determined, the associated purchasing plan can be easily derived through linear programming, while, leveraging DRL, we can train the policy network to optimize the global solution objective. Furthermore, by introducing a meta-learning strategy, the policy network can be trained stably on large-sized TPP instances, and generalize well across instances of varying sizes and distributions, even to much larger instances that are never seen during training. Experiments on various synthetic TPP instances and the TPPLIB benchmark demonstrate that our DRL-based approach can significantly outperform well-established TPP heuristics, reducing the optimality gap by 40%-90%, and also showing an advantage in runtime, especially on large-sized instances.
Create account to get full access
Overview
- Introduces a novel framework called "Solve Separately, Learn Globally" for solving complex optimization problems in a hierarchical and distributed manner
- Applies this framework to the task-priority intermediated hierarchical distributed policies (TPIHDP) problem in reinforcement learning
- Proposes an efficient algorithm for learning TPIHDP policies that leverages the structure of the problem
Plain English Explanation
The paper presents a new approach for solving complex optimization problems, particularly in the context of reinforcement learning. The core idea is to break down the problem into smaller, more manageable sub-problems that can be solved independently, and then to learn a global policy that coordinates the solutions of these sub-problems.
This is achieved through a framework called "Solve Separately, Learn Globally", where the original problem is first decomposed into a hierarchy of sub-problems. Each sub-problem is then solved using a specialized algorithm, and the solutions are then combined to form a global policy. The key advantage of this approach is that it allows for efficient and scalable optimization of complex problems by leveraging the structure of the problem.
The paper applies this framework to the task-priority intermediated hierarchical distributed policies (TPIHDP) problem in reinforcement learning. TPIHDP is a type of hierarchical reinforcement learning problem where an agent needs to learn a policy that can effectively coordinate the execution of multiple tasks with different priorities. The authors propose an efficient algorithm for learning TPIHDP policies that takes advantage of the hierarchical structure of the problem.
Technical Explanation
The paper introduces a novel framework called "Solve Separately, Learn Globally" for solving complex optimization problems in a hierarchical and distributed manner. The key idea is to decompose the original problem into a hierarchy of sub-problems, solve each sub-problem independently using specialized algorithms, and then learn a global policy that coordinates the solutions of these sub-problems.
The authors apply this framework to the task-priority intermediated hierarchical distributed policies (TPIHDP) problem in reinforcement learning. TPIHDP is a type of hierarchical reinforcement learning problem where an agent needs to learn a policy that can effectively coordinate the execution of multiple tasks with different priorities. The authors propose an efficient algorithm for learning TPIHDP policies that leverages the hierarchical structure of the problem.
The algorithm consists of two main steps: 1) solving each sub-problem independently using specialized algorithms, and 2) learning a global policy that coordinates the solutions of these sub-problems. The global policy is represented as a neural network and is trained using a combination of supervised learning and reinforcement learning.
The authors evaluate their approach on a range of benchmark problems and show that it outperforms existing methods for learning TPIHDP policies. They also provide theoretical analysis to characterize the performance of their algorithm and its convergence properties.
Critical Analysis
The paper presents an interesting and promising approach for solving complex optimization problems, particularly in the context of reinforcement learning. The "Solve Separately, Learn Globally" framework is a novel and well-designed methodology that leverages the structure of the problem to achieve efficient and scalable optimization.
One potential limitation of the proposed approach is that the performance of the global policy learning step may be sensitive to the quality of the sub-problem solutions. If the sub-problems are not solved accurately, the global policy may not be able to effectively coordinate their solutions. The authors acknowledge this issue and suggest that further research is needed to address it.
Additionally, the paper focuses primarily on the TPIHDP problem in reinforcement learning, which is a specific type of hierarchical reinforcement learning problem. While the authors demonstrate the effectiveness of their approach on this problem, it would be interesting to see how it can be extended to other types of complex optimization problems, both in reinforcement learning and beyond.
Overall, the paper presents a valuable contribution to the field of optimization and reinforcement learning, and the "Solve Separately, Learn Globally" framework is a promising direction for further research and development.
Conclusion
The paper introduces a novel framework called "Solve Separately, Learn Globally" for solving complex optimization problems in a hierarchical and distributed manner. The authors apply this framework to the task-priority intermediated hierarchical distributed policies (TPIHDP) problem in reinforcement learning and propose an efficient algorithm for learning TPIHDP policies.
The key innovation of the paper is the "Solve Separately, Learn Globally" approach, which allows for the decomposition of complex problems into smaller, more manageable sub-problems that can be solved independently. The authors show that this approach can lead to efficient and scalable optimization, and they demonstrate its effectiveness on a range of benchmark problems.
Overall, the paper presents a valuable contribution to the field of optimization and reinforcement learning, and the "Solve Separately, Learn Globally" framework is a promising direction for further research and development. The authors have also identified several areas for future work, such as addressing the potential sensitivity of the global policy learning step to the quality of the sub-problem solutions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
Deep Reinforcement Learning for Mobile Robot Path Planning
Hao Liu, Yi Shen, Shuangjiang Yu, Zijun Gao, Tong Wu
0
0
Path planning is an important problem with the the applications in many aspects, such as video games, robotics etc. This paper proposes a novel method to address the problem of Deep Reinforcement Learning (DRL) based path planning for a mobile robot. We design DRL-based algorithms, including reward functions, and parameter optimization, to avoid time-consuming work in a 2D environment. We also designed an Two-way search hybrid A* algorithm to improve the quality of local path planning. We transferred the designed algorithm to a simple embedded environment to test the computational load of the algorithm when running on a mobile robot. Experiments show that when deployed on a robot platform, the DRL-based algorithm in this article can achieve better planning results and consume less computing resources.
4/11/2024
➖
Test-Time Augmentation for Traveling Salesperson Problem
Ryo Ishiyama, Takahiro Shirakawa, Seiichi Uchida, Shinnosuke Matsuo
0
0
We propose Test-Time Augmentation (TTA) as an effective technique for addressing combinatorial optimization problems, including the Traveling Salesperson Problem. In general, deep learning models possessing the property of invariance, where the output is uniquely determined regardless of the node indices, have been proposed to learn graph structures efficiently. In contrast, we interpret the permutation of node indices, which exchanges the elements of the distance matrix, as a TTA scheme. The results demonstrate that our method is capable of obtaining shorter solutions than the latest models. Furthermore, we show that the probability of finding a solution closer to an exact solution increases depending on the augmentation size.
5/9/2024
Learning Heuristics for Transit Network Design and Improvement with Deep Reinforcement Learning
Andrew Holliday, Ahmed El-Geneidy, Gregory Dudek
0
0
Transit agencies world-wide face tightening budgets. To maintain quality of service while cutting costs, efficient transit network design is essential. But planning a network of public transit routes is a challenging optimization problem. The most successful approaches to date use metaheuristic algorithms to search through the space of possible transit networks by applying low-level heuristics that randomly alter routes in a network. The design of these low-level heuristics has a major impact on the quality of the result. In this paper we use deep reinforcement learning with graph neural nets to learn low-level heuristics for an evolutionary algorithm, instead of designing them manually. These learned heuristics improve the algorithm's results on benchmark synthetic cities with 70 nodes or more, and obtain state-of-the-art results when optimizing operating costs. They also improve upon a simulation of the real transit network in the city of Laval, Canada, by as much as 54% and 18% on two key metrics, and offer cost savings of up to 12% over the city's existing transit network.
4/16/2024

New!Let Hybrid A* Path Planner Obey Traffic Rules: A Deep Reinforcement Learning-Based Planning Framework
Xibo Li, Shruti Patel, Christof Buskens
0
0
Deep reinforcement learning (DRL) allows a system to interact with its environment and take actions by training an efficient policy that maximizes self-defined rewards. In autonomous driving, it can be used as a strategy for high-level decision making, whereas low-level algorithms such as the hybrid A* path planning have proven their ability to solve the local trajectory planning problem. In this work, we combine these two methods where the DRL makes high-level decisions such as lane change commands. After obtaining the lane change command, the hybrid A* planner is able to generate a collision-free trajectory to be executed by a model predictive controller (MPC). In addition, the DRL algorithm is able to keep the lane change command consistent within a chosen time-period. Traffic rules are implemented using linear temporal logic (LTL), which is then utilized as a reward function in DRL. Furthermore, we validate the proposed method on a real system to demonstrate its feasibility from simulation to implementation on real hardware.
7/2/2024